
Large Language Models (LLMs) have changed the world. However, generating text with them can be slow and expensive. While methods like speculative decoding have been proposed to accelerate the generation speed, their intricate nature has left many in the open-source community hesitant to embrace them.
That's why we're thrilled to unveil Medusa: a simpler, more user-friendly framework for accelerating LLM generation. Instead of using an additional draft model like speculative decoding, Medusa merely introduces a few additional decoding heads, following the idea of [Stern et al. 2018] with some other ingredients. Despite its simple design, Medusa can improve the generation efficiency of LLMs by about 2x.
In the following blog post, we'll explore the fundamental bottlenecks of LLM generation and some limitations of speculative decoding, then show how Medusa manages to tackle them and achieve acceleration.
The implementation is available at this repo.

Why is LLM Generation Inefficient?
From a systems perspective, LLM generation follows a memory-bound computational pattern with the main latency bottleneck arising from memory reads/writes rather than arithmetic computations. This issue is rooted in the inherently sequential nature of the auto-regressive decoding process. Each forward pass necessitates the transfer of the entire model's parameters from High-Bandwidth Memory (HBM) to the accelerator's compute units. This operation, while only producing a single token for each sample, fails to fully utilize the arithmetic computation capabilities of modern accelerators, resulting in inefficiency.
Before the rise of LLMs, a common mitigation for this inefficiency was to simply increase the batch size, enabling the parallel production of more tokens. But the situation becomes far more complicated with LLMs. Increasing the batch size in this context not only introduces higher latency but also substantially inflates the memory requirements for the Transformer model's key-value cache. This trade-off makes the use of large batches impractical for many applications where low latency is a critical requirement.
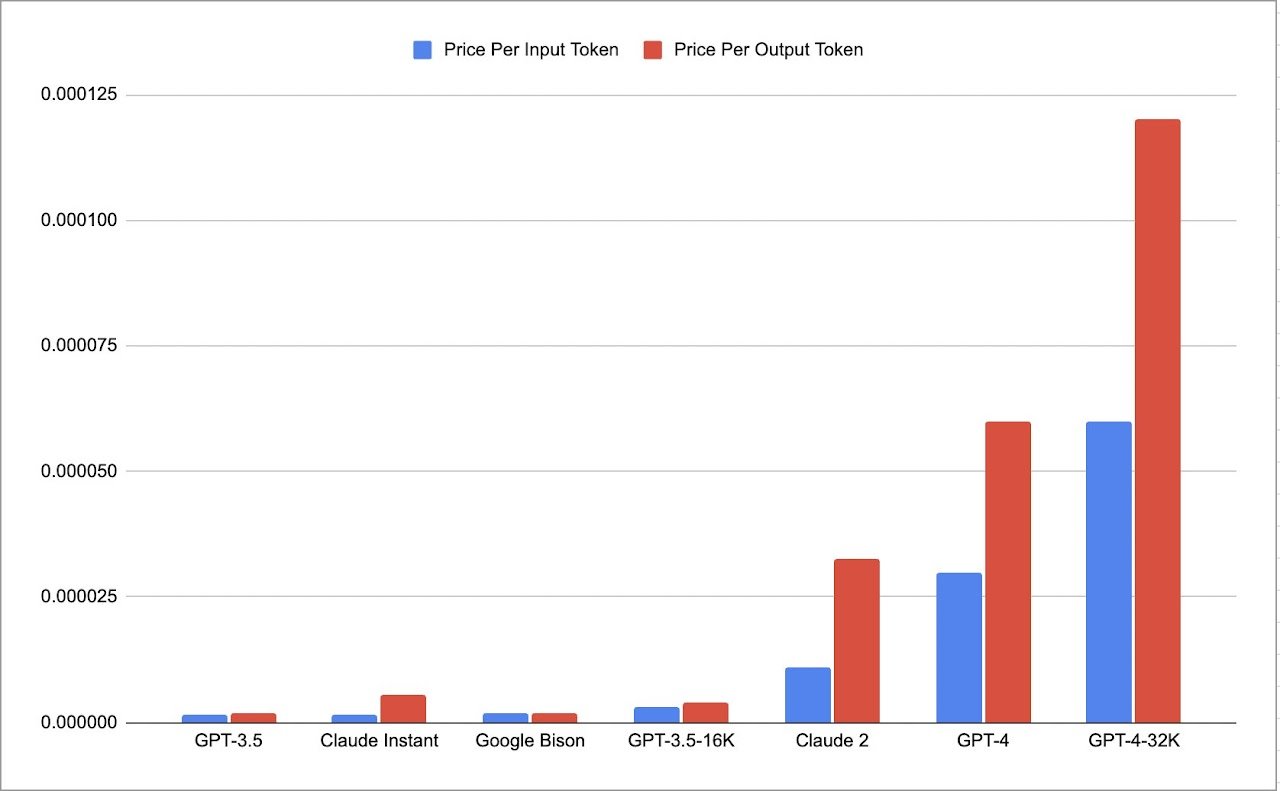
Moreover, this inefficiency is also reflected in cost structures. As of September 2023, generation costs approximately 2x higher for GPT-4 and roughly 3x for Claude 2, compared to merely processing prompts. We note the primary focus of this blog is on improving the latency of LLM generation, while we believe the techniques here can also be adapted to LLM serving, which requires balancing latency and throughput.
Is Speculative Decoding the Ultimate Solution?
Given the challenges outlined, one appealing strategy to accelerate text generation is more efficient computational utilization—specifically, by processing more tokens in parallel. This is precisely where speculative decoding comes into play. The methodology employs a streamlined "draft" model to generate a batch of token candidates at each step quickly. These candidates are then validated by the original, full-scale language model to identify the most reasonable text continuations. The underlying logic hinges on an intriguing assumption: the draft model, although smaller, should be proficient enough to churn out sequences that the original model will find acceptable.
