
Earlier this year, we invited select customers—including Zoom, Salesforce, and InVideo—to test-drive NVIDIA Blackwell GPUs on Together GPU Clusters. Now, we’re excited to share that Together AI is rolling out NVIDIA Blackwell support for Together Inference, unlocking the next level of performance for real-world AI applications.
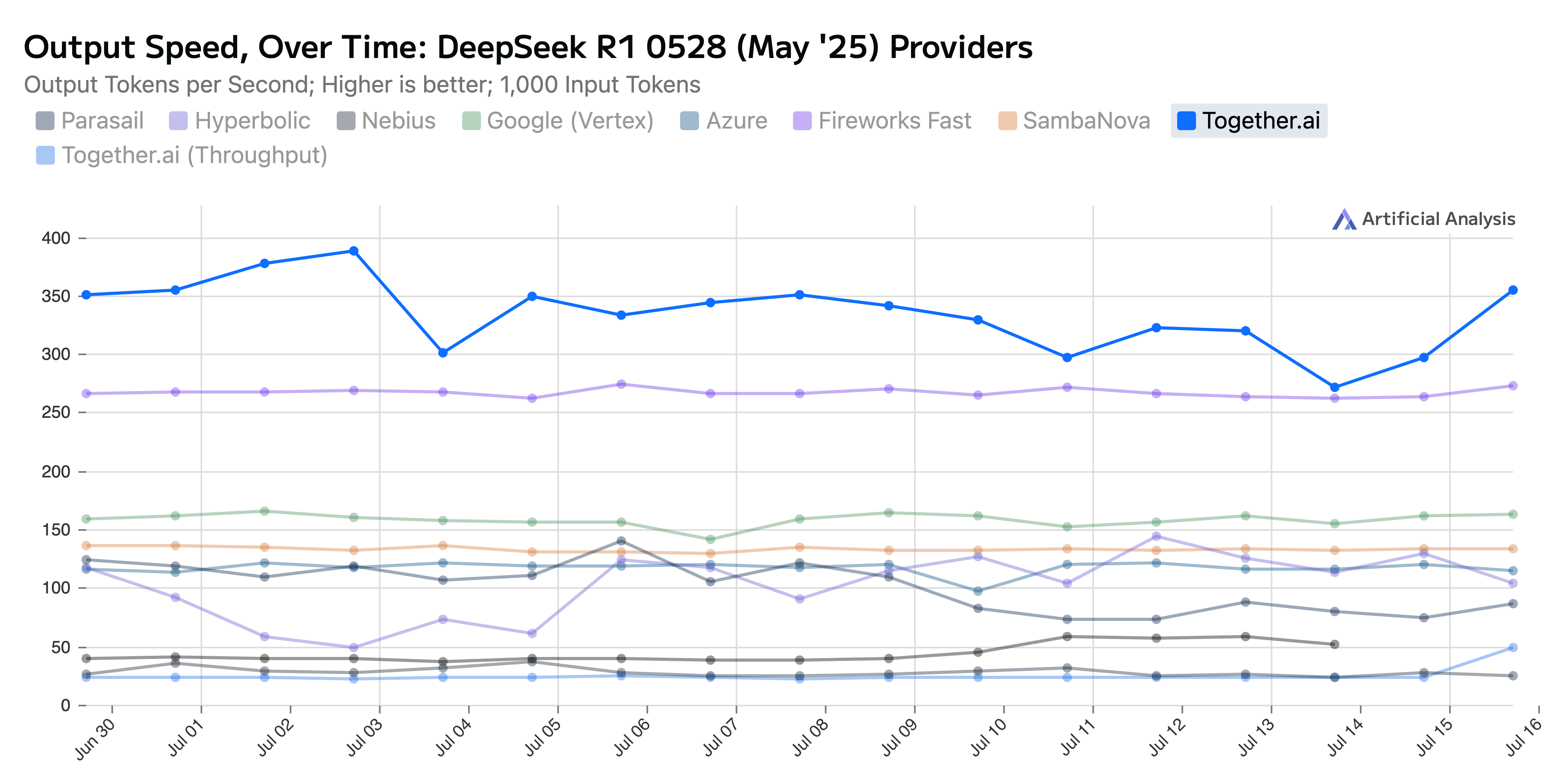
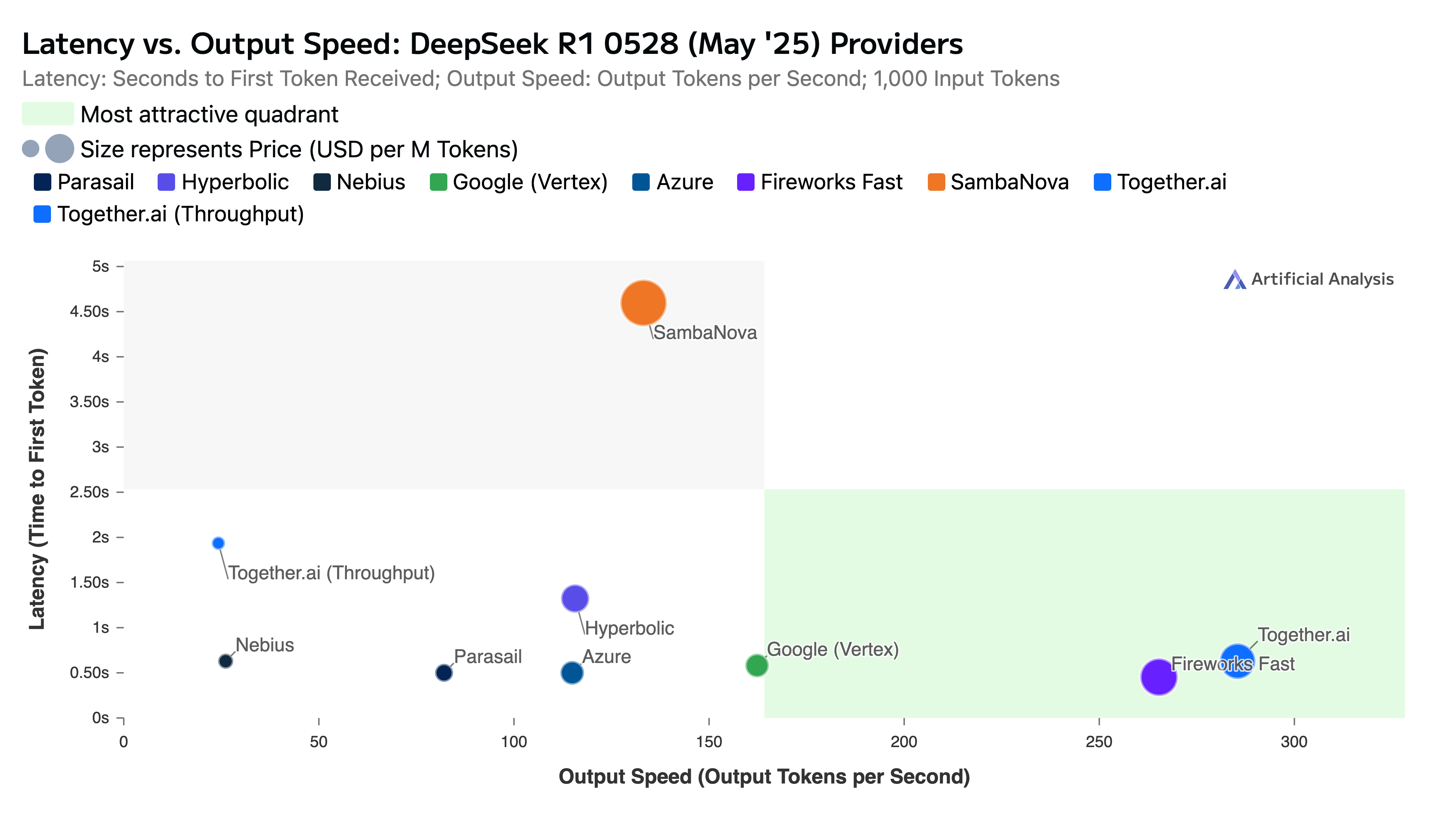
The verdict is clear: Together AI inference is now among the world’s fastest, most capable platforms for running open-source reasoning models like DeepSeek-R1 at scale, thanks to our new inference engine designed for NVIDIA HGX B200.
