
TLDR. This blog post shows how to build an effective data scientist agent from scratch using Together’s open-source Models and Together Code Interpreter. While straightforward to implement, our agent performs well on several different use cases and benchmarks. We open source our codebase on GitHub.
Introduction
The daily work of data science requires us to sift through messy, incomplete information to extract actionable insights. This is often a process that requires multiple steps, ranging from data cleaning to model training and data analysis. Considering the explosion in capabilities of large language models, it is natural to start thinking about how to use readily available open-source technologies as a foundation for building agents that can effectively manipulate and analyze data.
While human data scientists need to remain at the heart of these processes, AI agents can help support some of the workload and reduce the burden of analytical tasks.
Today, we show how to implement a simple yet effective data scientist agent that can solve data science tasks. The implementation of this agent will be end-to-end, from the design of the pipeline to the implementation and the testing. We will do this using models and tools that are accessible on the Together Cloud, making this development surprisingly accessible. This “recipe” we share today for data science can be extended to other agents in other settings.
In particular, we will follow a ReAct (Yao et al., 2023) pattern: the agent will first “think” and then “act”. Each action the agent generates is a Python snippet (e.g., `import pandas as pd; pd.read_csv(...)`). This is strongly inspired by the smolagents package, which is in turn inspired by the CodeAct (Wang et al., 2024) and the original ReAct paper.

The Open Data Scientist’s actions have to be executed. While conceptually this is an “easy” step, in practice it is not: code execution is, by nature, a very unsafe operation; even more so in the context of language models, where you do not know what the code generated by the language model is going to look like. To solve this problem and to run code safely and efficiently, we will use the Together Code Interpreter (TCI). TCI elegantly abstracts away the complexity of sandboxed Python execution, providing a clean API that accepts code and returns structured results. This architectural choice has strong implications for our agent's design—it becomes inherently modular and maintainable. Since the code execution layer is completely decoupled from the reasoning logic, we can modify prompts, adjust the ReAct patterns, or add new analytical capabilities without touching the execution infrastructure. The agent's behavior becomes highly tunable through prompt engineering alone, while TCI ensures consistent, reliable execution regardless of the complexity of the generated Python code.
After having implemented the agent, we will focus on evaluation by providing quantitative and qualitative results regarding its performance. We will discuss some best practices on how to start building agents from scratch.
Our data scientist agent implementation serves as a transparent example for understanding how to use open source models and TCI to build an agent and to evaluate agentic pipelines. Since this entire solution can be composed using Together Cloud features with just a single API key, this blog post is a good reference for those looking to understand the fundamentals of building reasoning-driven AI assistants.
Why build agents from scratch?
This is a good question! Considering the number of frameworks out there, one might not need to dive into lower-level implementations. However, in the context of agentic models, it is actually good to know how things work at a lower level of abstraction.
Observing the steps a language model must take to interact with the external world is helpful in better understanding how the agent solves problems and how to improve general agent architectures. Even more so, considering how many edge cases one ends up encountering in the process of building agent architectures. Indeed, another interesting feature is that the Open Data Scientist agent we are going to build here is “hackable” and adaptable to different use cases.
A CodeAct Data Scientist
ReAct
The ReAct framework was introduced by Yao et al., 2023 to improve language agents. The idea behind the ReAct framework is encapsulated in its name: Reasoning and Action. The agent's activity unfolds using the following cyclical set of steps: the agent is tasked with a goal, reasons about what the next step could be, and then prepares the inputs to an action (which is then executed). Each action generates an observation from the environment, which is used as a source of new information for the next React step.
To clarify, the agent operates entirely through text generation. When we say the agent "reasons about the task," we mean it outputs natural language that articulates its step-by-step thinking process. When we say the agent "prepares the next action," we mean it generates structured text that specifies which function to call and with what parameters. Both reasoning and action preparation are fundamentally text generation tasks that enable the agent to interface with external tools and environments.
What does this mean in practice? In our "system prompt," we ask the language model first to write its reasoning and then to specify an actual action.
Why let the agent reason?