If this assumption holds, the draft model can rapidly produce token sequences while the original model efficiently vets multiple tokens in parallel—thereby maximizing computational throughput. Recent research indicates that with a well-tuned draft model, speculative decoding can cut latency by an impressive factor of up to 2.5x.
However, the approach is not without its challenges:
- Finding the Ideal Draft Model: Identifying a "small yet mighty" draft model that aligns well with the original model is easier said than done.
- System Complexity: Hosting two distinct models in one system introduces layers of complexity, both computational and operational, especially in distributed settings.
- Sampling Inefficiency: When doing sampling with speculative decoding, an importance sampling scheme needs to be used. This introduces additional overhead on generation, especially at higher sampling temperatures.
These complexities and trade-offs have limited the broader adoption of speculative decoding techniques. So, while promising, speculative decoding isn't widely adopted.
Remark: We use speculative decoding to refer to those methods that require an independent draft model here. In a broader sense, our method can also be viewed as speculative decoding, while the draft model is entangled with the original model.
Medusa: Marrying Simplicity with Efficiency
When it comes to speculative decoding, its promise is counteracted by its inherent complexity. Recognizing the need for a more user-friendly yet potent solution, we proudly present Medusa. This innovative framework not only accelerates LLM generation but also makes LLM technology accessible and usable for a broader audience.
Our approach revisits an underrated gem from the paper "Blockwise Parallel Decoding for Deep Autoregressive Models" [Stern et al. 2018] back to the invention of the Transformer model: rather than pulling in an entirely new draft model to predict subsequent tokens, why not simply extend the original model itself? This is where the "Medusa heads" come in. These additional decoding heads seamlessly integrate with the original model, producing blocks of tokens at each generative juncture.
Unlike the draft model, Medusa heads can be trained in conjunction with the original model, which remains frozen during training. This method allows for fine-tuning large models on a single GPU, taking advantage of the powerful base model's learned representations. Additionally, since the new heads consist of just a single layer akin to the original language model head, Medusa does not add complexity to the serving system design and is friendly to distributed settings.
