

When a user asks an AI assistant to analyze a 50-page document, answers that take seconds aren't fast enough. This expectation is reshaping infrastructure requirements across the AI industry. The competitive environment and pace of innovation in AI-native products has fundamentally changed what users consider acceptable — and what businesses must deliver to remain competitive.
This shift isn't just about user experience — it's economics. Inference costs account for the majority of operational expenses in AI-native applications achieving product-market fit and starting to scale. Higher throughput means serving more requests per GPU. Faster token generation means shorter end-to-end response times, which means handling more concurrent users on the same infrastructure. For companies running AI at scale, optimizing time to first token (TTFT) and throughput measured in tokens per second (TPS) can be the difference between sustainable unit economics and burning capital on excess hardware.
Speed is a competitive moat. Faster responses improve retention, enable new use cases, and reduce cost per request. The companies delivering the fastest inference aren't optimizing one layer of the stack — they're rethinking how models, runtimes, and hardware work together. Off-the-shelf inference frameworks leave substantial performance on the table, and closing that gap requires either deep expertise across the full stack — or partnering with platforms that have already invested in it.
Understanding inference economics for AI-native apps
When you're AI native, inference isn't a line item, it's the foundation of your P&L. Unlike traditional SaaS that enjoys near-zero marginal costs, AI applications often face per-request costs that scale with usage. A typical SaaS company targets 80% gross margins;an AI-native product might operate closer to 40-60%.
The compound effect of model orchestration destroys margins faster than most teams anticipate. For example, a coding assistant might trigger many model calls for a single user request: understanding intent, searching documentation, generating code, checking syntax, writing tests, explaining the solution. The features users love most — deeper reasoning, more thorough analysis, cross-referencing multiple sources — are precisely the ones that burn through margins.
The path to profitability requires fundamental improvements in inference efficiency, not just user growth. Every percentage point of optimization directly impacts your bottom line. The technical strategies we'll explore aren't academic exercises. They're the difference between products that scale and products that don't.
Balancing speed and economics in AI inference
Running AI in production means delivering on two fronts: Customer expectations and business fundamentals. These requirements aren't in tension, they're interconnected. Meeting one without the other leads to products users love but can't afford to scale, or efficient systems no one wants to use.
{gated-content-start}
Meeting customer expectations
User experience thresholds are well-documented and unforgiving. Research on eCommerce and lead generation sites shows that a site loading in one second has a conversion rate 3-5x higher than one loading in five seconds. For AI applications where users expect real-time interaction, the tolerance is even lower.
The "streaming illusion" matters: users perceive responsiveness through both TTFT and sustained throughput (TPS). A model that begins streaming within 50 ms and completes in two seconds feels faster than one that pauses 500 ms before outputting tokens, even if their total completion times are identical.
Balancing TTFT and TPS requires understanding your specific use case. Chat applications prioritize TTFT— users need immediate feedback that the system is working. A 50ms TTFT with moderate TPS beats a 500ms TTFT with blazing-fast generation. Code completion tools might accept higher TTFT if the TPS delivers complete suggestions quickly. Document summarization can tolerate seconds of TTFT if the final output arrives fast enough for the workflow.
Your concurrency and volume patterns dictate optimization priorities. High-concurrency, low-volume scenarios (customer support during peak hours) need aggressive batching and TTFT optimization. Low-concurrency, high-volume workloads (overnight document processing) can trade TTFT for maximum throughput. Only after understanding these tradeoffs can you select infrastructure and design optimizations to meet your SLAs.
For interactive applications — code completion, real-time customer support, conversational agents — the bar is <500ms response times. Agentic workflows compound these requirements. A single user query might trigger five model calls in sequence, turning a 200ms per-call latency into a full second of wait time. When each interaction feels slow, the entire experience degrades.
The implication is clear: latency isn't a nice-to-have metric. It's a product requirement that defines what's possible to build.
Improving price-performance
At scale, teams graduate from per-token pricing to managed infrastructure, where speed directly determines cost. When you're paying for GPU-hours, not tokens, the math is simple: faster inference means more requests per GPU-hour. Run inference 2x faster, and you've effectively halved your infrastructure costs. This relationship holds whether you're building on third-party APIs or running your own infrastructure.
The business impact scales with usage. Doubling your user base without doubling inference spend is the difference between linear cost growth and exponential opportunity. For API providers, margin expansion comes from serving more requests per GPU. For AI-native SaaS companies, it's about keeping unit economics favorable as the product scales. A 50ms reduction in latency across millions of daily requests translates to fewer GPUs needed, lower cloud bills, and better capital efficiency.
In a world where the latest generation of GPUs are supply-constrained and expensive, squeezing more throughput from each chip isn't just an optimization, it's a business necessity. Doing more with existing infrastructure delays the need for additional hardware purchases or cloud commitments. Every percentage point of efficiency improvement directly impacts your bottom line.
The four pillars of inference acceleration
Optimizing inference isn't a single problem with a single solution. It's a stack of complementary strategies, each targeting different bottlenecks in the end-to-end pipeline. The companies winning at inference today aren't picking one approach, they're combining all four to create compound performance gains.

Speculative decoding transforms how models generate text. Instead of producing one token at a time, smaller draft models propose multiple tokens the target model verifies in parallel. When successful, this approach can double or triple generation speed without changing model outputs. It's particularly powerful for longer responses where the overhead of drafting pays off quickly.
Optimized kernels squeeze more performance from every GPU cycle. Custom CUDA kernels, operator fusion, and flash attention variants reduce memory movement and computational overhead. These low-level optimizations often deliver 20-40% speedups by eliminating inefficiencies in how operations execute on hardware.
Near-lossless compression shrinks models without sacrificing accuracy. Techniques like 8-bit and 4-bit quantization reduce memory footprint and bandwidth requirements, allowing larger models to fit on smaller hardware and process requests faster. When DeepSeek R1 introduced MLA (Multi-Head Latent Attention), it demonstrated that architectural choices and quantization strategies work together to maintain quality while improving throughput.