In this blog post, we share results from an early-access production deployment of DeepSeek-R1-0528 on NVIDIA HGX B200. As of July 17, 2025, this is the fastest serverless inference performance (to our knowledge) of DeepSeek-R1.
You can experience this speed today via Together Chat. The serverless NVIDIA HGX B200 endpoint is currently in closed beta, serving production workloads from our early customers. Reach out to our Sales team to be among the first to get access as we expand.
Together AI optimizes every layer of the stack—(1) bespoke GPU kernels, (2) a purpose-built proprietary inference engine, and (3) state-of-the-art speculative decoding methods and (4) calibrated and quantized model optimization — to boost LLM speed and efficiency to new heights without compromising quality.
Together AI offers a flexible set of infrastructure options for running both inference and training of frontier AI workloads. Whether you're scaling up experiments or deploying production systems, you can choose the level of control and performance that fits your needs:
Get in touch to build with Together AI cloud services accelerated by NVIDIA Blackwell GPUs.
Together’s State-of-the-Art Inference on NVIDIA HGX B200
We now analyze how Together’s inference stack for R1-0528 performs relative to a leading open source inference engine on NVIDIA HGX B200 GPUs and the previous generation NVIDIA H200 GPUs. As you can see in the figure below, Together’s inference stack with our in-house Turbo speculator attains a maximum decoding speed of ~334 tokens/sec, a ~32 tokens/sec speedup over the maximum performance without Together’s inference stack of ~302 tokens/sec and a 2.3x to 2.8x speedup over H200 speeds. Crucially, these performance gains are achieved without sacrificing model quality (see Appendix for comparison).

Customize a Dedicated Endpoint for your Needs
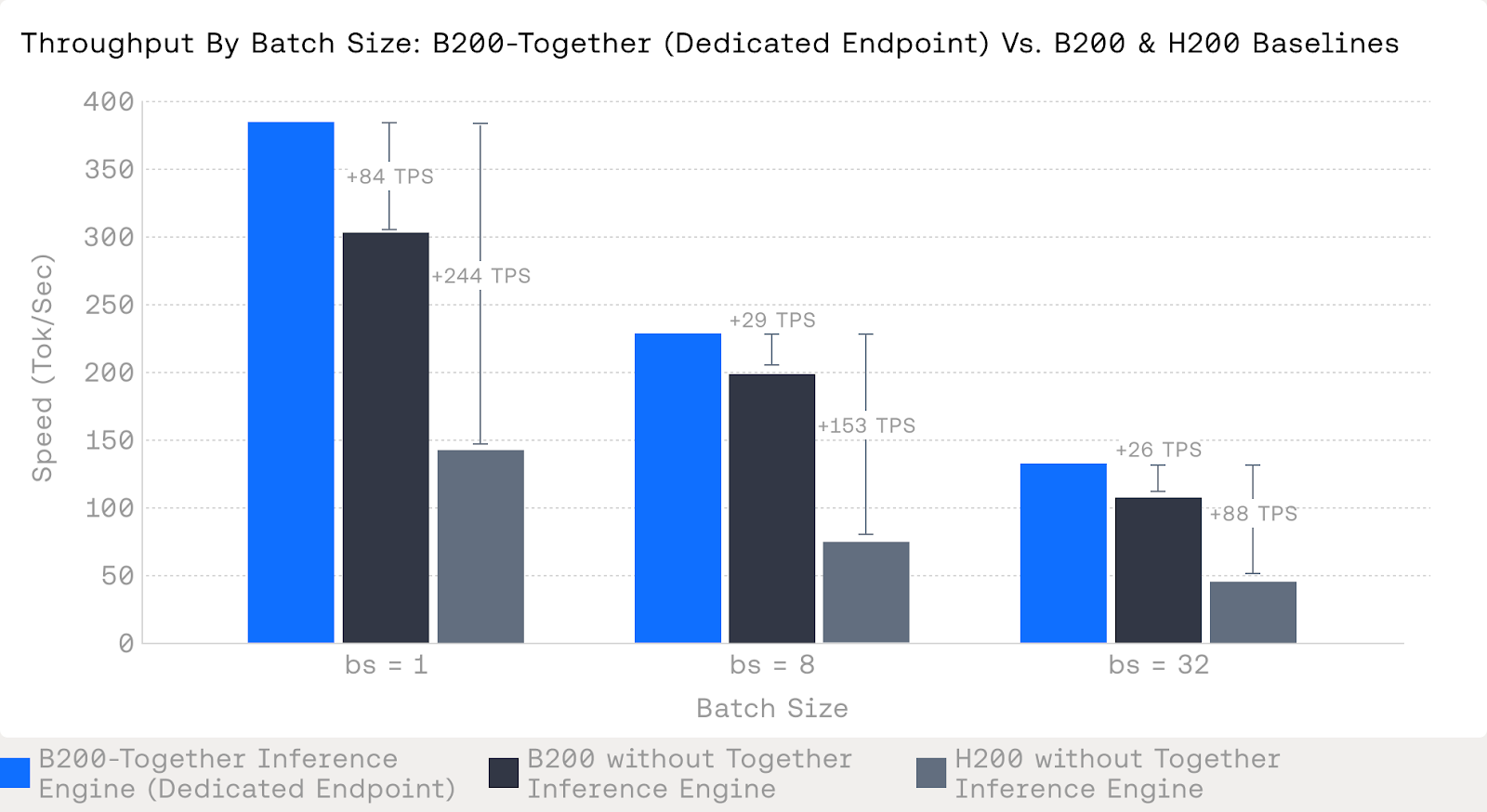
For teams with high-performance production requirements, Dedicated Endpoints (DEs) unlock an additional layer of optimization beyond our default serverless configurations. With DEs, we can fine-tune the deployment environment—delivering up to a ~84 tokens/sec speedup: from 302→386 tokens/s at bs=1, 198→227 at bs=8, and 107→133 at bs=32, compared to deployments without Together’s Inference Engine. These improvements maintain our strict quality–performance standards while giving customers more control over the latency–accuracy trade-off. DEs are ideal for production workloads where every millisecond counts and workloads benefit from infrastructure tailored to their specific needs. (See Appendix for details.)