On its own, Medusa heads don't quite hit the mark of doubling processing speeds. But here's the twist: When we pair this with a tree-based attention mechanism, we can verify several candidates generated by Medusa heads in parallel. This way, the Medusa heads' predictive prowess truly shone through, offering a 2x to 3x boost in speed.
We didn't stop there, either. Eschewing the traditional importance sampling scheme, we created an efficient and high-quality alternative crafted specifically for the generation with Medusa heads. This new approach entirely sidesteps the sampling overhead, even adding an extra pep to Medusa's already accelerated step.
In a nutshell, we solve the challenges of speculative decoding with a simple system:
- No separate model: Instead of introducing a new draft model, we train multiple decoding heads on the same model.
- Simple integration to existing systems: The training is parameter-efficient so that even GPU poor can do it. And since there is no additional model, there is no need to adjust the distributed computing setup.
- Treat sampling as a relaxation: Relaxing the requirement of matching the distribution of the original model makes the non-greedy generation even faster than greedy decoding.
The figure below offers a visual breakdown of the Medusa pipeline for those curious about the nuts and bolts.
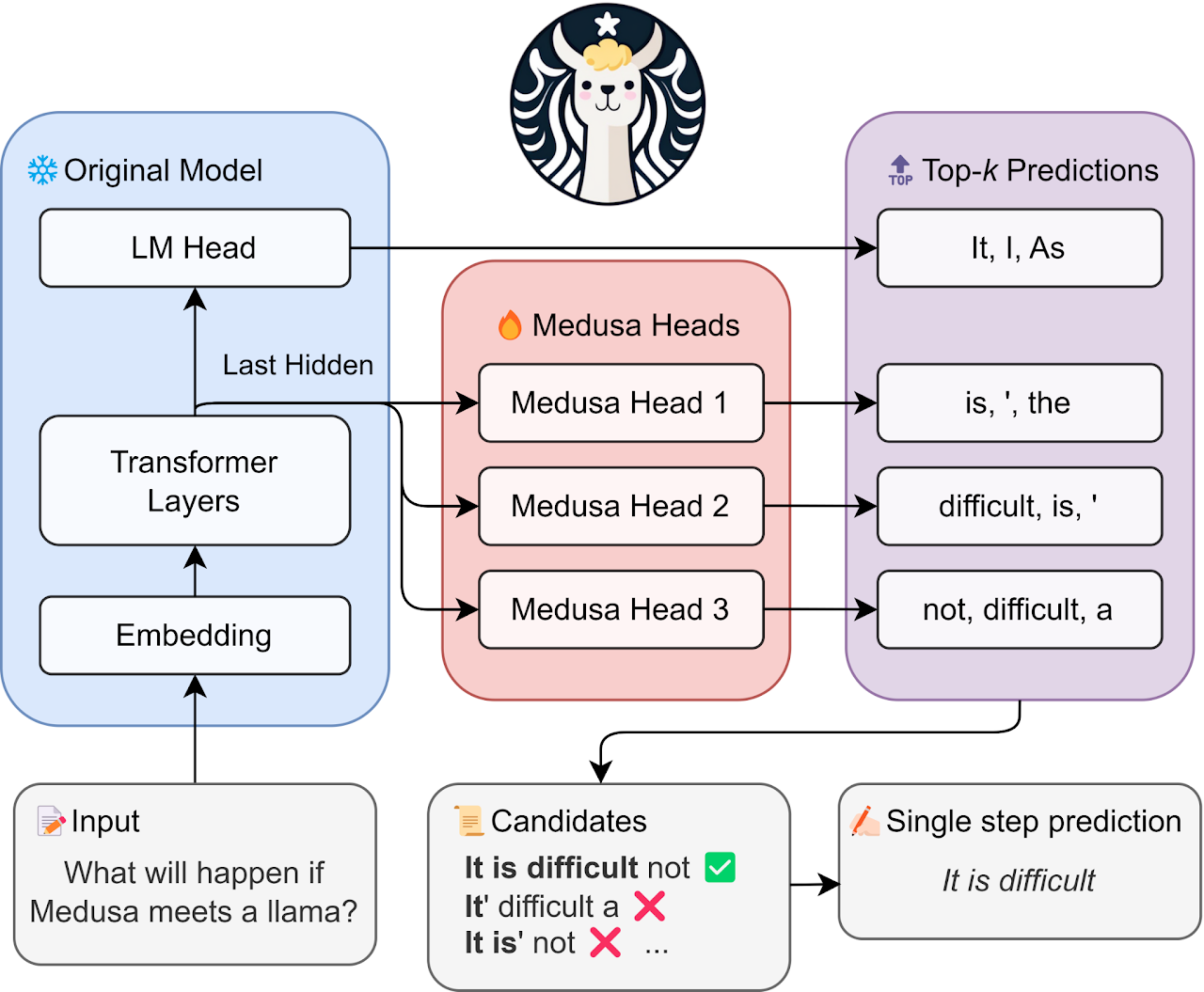
Overview of Medusa. Medusa introduces multiple heads on top of the last hidden states of the LLM, enabling the prediction of several subsequent tokens in parallel.
When augmenting a model with Medusa heads, the original model is frozen during training, and only the Medusa heads undergo fine-tuning. This approach makes it feasible to fine-tune large models on a single GPU.
During inference, each head generates multiple top predictions for its designated position. These predictions are assembled into candidates and processed in parallel using a tree-based attention mechanism. The final step involves utilizing a typical acceptance scheme to select reasonable continuations, and the longest accepted candidate prefix will be used for the next decoding phase.
The efficiency of the decoding process is enhanced by accepting more tokens simultaneously, thus reducing the number of required decoding steps.
Let's dive into the three components of Medusa: Medusa heads, tree attention, and typical acceptance scheme.
Medusa heads