Hardware acceleration leverages next-generation GPUs designed specifically for inference workloads. NVIDIA's Blackwell GPUs, with higher memory bandwidth and tensor core improvements, deliver substantial gains over previous generation Hopper GPUs. But hardware alone isn't enough. Systems must orchestrate workloads intelligently to extract maximum value from each chip.
No single pillar solves everything. Compression makes models smaller and faster, but only if optimized kernels can take advantage of reduced precision. Speculative decoding accelerates generation, provided the system is optimized to run both models efficiently on the same hardware. The sections that follow break down each pillar in detail: what it solves, how it works in production, and why it matters for building competitive AI products.
1. Speculative decoding
Speculative decoding addresses a fundamental bottleneck in language model generation. Normally, models generate text sequentially. Each token depends on all the tokens before it, which prevents true parallelism. For large models, most of the latency comes not from computation but from repeatedly moving weights in and out of GPU memory. The model spends more time loading data than thinking.
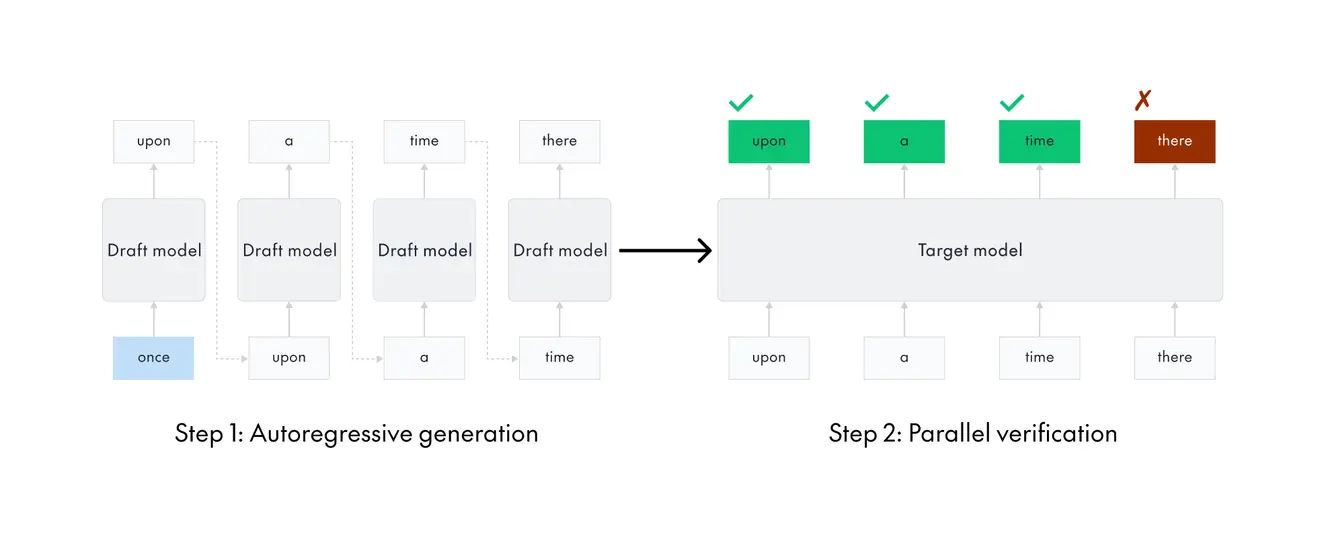
Speculative decoding breaks this pattern by introducing a lightweight draft model that runs ahead of the target model. The draft generates several candidate tokens quickly, and the larger target model verifies them in parallel with a single forward pass. Tokens that match are accepted. Everything after the first mismatch is discarded and regenerated.
The result is faster generation without changing the output distribution. The target model still makes every final decision and the draft model simply proposes likely continuations.
When speculative decoding delivers
The technique shines when the draft model can accurately predict the target's behavior. High-predictability workloads like code completion, structured JSON generation, or templated outputs often achieve 60–80% acceptance rates, translating to 1.5–3x speedups in practice.
The main trade-off is memory. Running two models simultaneously increases GPU utilization and can reduce batch size capacity. That's acceptable for latency-critical single-request workloads, but less efficient for large-batch, high-throughput serving.
Speculative decoding isn't a universal accelerator. But when applied to the right workloads, it transforms sequential generation into near-parallel verification, unlocking substantial performance gains without altering model quality.
Out-of-the-box acceleration
We ship pre-trained draft models optimized for the most widely used base models in production. These speculators integrate directly into existing inference stacks without requiring custom training or tuning. For DeepSeek-R1, our Turbo Speculator delivers measurable speedups right out of the box.
The design prioritizes two qualities: Speed and alignment. Speed comes from using smaller, computationally efficient architectures that minimize overhead. Alignment means generating predictions that closely match the target model's outputs, measured by acceptance rate. The higher the acceptance rate, the more tokens verified per forward pass, and the faster overall generation becomes.
How Turbo Speculator works
Model pairing matters. For a 70B target model, a well-tuned 7B drafter can predict likely continuations without introducing significant latency. The key is maintaining high acceptance rates as the speculation lookahead increases. Lookahead refers to how many tokens the draft model generates before the target model verifies them — higher lookahead means more potential speedup, but only if the draft model remains aligned with the target.
Most open-source speculators struggle here. DeepSeek-R1's own 14B Multi-Token Prediction (MTP) module shows strong performance at low lookahead values, but acceptance rates degrade quickly as lookahead increases. This limits the practical speedup in production workloads where higher lookahead is needed to offset verification overhead.