An Inference Optimization Primer
Below, we break down the key inference optimizations that power Together’s industry-leading performance on NVIDIA Blackwell.
Together Inference Engine
An inference engine is a crucial software or hardware component responsible for executing trained AI models to make predictions on new data. At Together, our inference engine achieves state-of-the-art performance by integrating Together AI's latest advances, including FlashAttention-3, faster custom GEMM & MHA kernels, quality-preserving quantization, and speculative decoding. To reduce computational overhead, we unify this entire inference workflow—from prefill to speculative token verification—into single, dynamically captured NVIDIA CUDA graphs, with efficient compute-communication overlap and parallel stream orchestration to further boost efficiency.
Together Kernels
GPU kernels are custom-developed software programs that run on GPUs, performing critical AI computations such as attention mechanisms and matrix multiplications. By developing optimized kernels, Together AI can unlock faster inference speeds — reducing costs and improving efficiency. With NVIDIA B200 GPUs, Together AI has developed new kernels that take advantage of 5th-generation NVIDIA Tensor Cores and on-chip Tensor Memory. Using the ThunderKittens framework, the Together Kernels Lab built and open-sourced Blackwell GPU kernels matching NVIDIA’s performance within two weeks of getting hardware access. This continues our work on developing kernels that push the state-of-the-art in efficiency, from Flash Attention 3 to custom sparse attention kernels for video.
Together Turbo Speculator
Speculative decoding is a key optimization that significantly accelerates large language models (LLMs). Normally, LLMs decode tokens sequentially, each requiring a full model forward pass. Speculative decoding uses a smaller, faster "speculator" model to predict multiple tokens ahead, which the larger "target" model verifies in parallel.
