
The Together Inference Engine is multiple times faster than any other inference service, with 117 tokens per second on Llama-2-70B-Chat and 171 tokens per second on Llama-2-13B-Chat
Today we are announcing Together Inference Engine, the world’s fastest inference stack. It is up to 3x faster than TGI or vLLM when running on the same hardware, up to 2x faster than other serverless APIs (eg: Perplexity, Anyscale, Fireworks AI, or Mosaic ML1). This means the most demanding generative AI applications in the world can now provide a much faster user experience, with greater efficiency, and lower cost.
The Together Inference Engine is built on CUDA and runs on NVIDIA Tensor Core GPUs. Over the past several months, our team and collaborators have released a number of techniques that optimize inference performance including FlashAttention-2, Flash-Decoding, and Medusa, available in the open source and incorporated into many libraries. Our team has combined these techniques with our own optimizations and today we are excited to announce the Together Inference Engine.
At Together AI, we’re focused on providing the fastest cloud for generative AI. Since launching, we have had over 10,000 users sign up and many production applications are now built on Together Inference. Now, with the fastest inference engine, we are excited to bring blazing fast performance to AI developers and enterprises around the world.
Performance
To measure the performance of the Together Inference Engine in a transparent manner, we leveraged the new open-source LLMPerf benchmarking harness released by Anyscale. First, we use the default setting for LLMPerf, which takes as input on average 500 tokens and generates on average 150 output tokens.
