
At Together AI we have an increasing number of customers and partners leveraging the Together API for multi-agent workflows and applications. The ability to leverage multiple models, with industry-leading performance has made Together Inference a leading solution for agent-based workflows. Recently we worked with Axiomic, a new AI agent build framework, who integrated the Together API into the core framework as the provider for using open-source models.
In this post we explore agent building using one of Axiomic's demos called GEAR Chat, which shows how four agents work together to provide a portable, steerable, and debuggable chat agent.
Axiomic
Axiomic is a new Python library for building AI agents, built on the belief that AI agents need to be easy to build yet production-ready. Axiomic's goal is to build on the learnings from PyTorch and TensorFlow to be an open part of the AI ecosystem. Axiomic was released today on GitHub. Let's look at one of Axiomic's demos available at launch, GEAR Chat, to better understand the problems Axiomic is trying to solve and how it leverages Together AI to solve them.
GEAR Chat Demo
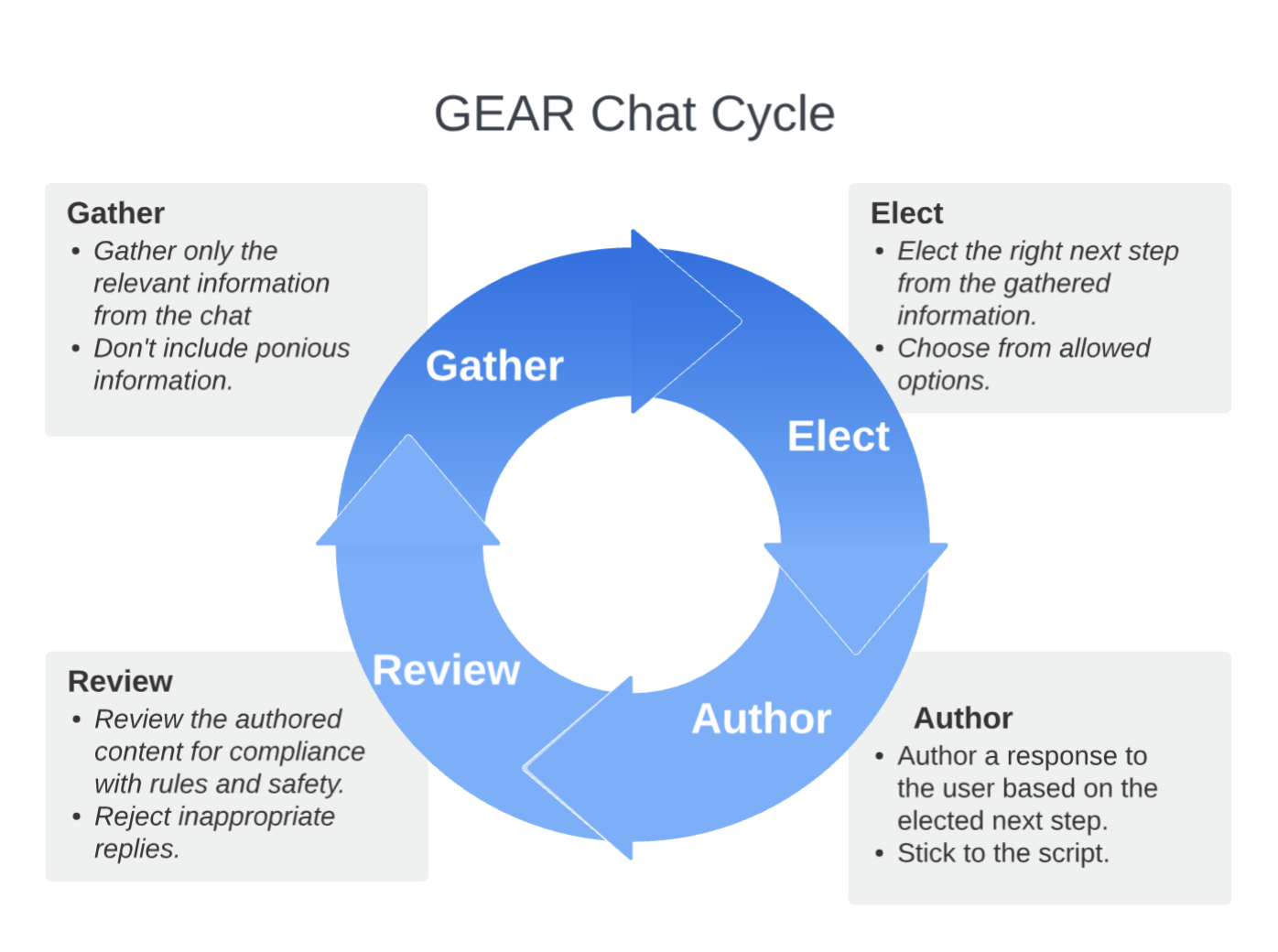
GEAR stands for Generate, Elect, Author, Review, which are four agents that work together to chat with a user. GEAR Chat is a demo in the Axiomic framework, showcasing agents working together in a fun way. We'll explore the motivation and design behind the demo, dive into its construction, and end with some experiments showing its portability across models.