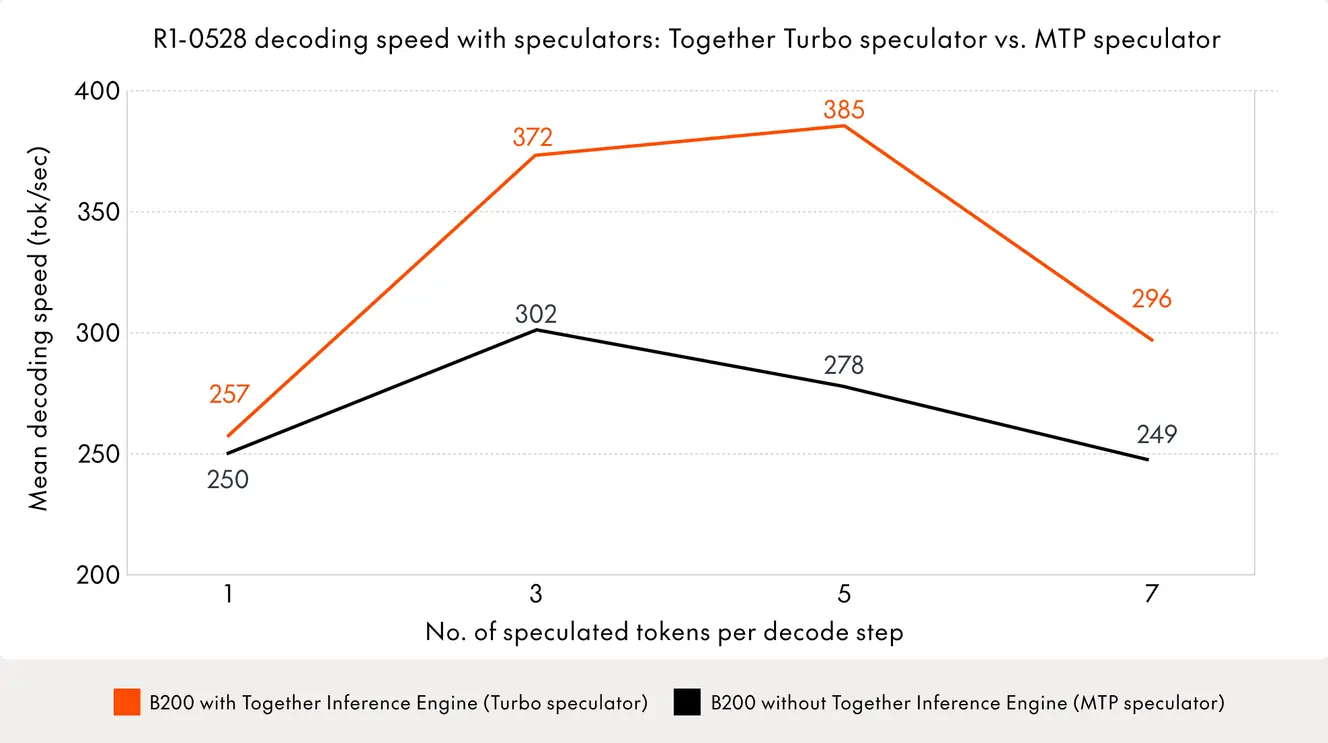
Turbo Speculator solves this by maintaining high acceptance rates even at large lookaheads. The result is consistently faster generation across a wider range of speculation depths. We achieve this through a combination of architecture optimizations, dataset curation, and training techniques developed specifically for speculative decoding.
When to use pre-built vs. custom speculators
Pre-built speculators like Turbo work well for general-purpose tasks where the target model's behavior is relatively predictable. Code generation, structured outputs, and reasoning tasks all benefit immediately. For highly specialized domains or fine-tuned models, custom speculators trained on domain-specific data can push acceptance rates even higher.
The trade-off is development time. Training a custom speculator requires high-quality paired data and careful alignment tuning. For most applications, the pre-built option delivers strong performance without the overhead. When acceptance rates justify the investment, custom speculators become worth building.
Custom speculators: domain-specific acceleration
Pre-built speculators deliver strong baseline performance, but custom speculators trained on domain-specific data unlock significantly higher speedups. By fine-tuning a draft model on actual production traffic, we can push acceptance rates higher and reduce latency even further.