Letting the agent reason is inspired by chain-of-thought approaches, which show language models benefit from "thinking problems out loud". This is essentially a preparation step before acting:
- Reason: The agent develops a description of its reasoning
- Action: The agent designs an action to execute
- Observation: The environment returns information to the agent
Consider an agent whose task is to answer "What's the weather in NYC?". This could unfold as follows: The language model would reason, "I need to use the weather API tool to find the weather in NYC," and then construct the function call weather("NYC"). In reality, the entire process can occur within a single generation from the language model, where it's prompted to first think and then produce what's known as a tool call.
Once the language model generates the text, we can extract this action and execute it. We collect the output of the action (called observation) and add it to the context of the model. We then sample more tokens from the language model, which now is influenced by the additional observation of the context and will be able to provide an answer to the question above.1
CodeAct
There are a few different ways one can build a ReAct pipeline. The Open Data Scientist will follow the CodeAct format and ask the model to output all actions as Python code. This approach comes with some advantages and disadvantages, but it is generally a very flexible way for the agent to design actions: the agent can express more complex operations than what would be possible with simple tool calling, since it can, in practice, combine multiple operations in a few lines of python code.2
At each step, the language model inside our CodeAct agent will perform two possible actions: 1) generate a thought and then Python code as an action or 2) generate a thought and output a final answer for the user. Here’s an example:

Once we receive a response from the agent, we will examine the content and extract the actions by looking at sentences that start with “Thought” and “Action” to identify what the agent intends to execute. This simplifies our loop and makes it highly effective. We send the Action to the environment and once we obtain the results, we add it back to the chat context of the LLM so that the agent knows what has happened.
Together Code Interpreter