Why use multiple agents instead of just a single inference? Breaking the process into separate agents can greatly improve steerability, portability, and reliability. By specializing each agent on a task, we can shift from essay-style prompting (i.e., providing a single complex list of instructions the model only sometimes follows) to using four separate multishot prompted agents. For example, breaking up a larger single prompt into multiple agents may allow you to use smaller open-source models instead of a larger closed-source model.
Multiple agents working together in chat is not a new idea. A well-known example of this is using Meta LlamaGuard in conjunction with another model to moderate responses for safety.
Let's look at the four agents before we explore how they're connected using Axiomic and run using Together.ai:
- Gather: The Gather agent extracts key information from the chat and reports it in a structured way, ensuring the next steps are focused on the right information.
- Elect: The Elect agent decides on the next action to take, given the gathered information. By focusing on minimal and controlled information, the decision-making space is tightly controlled.
- Author: The Author agent converts the elected action into a response to the user, following the directions.
- Review: The Review agent provides guardrails for the result from the Author agent. For example, it stops the Author from saying, "As an AI assistant, I cannot…"
The fun thing about this demo is that you can create many different chat agents by just changing the prompt files (no re-coding needed). These chat agents can then be run on many different models. It can be helpful to look at a specific example.
Deep Dive: Where To Post? Chat
Let's look at a particular GEAR chat, "Where To Post?", which will jokingly help you figure out where to post on social media. Here is an overview of what each agent will be doing:
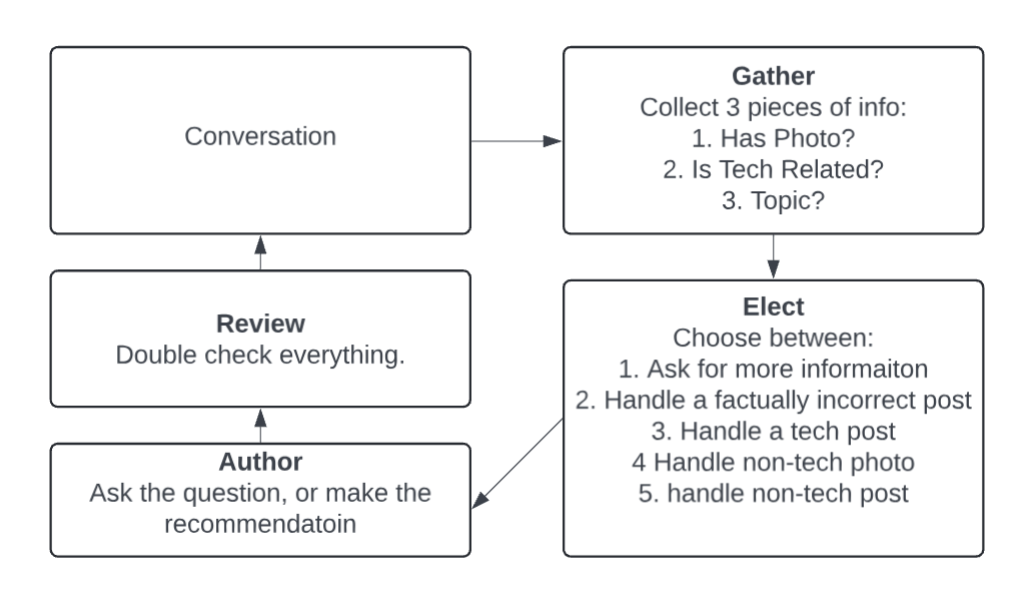
Let's deep dive on the agent: Elect and understand how it's made, used, and evaluated. Here are the key elements of the implementation of the Elect agent using Axiomic. Here, we will use the tried and true technique of MultiShot prompting to build this agent where the input to the Elect Agent is the information gathered from the conversation, and the output is the case to handle. Axiomic makes MultiShot prompting easy with its building blocks for Switch and Pattern which are used extensively through this demo. Here, we use thI’e Switch building block from Axiomic to map examples to cases. This effectively teaches the agent by example.
class ElectAgent:
# (class abbreviated for clarity - see (here) for full implementation)
def __init__(self, elect_examples):
self.examples = [(e.user, e.agent) for e in elect_examples]
self.switch = axi.core.modules.Switch(self.examples)
def infer(self, text):
case_name = self.switch.infer(text).value_json()
return case_name
The examples we're using to teach the agent are stored in a YAML file so the examples can be easily managed outside of the codebase. Your multishot examples could also live in a database or inline in the code itself. Here is an example of one of the examples, mapping the output of the Gather step to the next action to take. You can view the full definition and all of the prompt examples.