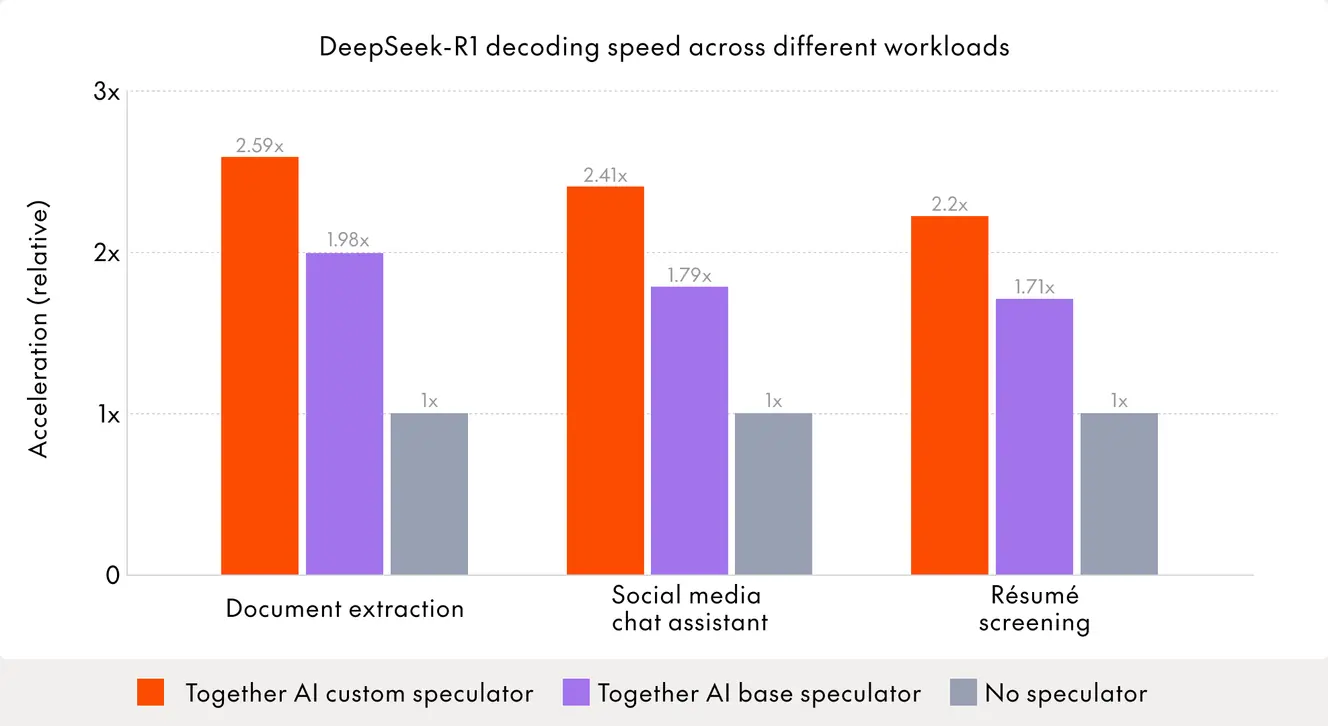
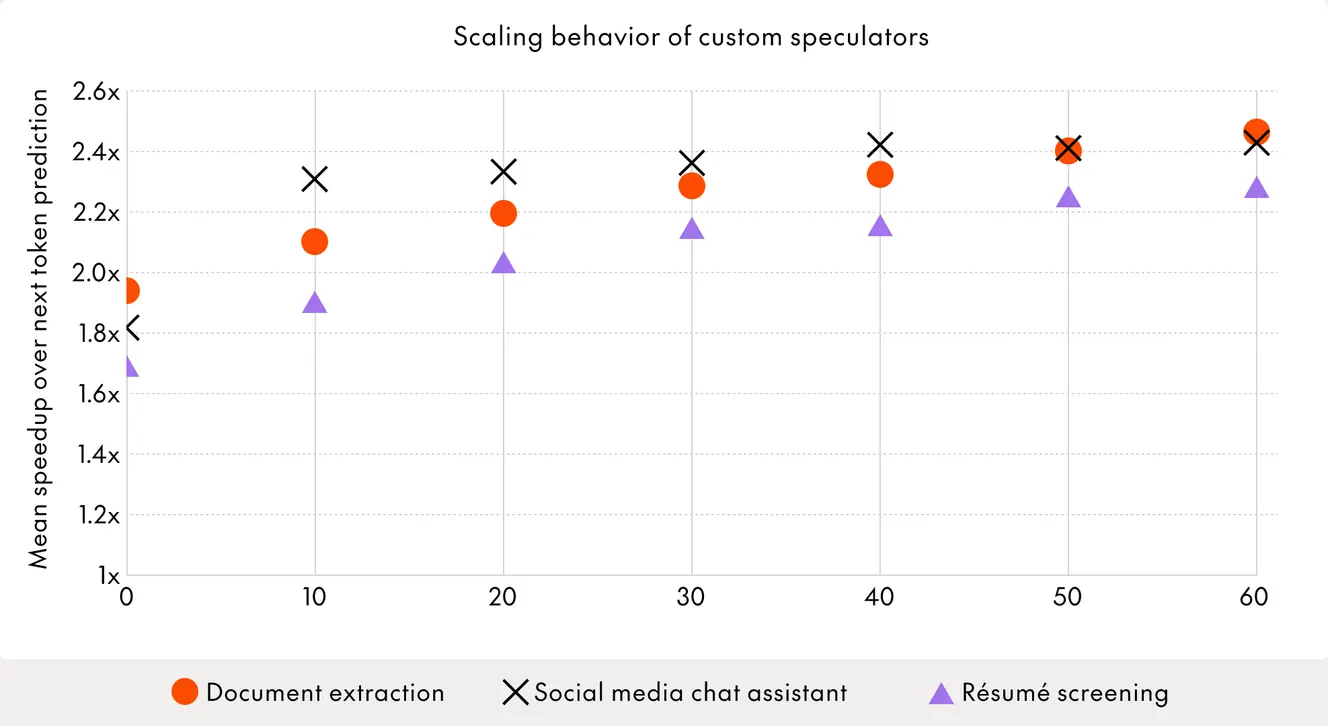
In this example, we deployed custom speculators for three real-world DeepSeek-R1 workloads: document extraction, a social media chat assistant, and résumé screening. These are cost- and latency-sensitive applications where every millisecond matters. Our Base Speculator already achieves 1.44–2.27x speedups over standard next-token prediction. Custom speculators trained on workload-specific data push that further, reaching 1.23–1.45x over the Base Speculator and 1.85–2.97x overall speedups. In absolute terms, that translates to 100–170 tokens per second in production on NVIDIA H100 GPUs.
The training process is straightforward. We collect representative prompts and outputs from customer traffic, then fine-tune the Base Speculator using a proprietary pipeline optimized for target-aware alignment. With as few as 10,000 prompt-response pairs (roughly 20M tokens), we see measurable gains. At 50M tokens, speedups exceed 1.20x over the Base Speculator. As customers continue using our API, this dataset grows organically, and so does speculator performance.