So what exactly are Medusa heads? They're akin to the language model head in the original architecture (the last layer of a causal Transformer model), but with a twist: they predict multiple forthcoming tokens, not just the immediate next one. Drawing inspiration from the Blockwise Parallel Decoding approach, we implement each Medusa head as a single layer of feed-forward network, augmented with a residual connection.
Training these heads is remarkably straightforward. You can either use the same corpus that trained the original model or generate a new corpus using the model itself. Importantly, during this training phase, the original model remains static; only the Medusa heads are fine-tuned. This targeted training results in a highly parameter-efficient process that reaches convergence swiftly—especially when compared to the computational heaviness of training a separate draft model in speculative decoding methods.
The efficacy of Medusa heads is quite impressive. On the Vicuna models we test, Medusa heads achieve a top-1 accuracy rate of approximately 60% for predicting the 'next-next' token. Yet, there is still room for improvement.
Tree attention
During our tests, we uncovered some striking metrics: although the top-1 accuracy for predicting the 'next-next' token hovers around 60%, the top-5 accuracy soars to over 80%. This substantial increase indicates that if we can strategically leverage the multiple top-ranked predictions made by the Medusa heads, we can significantly amplify the number of tokens generated per decoding step.
With this goal, we first craft a set of candidates by taking the Cartesian product of the top predictions from each Medusa head. We then encode the dependency graph into the attention following the idea from graph neural networks so that we can process multiple candidates in parallel.
For example, let's consider a scenario where we use top-2 predictions from the first Medusa head and top-3 predictions from the second, as illustrated below. In this case, any prediction from the first head could be paired with any prediction from the second head, culminating in a multi-level tree structure. Each level of this tree corresponds to predictions from one of the Medusa heads. Within this tree, we implement an attention mask that restricts attention only to a token's predecessors, preserving the concept of historical context. By doing so and by setting positional indices for positional encoding accordingly, we can process a wide array of candidates simultaneously without needing to inflate the batch size.