Note: TCI allows you to execute code safely in the cloud. For users who would prefer to execute code locally, we also release a simple (but very limited) local code sandbox as an alternative. More details available on the codebase.
The Together Code Interpreter allows us to run Python code in a safe environment and to collect the output of any line of code we send to it. TCI is fast and effective. At the start of a new task, we allocate a code interpreter sandbox and load the required files to do the analysis. TCI allocates a sandbox that stays alive for 60 minutes and can be used to run operations much like it was a Jupyter notebook.
TCI comes pre-installed with essential data science libraries like pandas, numpy, matplotlib, and scikit-learn, while supporting dynamic installation of additional packages: for example, one of the examples below requires installing RDkit, a library for cheminformatics. The platform handles rich output types including visualizations and maintains persistent state across code executions within a session.
To simplify setup, in our repository, we also share a simple local code sandbox that is good for testing and building. This is also useful in case you want to run the agent on some local files, without having the need to upload them on the cloud.
Simple, yet effective, and we make it accessible to everyone
To make the open-source data scientist even more accessible, we developed a command line tool for the users to try out.
The Open Data Scientist agent can be triggered with one command line call:
`open-data-scientist –executor tci --write-report`
Below is an example report generated by our command line tool, provided with a cheminformatics task of predicting solubility of molecules:

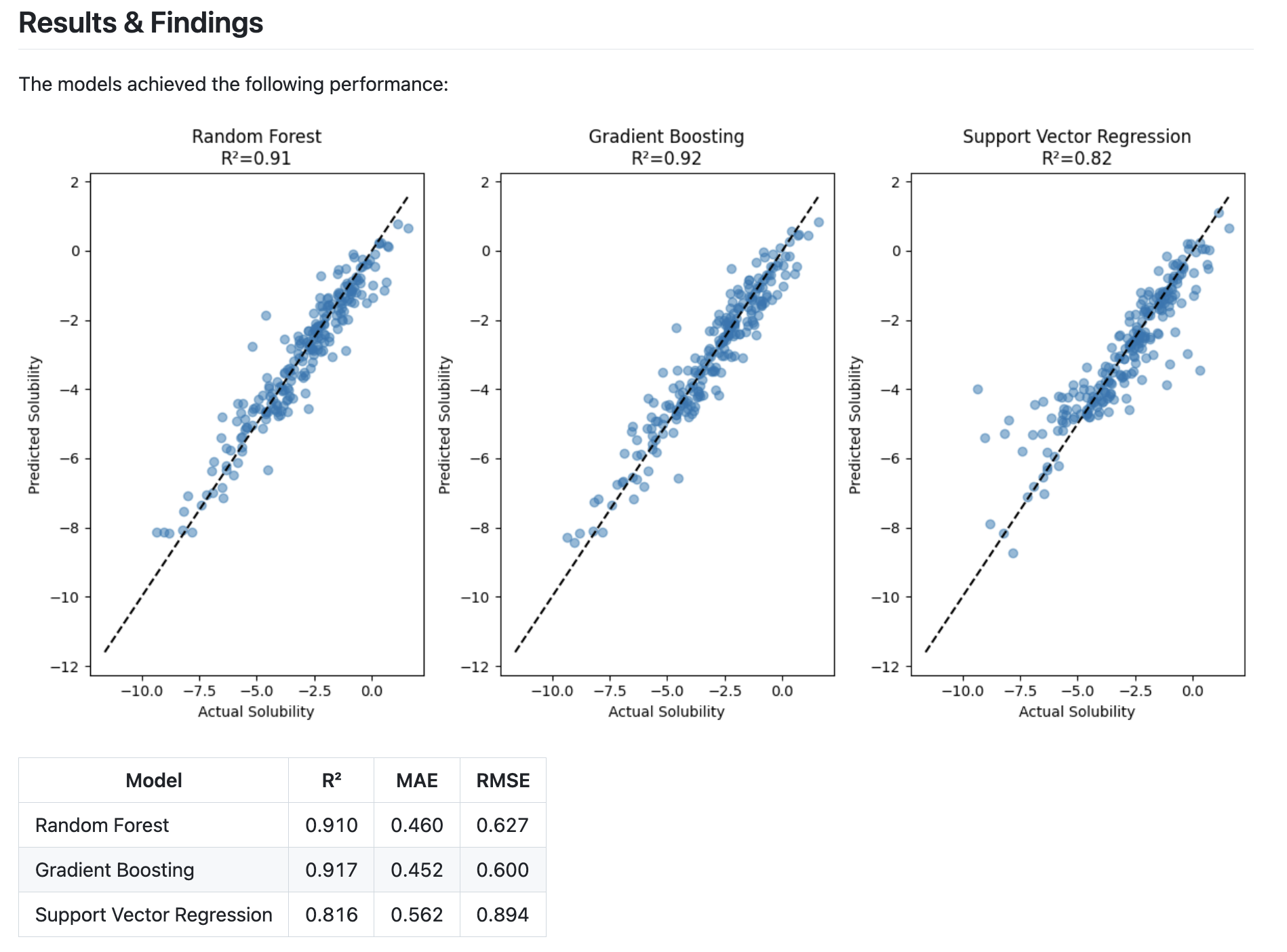
(task: “build an ml model to predict molecular solubility using the given dataset, and analyze model performances”)
In this example, the data scientist agent explores the user-provided data, inspects the development environment and install missing packages, and then develops a simple machine learning model, followed by result visualization and report writing steps. All these are fully automated and can be achieved with one Together API Key and a terminal. More details can be found in our codebase. We provide more analysis and evaluation results in the following section.