Throughput and cost benefits
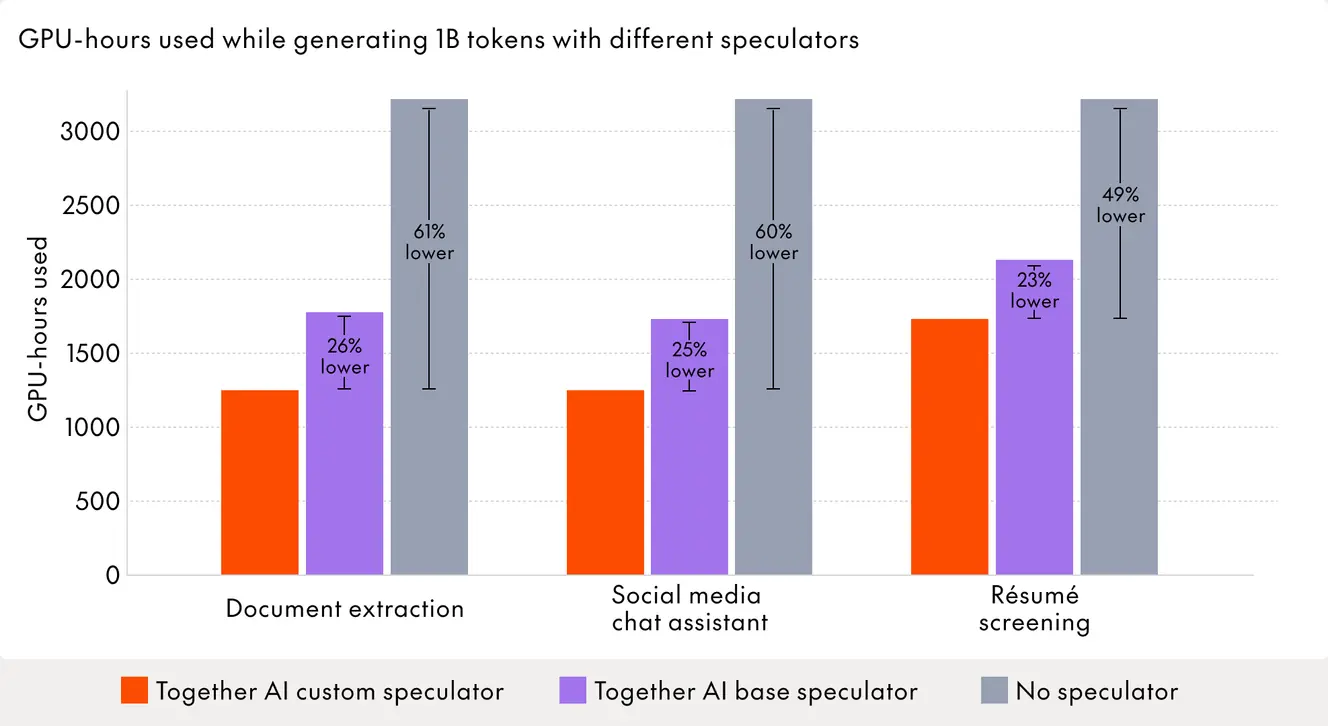
Custom speculators don't just reduce latency. They also increase GPU throughput, which lowers overall inference costs. For enterprise customers processing millions of requests per day, this matters. By using custom speculators, we reduce the GPU hours needed to generate 1 billion tokens by 23–26% compared to the Base Speculator, and 49–61% compared to no speculative decoding at all. Fewer GPUs means lower costs without sacrificing quality.
When custom speculators make sense
The investment pays off when you have consistent, high-volume traffic in a specific domain. If your application generates structured outputs, follows predictable templates, or operates in a narrow task space, a custom speculator will outperform a general-purpose draft model. The key is having enough representative data to capture the target model's behavior in your specific use case.
The limitation of static speculators
Custom speculators capture a snapshot of your workload at training time. They excel at the traffic patterns they were trained on, but as workloads evolve, performance can degrade. Your codebase grows. Traffic patterns shift, request distributions change, and even highly customized speculators can fall behind without retraining.
Standard speculators are trained for general workloads. Custom speculators are trained on your specific data, but only for a specific snapshot in time. Both approaches share the same fundamental constraint: once deployed, the speculator cannot adapt. This problem is particularly pronounced in serverless, multi-tenant environments where input diversity is extreme. New users continuously arrive, bringing unique workloads the fixed speculator may not have seen during training. Furthermore, these speculators typically use a fixed lookahead, predicting the same number of tokens regardless of the speculator's confidence. A static speculator simply cannot keep up.