- user: |
HAS_PHOTO: [NO_DATA] Unknown
FACTUALLY_CORRECT: [NO_DATA] No information provided
POST_TOPIC: [PARTIAL] Known, but not specified
agent: "LEARN_MORE_ABOUT_POST"
In essence, the Elect agent is implementing a multiclass text classification task. So we can evaluate this agent across the hundreds of models provided by Together.ai. In Axiomic, evaluating multiple models is as easy as iterating over a list of them. After viewing the tutorial on models and parameters, you can find the full evaluation code for the GEAR chat demo.
eval_model_list = [
models.Together.Text.Llama3.llama_3_8b_hf,
models.Together.Text.CodeLlama.codellama_70b_instruct_hf,
models.Together.Text.Llama3.llama_3_70b_chat_hf,
# ... more models ...
]
for model in eval_model_list:
with model:
print(evaluate_elect_agent(chat, elect_eval_examples)))
Here, we've evaluated some of the popular models and reported their F1 scores. Evaluation like this is easy with Axiomic and can help make an informed decision on which model is the best fit for the particular budget and quality trade-off you want to make. In this evaluation across a sample of Together.ai's agents, notice how without changing our agent, we are able to run on a wide variety of models.
Elect Agent Evaluation on Together AI
| Model | F1 Score |
|---|---|
| NousResearch/Nous-Hermes-2-Yi-34B | 1.00 |
| Qwen/Qwen1.5-72B-Chat | 1.00 |
| databricks/dbrx-instruct | 1.00 |
| garage-bAInd/Platypus2-70B-instruct | 0.87 |
| mistralai/Mixtral-8x22B-Instruct-v0.1 | 0.87 |
| meta-llama/Llama-3-8b-chat-hf | 0.87 |
| meta-llama/Llama-3-70b-chat-hf | 0.87 |
| NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO | 0.76 |
| NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT | 0.76 |
| NousResearch/Nous-Capybara-7B-V1p9 | 0.73 |
| Qwen/Qwen1.5-4B-Chat | 0.73 |
| mistralai/Mixtral-8x7B-Instruct-v0.1 | 0.70 |
| Phind/Phind-CodeLlama-34B-v2 | 0.56 |
| NousResearch/Nous-Hermes-2-Mistral-7B-DPO | 0.53 |
| allenai/OLMo-7B-Instruct | 0.53 |
| teknium/OpenHermes-2-Mistral-7B | 0.53 |
| teknium/OpenHermes-2p5-Mistral-7B | 0.53 |
| deepseek-ai/deepseek-coder-33b-instruct | 0.53 |
| NousResearch/Nous-Hermes-llama-2-7b | 0.51 |
| mistralai/Mistral-7B-Instruct-v0.1 | 0.51 |
| cognitivecomputations/dolphin-2.5-mixtral-8x7b | 0.51 |
| Snowflake/snowflake-arctic-instruct | 0.47 |
| meta-llama/Llama-2-13b-chat-hf | 0.45 |
| WizardLM/WizardLM-13B-V1.2 | 0.45 |
| Qwen/Qwen1.5-14B-Chat | 0.45 |
| Qwen/Qwen1.5-7B-Chat | 0.43 |
| openchat/openchat-3.5-1210 | 0.38 |
| NousResearch/Nous-Hermes-Llama2-13b | 0.37 |
| Qwen/Qwen1.5-1.8B-Chat | 0.25 |
| togethercomputer/StripedHyena-Nous-7B | 0.23 |
| Open-Orca/Mistral-7B-OpenOrca | 0.20 |
| lmsys/vicuna-13b-v1.5 | 0.18 |
| Qwen/Qwen1.5-0.5B-Chat | 0.16 |
What's striking here is the huge variety of results we get across models. We found three different models with perfect evaluation results for this agent, ranging in size from 34B to 72B parameters. Some smaller models, like Llama-3-8B, performed very well too. Keep in mind that each agent is different, and these results will not reflect how the model performs on your task.
Axiomic helps you easily obtain this information for your application and stay on top of every new model release. You see the full implementation and see other tutorials for Axiomic, and read the docs.
Just the Beginning
We’re excited by the future of leveraging sophisticated agents for multi-step AI applications. The growing ecosystem of tools Axiomic that leverage Together AI to makes building these applications easier and shows the value of the incredible open-source AI ecosystem.
If there are tools you’re using to build multi-agent workflows, or demonstrations of the value we’d love to hear about them! Please feel free to share on our Discord or drop us a note by contacting us.