Interesting Reasoning Patterns
Our Open Data Scientist shows interesting self-correcting patterns. Note that content in the “Result” boxes is generated by the environment, not by the model. The content of the box is added to the model’s context for the generation of the next action)
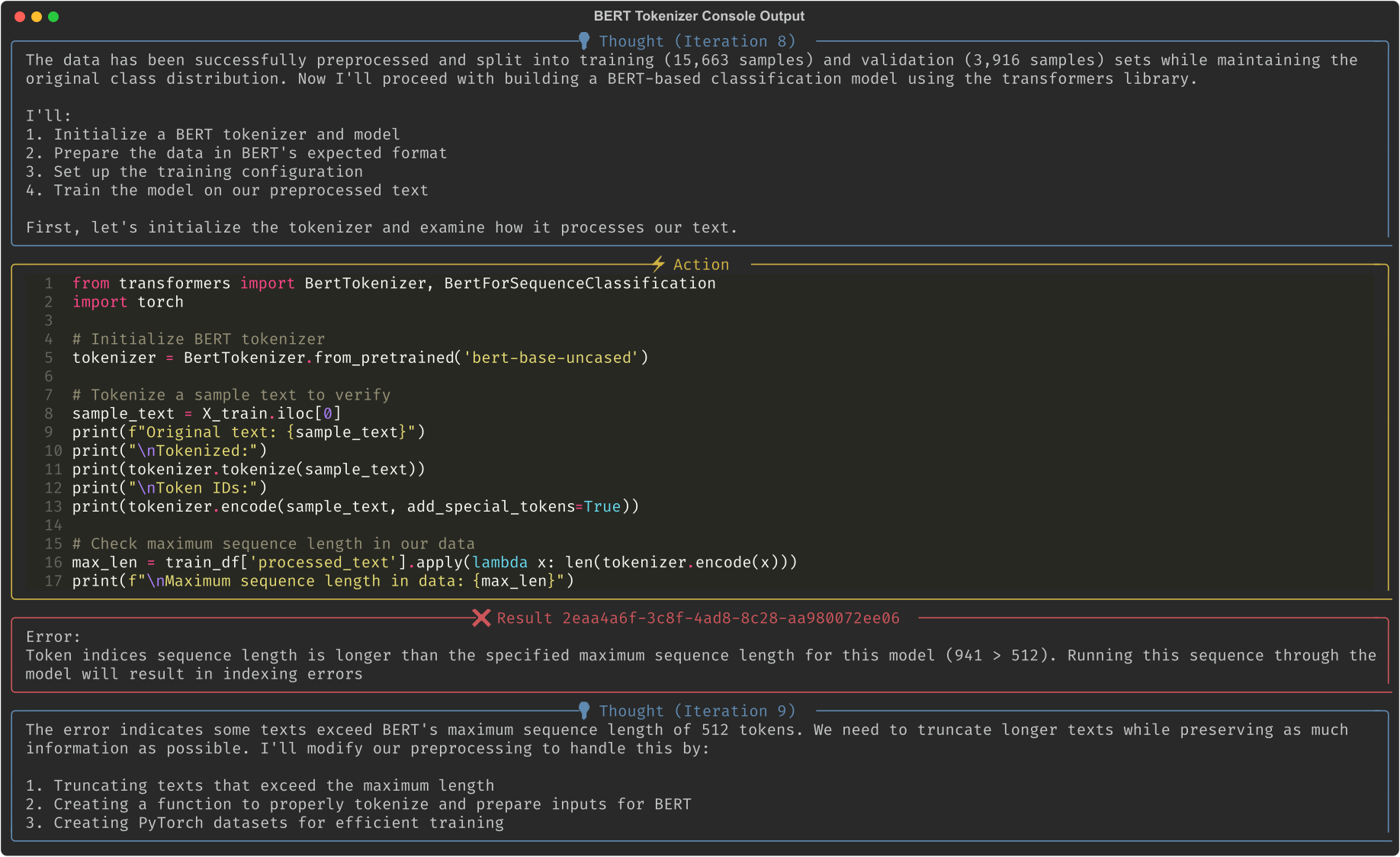
1. For example, when attempting to use a BERT tokenizer to process data, it quickly becomes apparent that the dataset's token lengths exceed the model's token limit. Thus, it implements an alternative plan.
2. Similarly, when using one of the Sklearn linear models, warning messages inform the agent that the model it has trained has not converged, the agent thus decides to train the model again with more iterations to solve the problem.