Adaptive speculators: Real-time learning at scale
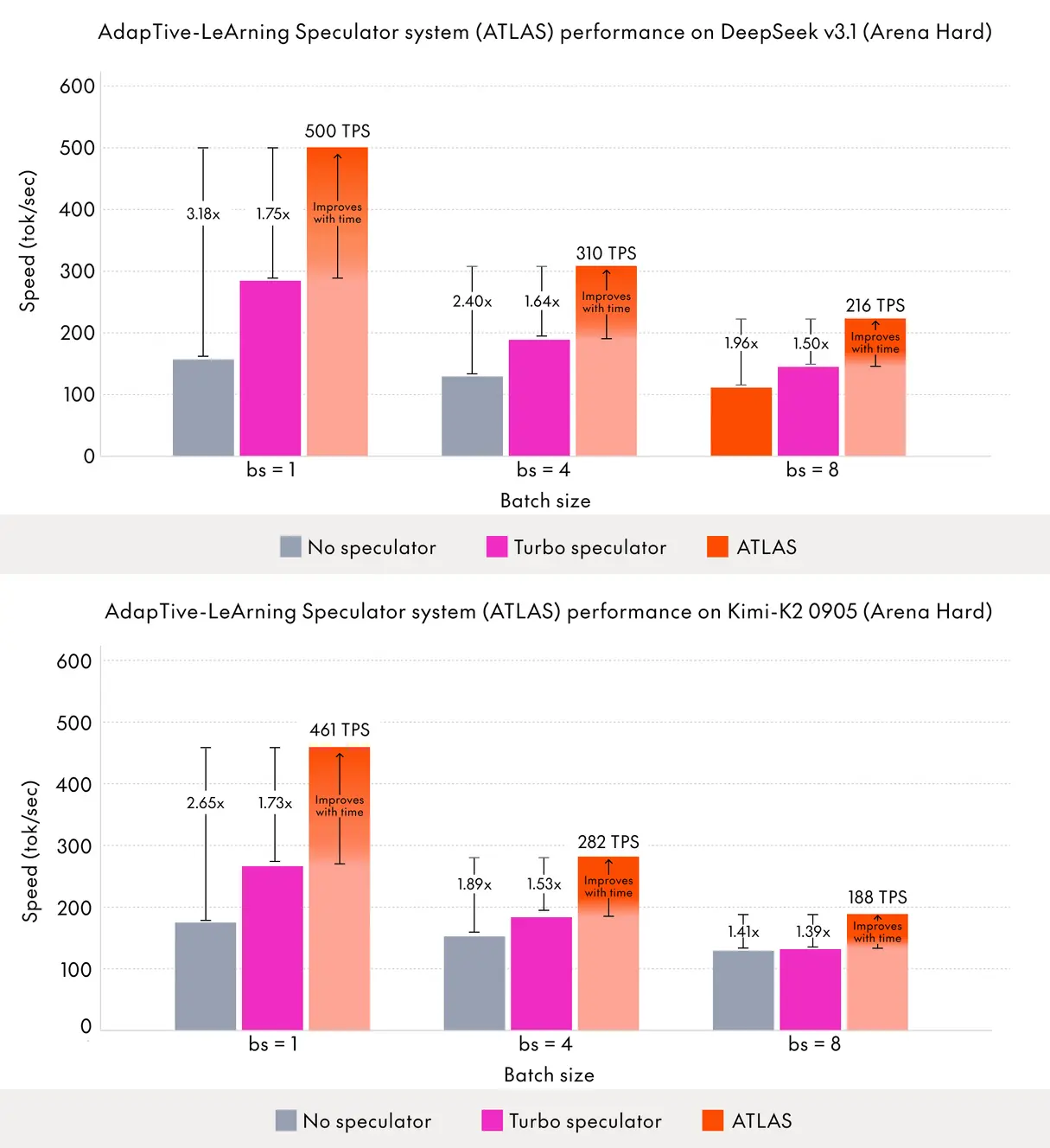
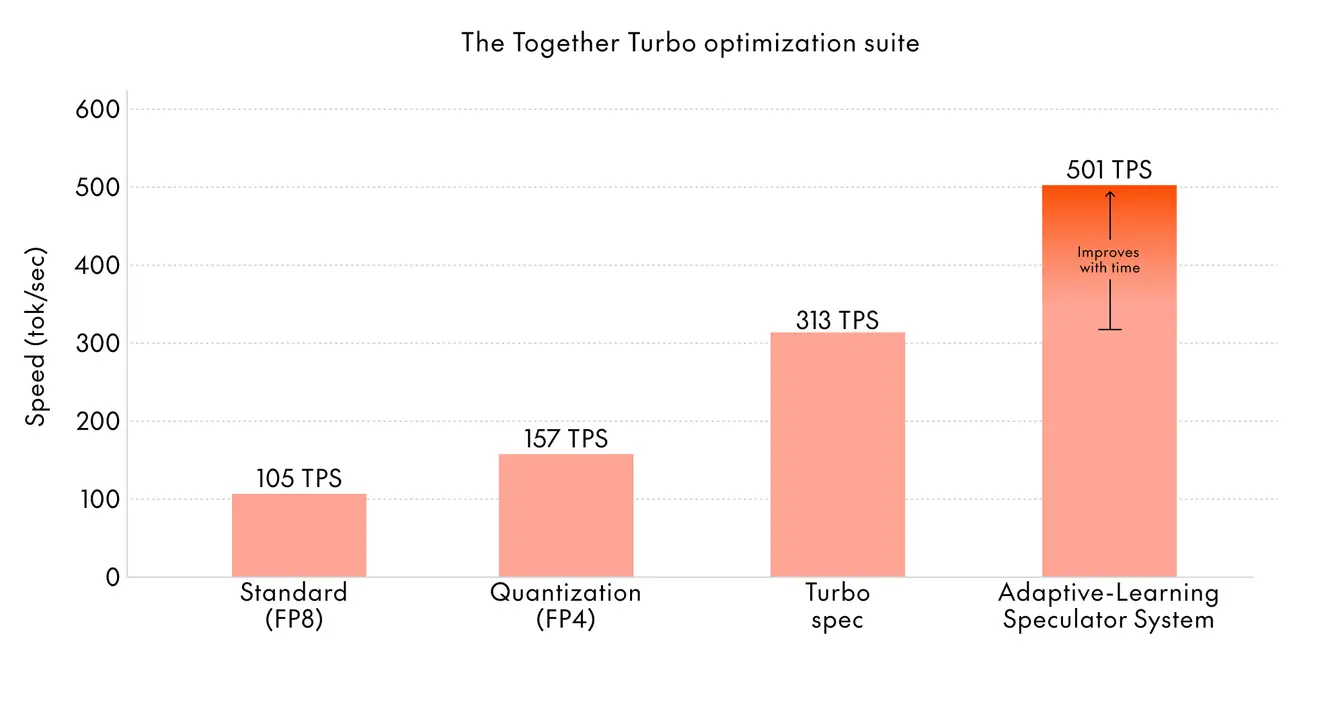
We built ATLAS (AdapTive-LeArning Speculator System) to solve this. It's the first speculator system that dynamically improves at runtime, evolving automatically with usage and learning from both historical patterns and live traffic to continuously align with the target model's behavior in real time. The more you use our inference service, the better ATLAS performs.
Built on top of Together Turbo Speculator, ATLAS reaches up to 500 tokens per second on DeepSeek-V3.1 and up to 460 tokens per second on Kimi-K2 in fully adapted scenarios. That's 2.65x faster than standard decoding — outperforming even specialized hardware like Groq.