An ideal speculator is:
- Fast: Minimizing speculative overhead by being smaller and computationally efficient.
- Well-aligned: Generating predictions closely matching the target model’s outputs, measured via acceptance rate.
Together Turbo Speculator outperforms existing open-source speculators–even outperforming DeepSeek-R1-0528’s own 14B Multi-Token Prediction (MTP) module–by leveraging our research team’s insights obtained from developing speculative decoding algorithms, training efficient model architectures, optimizing GPU performance, and curating high-quality datasets.
Our in-house Turbo speculator allows us to overcome an important limitation we observe in the MTP speculator—its acceptance rate degrades significantly as the speculation lookahead—the number of speculated tokens per verification—increases (see figure below). As can be seen below, the Turbo speculator maintains higher target-speculator alignment across the different number of speculated tokens per decode step, which results in faster overall speed. For further details on speculative decoding, read this blogpost.

Together Lossless Quantization
At Together, we’ve pioneered a lossless quantization technique that unlocks the efficiency of NVFP4 & MXFP4/6/8 formats while preserving model accuracy—even in challenging attention layers where other methods falter.
NVIDIA HGX B200 introduces support for ultra-efficient 4-bit formats like NVFP4 (uE2M1). Our approach leverages a W4A4 quantization scheme with NVFP4, strategically sharing a scale across 16 elements to achieve about 4.5 bits per element. This compresses model weights by 3.6x compared to BF16, while retaining best-in-class throughput thanks to native Tensor Core support.
When applied to the Mixture of Experts (MoE) layer on DeepSeek, NVFP4 yields almost no accuracy drop (see table for accuracy details). This success is attributed to Together’s advanced calibration and quantization stack enabling true lossless performance for the entire model.
Real-World Performance, Redefined
Fastest Inference: Our proprietary inference stack achieves up to peak throughput of 334 tokens/sec on our serverless endpoint, outperforming deployments without Together’s Inference Engine by ~32 TPS, while maintaining better performance at higher batch sizes.
State-of-the-Art Inference Stack: Together AI combines NVIDIA HGX B200 with our optimized software stack, including advanced GPU kernels, inference engine, Together Turbo speculators, and quantization techniques (FP4/BF16), to deliver the fastest inference speeds for DeepSeek-R1-0528 in real production environments.
Open-Source Powerhouse: Together AI serves DeepSeek-R1-0528, which matches closed-sourced frontier models in performance.
We will continue to provide industry leading performance with Together’s inference stack and NVIDIA Blackwell, including both HGX B200 and GB200 NVL72.
Contact US
If you are interested in exploring HGX B200 for your workloads, or would like to learn more about how our world-class inference optimization works, we invite you to get in touch with our Customer Experience team.
Footnotes
[1] Each benchmark burst contained 32 arena-hard prompts (≈ 3 k-token completions on average), closely mirroring real production traffic. We report throughput (TPS) as the mean across the burst. This setup contrasts with the CNN/DailyMail dataset used in the TensorRT-LLM blog, and—because speculators are enabled—prompt selection can shift the observed TPS.
Appendix
Quality Results: We evaluated quality using LiveCodeBench v5—a suite of 267 tasks (67 easy, 89 medium, 123 hard, ranging from 08/01/2024 - 02/01/2025). This task is especially sensitive to quantization, unlike benchmarks such as GPQA or AIME, see more on arXiv:2505.02390v1. As shown in Figure 6, the key takeaways based on the LiveCodeBench results are:
- Together-AI on HGX B200 tracks deployments without Together’s Inference Engine nearly point-for-point, while the nvFP4 + strict-MTP configuration lags by a small but consistent margin.
- Relaxed-MTP dramatically widens that gap—introducing unacceptable noise—so all inference speed comparisons use the stricter MTP setting for the deployment without Together’s Inference Engine.

If you are interested in exploring HGX B200 for your workloads, or would like to learn more about how our world-class inference optimization works, we invite you to get in touch with our team.