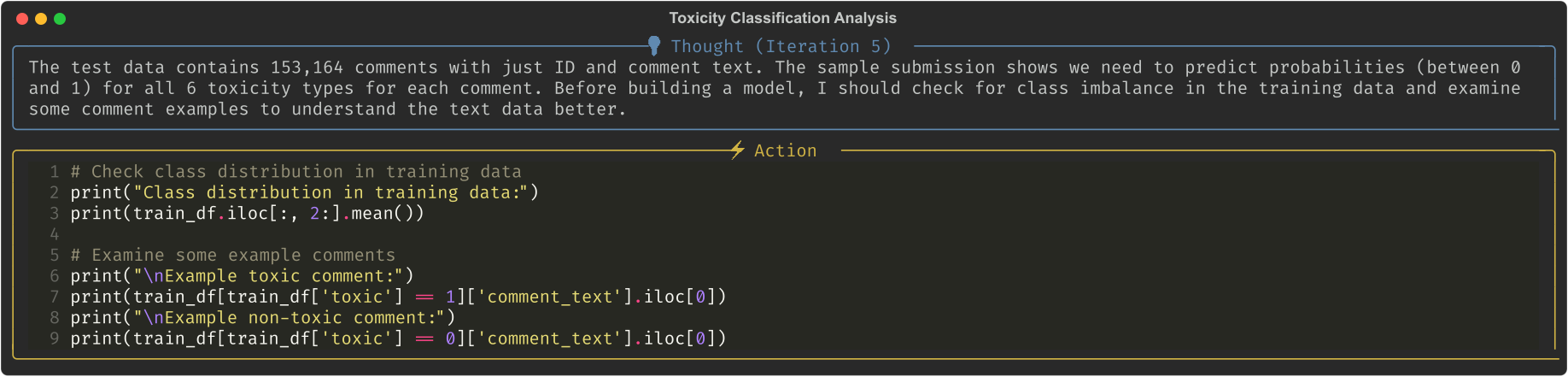
3. Finally, the model also explores the data and tries to find better strategies to solve the problem.
Evaluating Data Scientist Agents
We extract two text tasks from OpenAI’s MLE-bench (Chan et al., 2024) as examples of real-world data science tasks. We then use the DABStep (Data Agent Benchmark for Multi-step Reasoning, Iglesias et al., 2025) benchmark. All our experiments are run with DeepSeek-V3 as a backend model. We release the output files we got from the model in the repository.
Kaggle
We select two tasks from the OpenAI MLE-bench Lite, namely the Spooky Author Identification and the Jigsaw Toxic Comment challenge. These are tasks that can be easily reproduced and that do not require downloading gigabytes of data. Our interest in these two benchmarks is mainly to see if the agent can solve an entire Kaggle task end-to-end. We keep the question prompt very high-level, we do not mention what the challenge is about; we just point the agent to the directory and instruct it to solve the challenge (which means opening the readme and understanding the task first).
When challenged with these tasks, the agent was able to go through the tasks end-to-end. Which means: looking at the instructions, loading the data, doing some initial pre-processing, training some sklearn models, and running them. The agent saves a submission file that can then be used to evaluate the performance of the agent on the leaderboard. Both submissions provide reasonable results, while far from the top scores. This is generally due to the fact that the techniques employed by the agent are good for a first approach, but not enough to get better results.
Interestingly, when asked to use more modern techniques, like sentence embeddings or even fine-tuning a BERT model, the agent was able to successfully use these techniques, also implementing evaluation pipelines to verify if, for example, the fine-tuning was successful. This means that instructing the agent on what to use is still very important.
DABstep
DABstep is a comprehensive benchmark developed by Adyen and Hugging Face to evaluate the capabilities of AI agents in real-world data analysis tasks. Comprising over 450 data analysis challenges derived from actual business workloads, DABstep tests AI systems on both structured and unstructured data, requiring them to perform multi-step reasoning across diverse analytical scenarios. What makes this benchmark particularly useful is the fact that it requires minimal setup: we can download the questions and the dataset files using Huggingface; the agents need access to a limited (but comprehensive) set of files to answer all the questions.
The benchmark is specifically designed to assess how well language models and AI agents can handle complex data tasks that require sequential problem-solving rather than single-shot solutions.
In particular, DABstep assumes that the agents read the documentation which contains very specific definitions on how to interpret some terms (e.g., computing “fees” requires the usage of a specific formula, agents will never get the answer right if they do not read the documentation). We thus make the question prompt very domain specific to the challenge, forcing the agent to read all the documentation and thinking about the important details when providing answers. Current performance metrics reveal significant room for improvement, with even the most advanced reasoning-based agents achieving low accuracy on the benchmark.

From the results, we see that the agent is good at solving easy problems in the benchmark. The agent currently gets the highest scores on the validated leaderboard for the easy tasks (see our submission files here). For hard problems, it is comparable to other, very strong baselines, like Claude4 and GPT4.1 ReAct agents and outperforms the Gemini Data Science Agent! This is a pretty good result for a simple agent, also considering this is one of the best open-source submissions!