Together Inference Engine compared to TGI and vLLM with default LLMPerf settings


Together Inference API compared to Perplexity and Anyscale APIs with default LLMPerf settings


Together Inference API compared to Perplexity and Anyscale APIs with modified LLMPerf settings
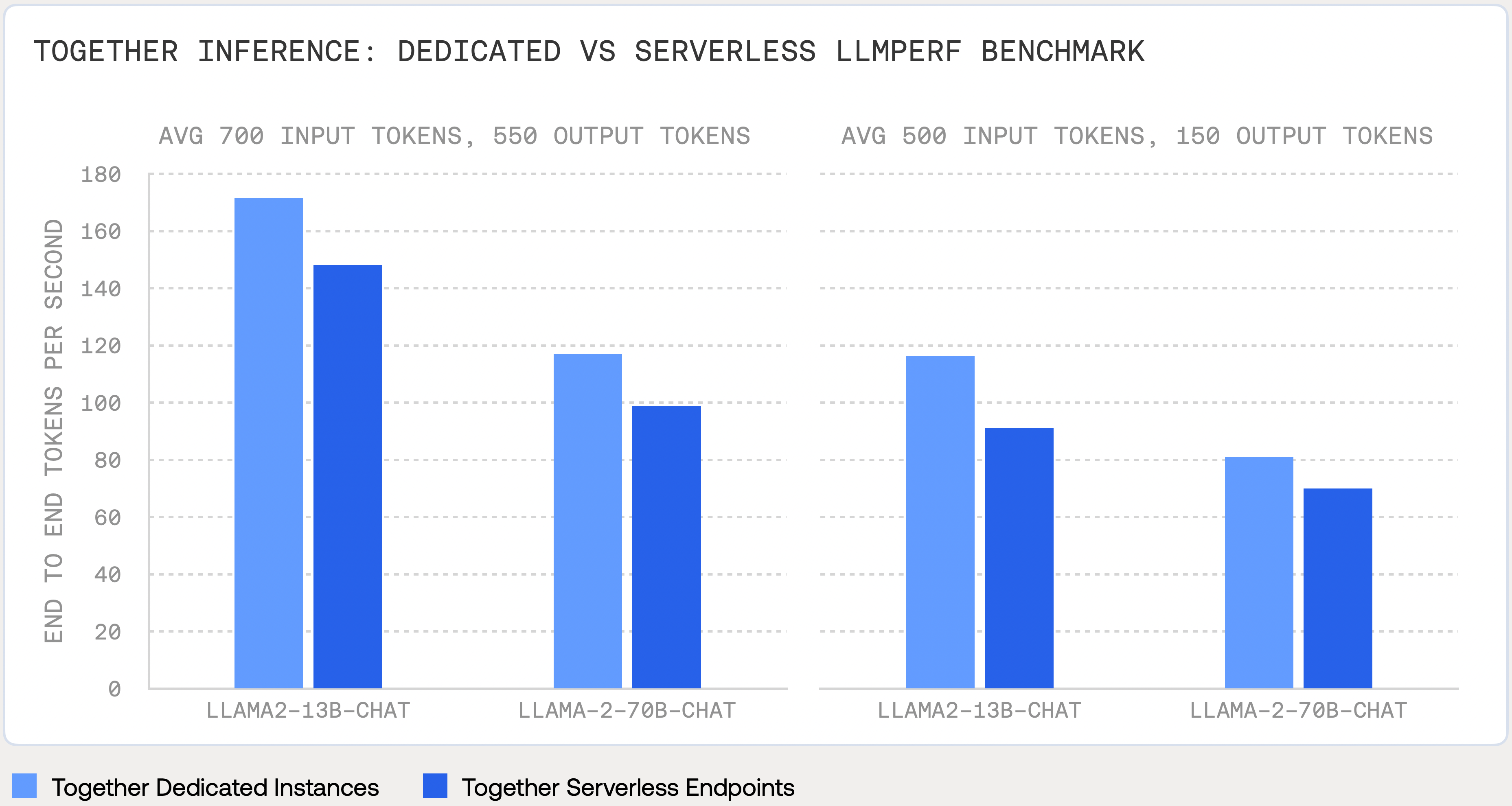
Second, we use modified LLMPerf settings which take as input on average 700 tokens and generates on average 550 output tokens.


Quality
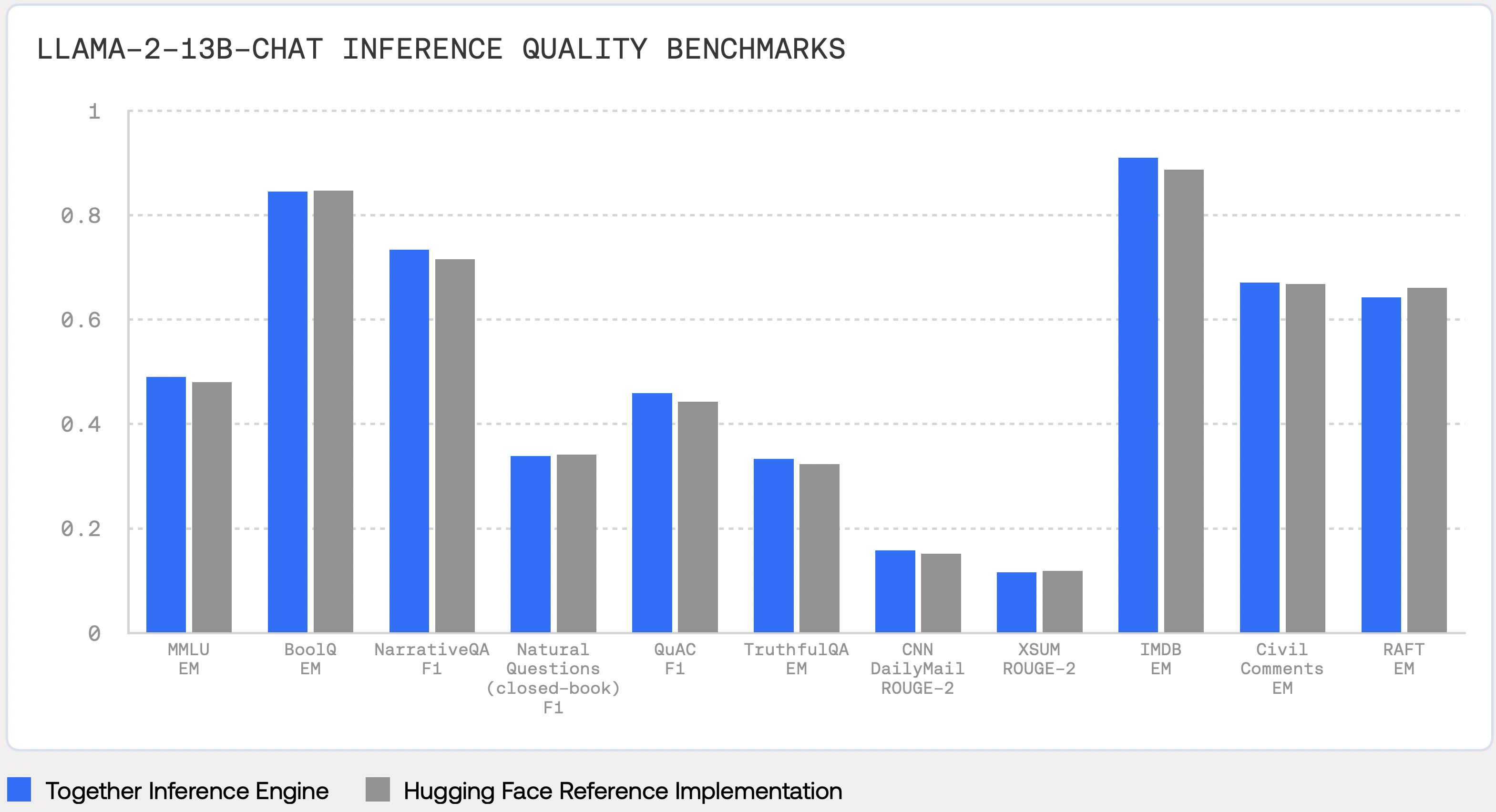
The improvements to performance with the Together Inference Engine come without any compromise to quality. These changes do not involve techniques like quantization which can change the behavior of the model, even if in a modest way.
The following table shows the results of several accuracy benchmarks. Together Inference achieves results inline with the reference Hugging Face implementation.
Features
We’ve received incredible feedback from our customers, including the desire to have more flexibility in how they use the Together Inference API. So today we are also introducing a number of new features.
Serverless Endpoints
Over 50 leading open-source models are hosted for you through Serverless Endpoints, including Llama-2, RedPajama, Falcon, and Stable Diffusion XL. We continue to curate the best models to be featured and available – adding new leading models as they become available.
With Serverless Endpoints capacity is automatically added and scales depending on your traffic, eliminating the need for you to choose instance types. With Serverless Endpoints, you pay for just what you use for the sum of the input and output tokens.
Dedicated Instances