We would also remark that a few independent works also adopt very similar ideas of tree attention [1, 2]. Compared with them, our methodology leans towards a simpler form of tree attention where the tree pattern is regular and fixed during inference, which enables a preprocessing of tree attention mask that further improves the efficiency.
Typical acceptance
In earlier research on speculative decoding, the technique of importance sampling was used to generate diverse outputs closely aligned with the original model's predictions. However, later studies showed that this method tends to become less efficient as you turn up the "creativity dial," known as the sampling temperature.
In simpler terms, if your draft model is just as good as your original model, you should ideally accept all its outputs, making the process super efficient. However, importance sampling will likely reject this solution in the middle.
In the real world, we often tweak the sampling temperature just to control the model's creativity, not necessarily to match the original model's distribution. So why not focus on just accepting plausible candidates?
We then introduce the typical acceptance scheme. Drawing inspiration from existing work on truncation sampling, we aim to pick candidates that are likely enough according to the original model. We set a threshold based on the original model's prediction probabilities, and if a candidate exceeds this, it's accepted.
In technical jargon, we take the minimum of a hard threshold and an entropy-dependent threshold to decide whether to accept a candidate as in truncation sampling. This ensures that meaningful tokens and reasonable continuations are chosen during decoding. We always accept the first token using greedy decoding, ensuring that at least one token is generated in each step. The final output is then the longest sequence that passes our acceptance test.
What's great about this approach is its adaptability. If you set the sampling temperature to zero, it simply reverts to the most efficient form—greedy decoding. When you increase the temperature, our method becomes even more efficient, allowing for longer accepted sequences, a claim we've confirmed through rigorous testing.
So, in essence, our typical acceptance scheme offers a more efficient way to generate the creative output of LLMs.