Not all problems are solved correctly! In some cases we see the agent confusing some of the instructions and outputting python code as the final answer (you can check the actual results to see what’s happening). This can probably be solved by improving the prompt a little bit more or changing how we extract the actual answer.
Coda
Building an effective data scientist agent is more accessible than expected. Using open-source models, the ReAct framework, and Together Code Interpreter, our simple yet effective implementation achieves competitive performance on benchmarks like DABStep.
While this agent has limitations around control and user interaction, it demonstrates the fundamental patterns needed for reasoning agents that can handle complex, multi-step data science tasks using readily available tools.
What do you need to build good agents?
Start with the fundamentals. Good prompts can take you very far in the process. For example, in the context of DABStep, it's very important to tell the model to review the actual documentation and read it carefully before taking any other step. Adding a simple sentence to the prompt can significantly boost the model's capability.
Agents can understand which solution you want, but they don’t know which trajectory they should take to get you there. When solving Kaggle problems, the agent always assumed that using a sklearn TFIDF vectorizer was sufficient to solve the problem. This is, by all means, not wrong, but in 2025, it is most likely a suboptimal solution. When prompted to use sentence-transformers or to fine-tune BERT, the model followed a more “modern” trajectory to find the answer to the problem. Being very specific with the agent helps getting the right trajectories.
Robust execution environments matter more than you think. Your agent needs a reliable code interpreter that can handle dependencies, manage state across multiple steps, and recover gracefully from errors. We found Together Code Interpreter particularly effective because it maintains context between execution steps and provides clear error feedback. TCI also allows us to open many different sessions that run independently, making it the perfect tool for parallel workflows.
Design for iteration, not perfection. The best agents aren't the ones that get everything right on the first try—they're the ones that can debug and self-correct their own mistakes. Build in explicit error-handling patterns and teach your agent to examine its outputs critically (note that while this might not give the agent the capability to solve all problems, it still is a pretty good mechanism, as we saw in the examples above)
Tests, tests, tests. When building agents, any edit to your prompt or framework logic can break existing functionality in unexpected ways. Write comprehensive unit tests for every component—prompt variations, tool calling patterns, error recovery flows. We learned this the hard way when a small prompt change that improved performance on one task completely broke the agent's ability to locate files in the folder. Automated testing catches these regressions before they reach the final stages.
Keep the human in the loop without breaking the flow. The sweet spot is an agent that can work independently on well-defined tasks but knows when to ask for clarification. You might find it useful to build clear handoff points where the agent surfaces its reasoning and asks for validation before proceeding with major decisions.
Limitations
There is no real control on the agent’s action, and - under a pure engineering point of view - there is too little logging to make this a reliable tool/application. The data science process should allow interactions between the agent and the user so that interpretation errors can be quickly fixed.
Acknowledgements
We are really grateful for the HF Smolagents package, which was a source of inspiration for this release. Also we are very grateful to Adyen for providing us with a benchmark that is simple to use and requires little scaffolding on the user side.
References
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. Proceedings of the International Conference on Learning Representations (ICLR).
Wang, X., Chen, Y., Yuan, L., Zhang, Y., Li, Y., Peng, H., & Ji, H. (2024). Executable code actions elicit better LLM agents. Proceedings of the International Conference on Machine Learning (ICML).
Chan, J.S., Chowdhury, N., Jaffe, O., Aung, J., Sherburn, D., Mays, E., Starace, G., Liu, K., Maksin, L., Patwardhan, T., Weng, L., & Mkadry, A. (2024). MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. ArXiv, abs/2410.07095.
Iglesias, M., Egg, A., & Kingma, F. (2025, February). Data Agent Benchmark for Multi-step Reasoning (🕺DABstep). Adyen. https://www.adyen.com/knowledge-hub/data-agent-benchmark-for-multi-step-reasoning-dabstep
1 There are a few different ways to implement this pattern. In smolagents, for example, tokens are streamed until a code tag is reached. Qwen-Agent uses more standard tool calling instead.
2 Indeed, one can also add tools to the agents in the form of python functions `find_weahter_in`. This is actually what powers the agents behind smolagents.