Deploy Dedicated Instances for over 100 popular open-source models, your own fine-tuned model, or any proprietary model. Dedicated Instances are designed to match your traffic needs. You choose the hardware configuration, control the number of instances deployed, and how many you allow auto-scaling to.
The Together Inference Engine also dynamically optimizes between faster tokens per second and higher overall throughput. And you can configure the max batch size – to tune between ensuring faster latency for your end users versus allowing for higher overall capacity from the instance.
Auto-scaling
Both Serverless Endpoints and Dedicated Instances can now be configured with auto-scaling, so that additional hardware is automatically provisioned when API volumes exceed the capacity of the currently deployed hardware. And, auto-scaling automatically scales back down to your minimum configured instances when API volumes reduce – saving you costs when running Dedicated Instances.
Additional models
We continue to expand the number of models available out-of-the-box, now with over 100 models available. Since launch, we’ve added over 35 new models including recent updates like Mistral, Nous Hermes, and Lemma.
Pricing
With faster performance, we use less compute resources. And we’re excited to reflect these efficiencies onto you as the customer in the form of lower pricing. Today we are lowering the price of Serverless Endpoints for 70B models including Llama-2-70B to $0.0009 per 1K tokens.
Leverage models like Llama-2-13b-Chat, at 6 times lower cost than GPT 3.5 Turbo, with performance that is 1.85 times faster.
Updated pricing for Llama-2 models is as follows:
For full pricing details, including other models, visit our pricing page.