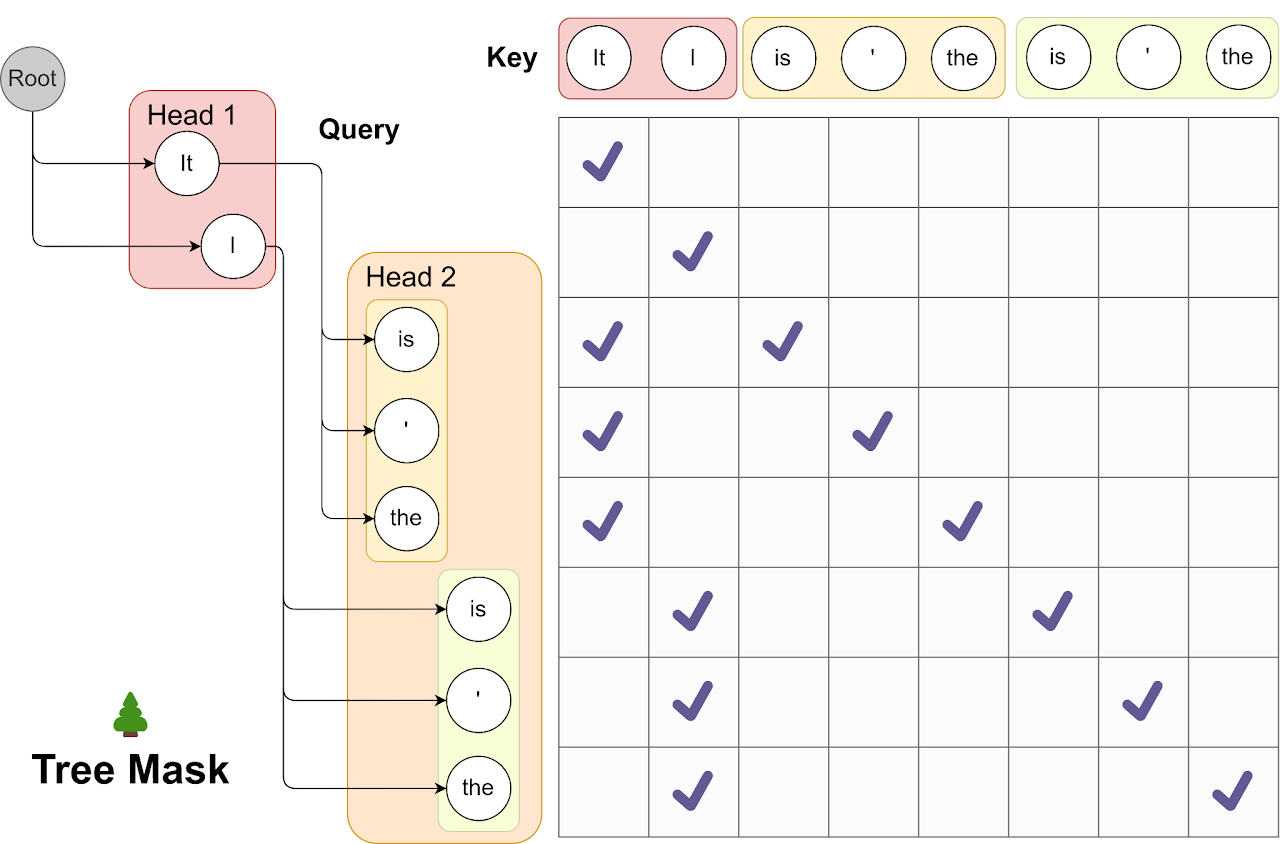
Tree Attention. This visualization demonstrates the use of tree attention to process multiple candidates concurrently. As exemplified, the top-2 predictions from the first Medusa head and the top-3 from the second result in 2*3=6 candidates. Each of these candidates corresponds to a distinct branch within the tree structure. To guarantee that each token only accesses its predecessors, we devise an attention mask that exclusively permits attention flow from the current token back to its antecedent tokens. The positional indices for positional encoding are adjusted in line with this structure.
How Fast Can a Llama Spit?
We tested Medusa with Vicuna models, which are specialized Llama models fine-tuned specifically for chat applications. These models vary in size, with parameter counts of 7B, 13B, and 33B. Our goal was to measure how Medusa could accelerate these models in a real-world chatbot environment.
When it comes to training Medusa heads, we opted for a simple approach. We utilized the publicly available ShareGPT dataset, a subset of the training data originally used for Vicuna models and only trained for a single epoch.
And here's the kicker—this entire training process could be completed in just a few hours to a day, depending on the model size, all on a single A100-80G GPU. Notably, Medusa can be easily combined with a quantized base model to reduce the memory requirement. We take this advantage and use an 8-bit quantization when training the 33B model.
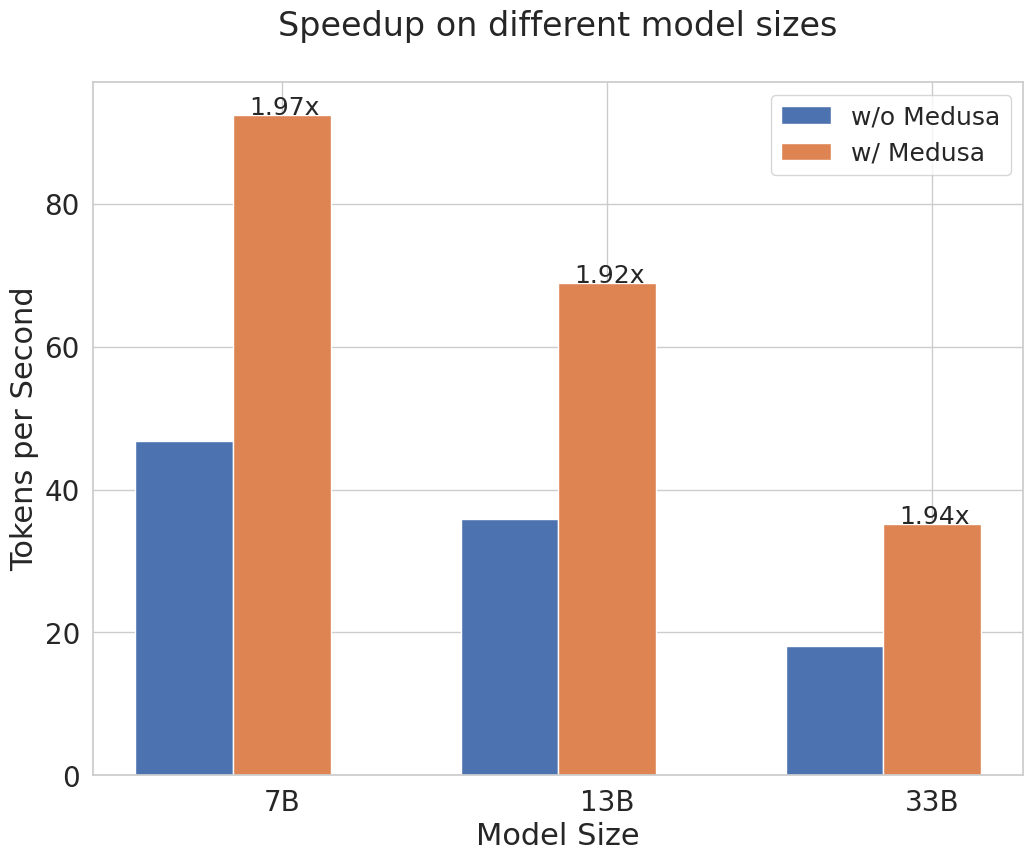
To simulate a real-world setting, we use the MT bench for evaluation. The results were encouraging: With its simple design, Medusa consistently achieved approximately a 2x speedup in wall time across a broad spectrum of use cases. Remarkably, with Medusa's optimization, a 33B parameter Vicuna model could operate as swiftly as a 13B model.

Acknowledgements
We extend our heartfelt gratitude to several individuals whose contributions were invaluable to this project:
- Zhuohan Li, for his invaluable insights on LLM serving. If you haven't already, do check out Zhuohan's vLLM project—it's nothing short of impressive.
- Shaojie Bai, for engaging in crucial discussions that helped shape the early phases of this work.
- Denny Zhou, for introducing the truncation sampling scheme to Tianle and spurring the exploration in the area of LLM serving.