The architecture: Two speculators, one controller
ATLAS combines three components working in concert. At the core is a heavyweight static speculator trained on a broad corpus that provides strong, general speculation. This serves as an always-on speed floor. It's trained on diverse data and remains stable across workloads, so throughput doesn't collapse when traffic shifts or the adaptive path is cold. If confidence drops or drift is detected, the system can fall back to the static speculator to preserve latency while the adaptive speculator relearns.
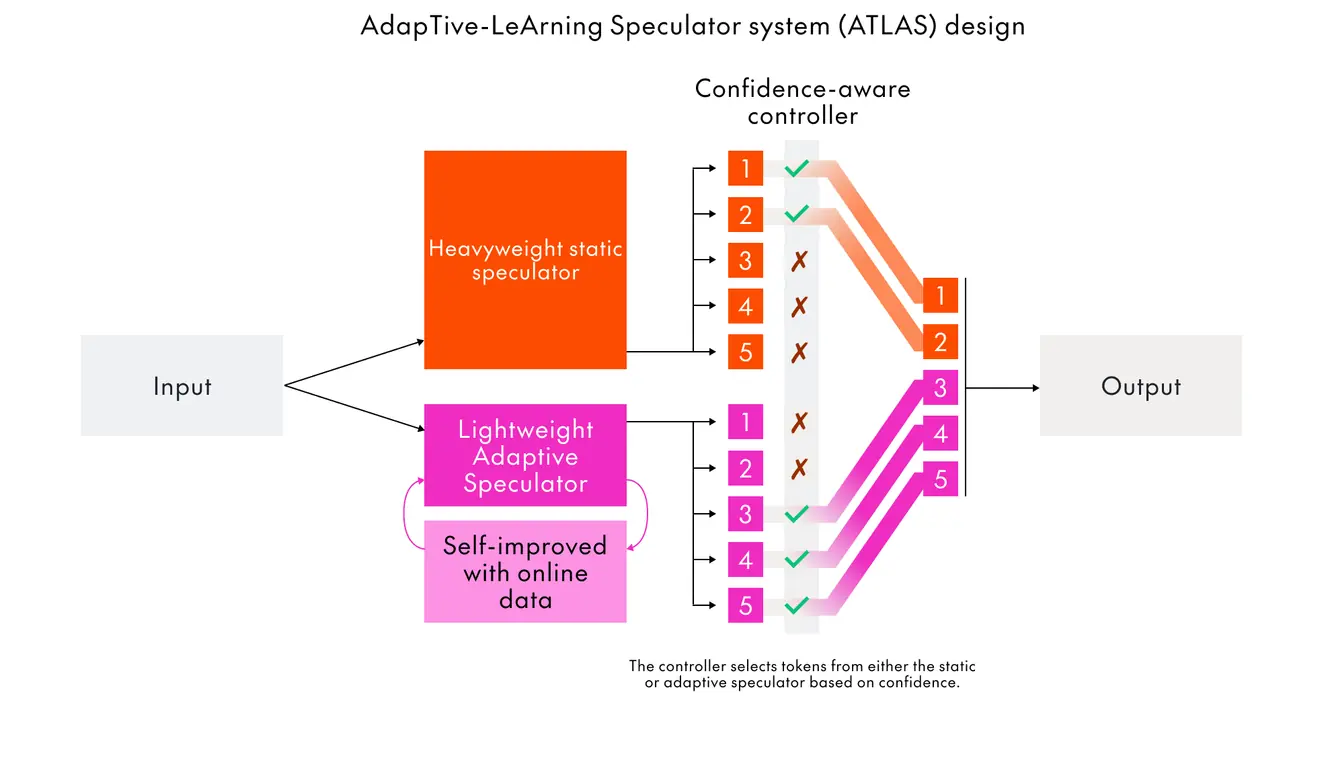
The second component is a lightweight adaptive speculator that allows for rapid, low-overhead updates from real-time traffic. This speculator specializes on the fly to emerging domains. During a vibe-coding session, for example, the adaptive system can tune itself to the specific code files being edited, even if those files were never seen during training. This kind of on-the-fly specialization is impossible with static speculators. The adaptive speculator learns continuously from production traffic, adjusting to new patterns without waiting for manual retraining cycles.
The third component is a confidence-aware controller that chooses which speculator to trust at each step and determines what speculation lookahead to use. When the speculator has high confidence, the controller uses longer speculations to maximize speedup. When confidence drops, it shortens lookahead or routes back to the static path. This dynamic adjustment means the system operates at the optimal point of the speed-accuracy trade-off in real time, adapting to the difficulty of each individual request.
Why adaptive matters in production
Static speculators work well for predictable workloads. Custom speculators work even better when you have consistent traffic in a specific domain. But the most demanding AI-native applications operate at massive scale with dynamic user behavior and rapidly evolving workloads. A fintech platform processing millions of transactions shifts between fraud detection, risk analysis, and customer support throughout the day. A developer tool sees traffic patterns change as codebases grow and new features ship. Even within a single application, user intent varies dramatically from request to request.
ATLAS turns inference into a feedback loop. Every request improves the system. Traffic patterns shift? The adaptive speculator adjusts automatically. A user starts working in a new domain? The system specializes in real time. Code repositories grow and evolve? The speculator tracks those changes without manual intervention.
Customized speculators vs. adaptive learning
We know from our work with custom speculators that training on samples from real traffic delivers meaningful speed boosts. ATLAS enables us to be even more customized, but without the latency of batch retraining. The adaptive system can specialize a lightweight speculator for the exact context it's operating in right now, not the context it saw during training weeks ago.
This creates a compounding advantage for customers using dedicated inference products. Static speculators require periodic retraining to stay current. Custom speculators need new training cycles as workloads evolve. Adaptive speculators stay current by design, improving continuously as you use them. The system captures emerging patterns in real time and adjusts drafting behavior accordingly, maintaining high acceptance rates even as traffic distributions shift.