- Yanping Huang, for pointing out the memory-bound challenges associated with LLM serving to Tianle.
- stability.ai, for open-sourcing impressive models that we used for designing our logo.
- together.ai, for sponsoring this project and engagement in future development.
- ChatGPT, for helping polish the blog.
Their collective wisdom greatly enriched our research, and for that, we are most thankful.
Appendix: Ablation Studies
An "Appendix: Ablation Studies" section typically delves into the systematic removal of model components or features to evaluate their impact on performance. This process helps to understand which elements are most crucial for a model's effectiveness.
Choice of Medusa head configuration

When harnessing the predictive abilities of Medusa heads, we enjoy the flexibility to select how many top candidates each head should consider. For instance, we might opt for the top-3 predictions from the first head and the top-2 from the second. When we take the Cartesian product of these top candidates, we generate a set of six continuations for the model to evaluate.
This level of configurability comes with its trade-offs. On the one hand, selecting more top predictions increases the likelihood of the model accepting generated tokens. On the other, it also raises the computational overhead at each decoding step. To find the optimal balance, we experimented with various configurations and identified the most effective setup, as illustrated in the accompanying figure.
Choice of threshold in typical acceptance

In the typical acceptance scheme, a critical hyperparameter—referred to as the 'threshold'—helps us determine whether the tokens generated are plausible based on the model's own predictions. The higher this threshold, the more stringent the criteria for acceptance, which in turn impacts the overall speedup gained through this approach.
We explore this trade-off between quality and speedup through experiments on two creativity-oriented tasks from the MT bench. The results, depicted in the figure, reveal that the typical acceptance offers a 10% speedup compared to greedy decoding methods. This speedup is notably better than when employing speculative decoding with random sampling, which actually slowed down the process compared to greedy decoding