For high-volume customers, this translates directly to cost savings. Better acceptance rates mean fewer verification steps, which means higher throughput per GPU. As the adaptive speculator learns your specific patterns, you get faster inference and lower costs without lifting a finger.
2. Optimized kernels
GPUs are fast, but stock operations often leave significant performance on the table. The real constraint in transformer inference isn't compute. It's memory bandwidth. Most operations don't generate enough work to saturate the GPU's computational units, especially during autoregressive decoding where batch sizes are small and arithmetic intensity is low. The hardware spends more time moving data than performing calculations.
This is where optimized kernels matter. By improving memory access patterns, fusing operations to eliminate intermediate writes, and reducing kernel launch overhead, custom kernels can deliver 2–5x improvements over stock implementations. For LLM inference, where every token is generated one at a time in a memory-bound regime, these optimizations translate directly to faster generation and lower costs.
Why inference engines live or die by kernel quality
Open-source inference engines like vLLM, TensorRT-LLM, and SGLang have democratized production LLM serving. But under the hood, they all rely on the same fundamental operations: matrix multiplies, attention, layer norms, and activations. The difference between a fast engine and a slow one comes down to kernel implementation.
Most engines ship with reasonable defaults. NVIDIA's cuBLAS and cuDNN provide a solid baseline, and frameworks like FlashAttention have become table stakes. But reaching the performance ceiling requires going deeper. Custom kernels that exploit the specific memory hierarchy of the target GPU, minimize instruction latency, and eliminate unnecessary data movement can unlock 2–3x on top of standard libraries.
The challenge is that writing high-performance kernels is hard. NVIDIA's B200 delivers up to 4.5 PFLOPS of INT8 tensor compute, but reaching that peak requires a deep understanding of Blackwell's memory hierarchy, tensor layouts, and instruction scheduling nuances. The tensor cores need to stay fed, which means managing shared memory bandwidth, avoiding bank conflicts, minimizing address generation costs, and using asynchronous instructions like WGMMA and TMA. Most teams don't have the expertise or time to optimize at this level.
We take kernels seriously
Our inference engine is built on the principle that kernel quality is not negotiable. We maintain a library of hand-tuned CUDA kernels for every critical operation in the inference pipeline. Each kernel is profiled, benchmarked, and iterated on until it saturates the hardware. When NVIDIA releases new architecture features, we rewrite from scratch to take full advantage.
This matters because the gap between a good kernel and a great one compounds across millions of requests. A 20% improvement in attention throughput translates directly to 20% lower latency or 20% higher request capacity. Over the course of a day, that's the difference between needing 100 GPUs or 120.
We don't just optimize for synthetic benchmarks. Our kernels are battle-tested in production, handling real workloads with variable sequence lengths, diverse batch compositions, and mixed precision requirements. The result is an engine that consistently delivers near-theoretical peak performance, even under conditions where other systems degrade.
Thunder Kittens: Open-source kernel optimization
We built Thunder Kittens to make kernel optimization more accessible. It's an embedded DSL within CUDA that provides high-level abstractions for the operations that matter most in AI workloads: matrix multiplies, reductions, and reshapes. Instead of wrestling with WGMMA layouts or TMA descriptors, you work with register tiles and shared tiles that handle the complexity automatically.
Thunder Kittens enforces a tile-based programming model. A "register" isn't a 32-bit word like on old CPUs. It's a 16x16 tile of data, which maps naturally to how modern GPUs actually want to work. The abstraction is simple and constrained, but that constraint matches the hardware. Small matrix multiplies under 16x16 aren't well-supported anyway, and most AI workloads operate on larger tiles.
The library includes optimized implementations of FlashAttention, quantization-aware kernels, and fused operations that reduce memory I/O. With Thunder Kittens, FlashAttention-3 matches cuDNN on B200 GPUs with only 200 lines of code (nearly a 95% reduction vs the full FlashAttention-3 kernel). A Based linear attention kernel hits 215 TFLOPs, or over 300 TFLOPs when accounting for recompute inherent in the algorithm. Qwen3-Next, for example, is a hybrid model that uses linear attention. These aren't experimental research kernels. They're production-grade implementations that run at 75%+ hardware utilization.
Thunder Kittens is open source. The code is available, documented, and designed for researchers and engineers who want to experiment with new architectures or optimize specific operations. If the library is missing something, you can extend it. The abstractions fail gracefully because it's embedded in CUDA, not a separate compiler stack.
Together Kernel Collection: Drop-in performance
For production deployments, we offer the Together Kernel Collection (TKC): highly optimized kernels packaged as native PyTorch-compatible operations that our team can drop directly into the Together inference engine. These are the same kernels that power our platform. They're not experimental. They're enterprise-grade implementations that have been extensively tested and validated across different hardware configurations and workloads.
TKC delivers substantial speedups, particularly in scenarios where PyTorch's standard implementations struggle. FP8 inference operations run roughly 75% faster than standard PyTorch paths. For LLM inference, where skinny-matrix, memory-bound workloads dominate, this matters enormously. Modern LLM decoding processes one token at a time with batch size of one. Arithmetic intensity is low. Memory bandwidth is critical. Kernel launch overhead and synchronization costs become significant.
TKC's kernels are optimized specifically for these challenging conditions. Better memory access patterns maximize bandwidth utilization. Fused operations eliminate intermediate memory writes. Reduced kernel launches through intelligent operation batching cut overhead. FP8 support doubles effective memory bandwidth compared to FP16, which translates directly to faster token generation.
The integration story is straightforward. TKC requires zero code changes to your inference code. It automatically detects and replaces standard operations with optimized implementations. The kernels are compatible with major frameworks like vLLM and TensorRT-LLM, and they include automatic kernel selection based on workload characteristics. Different model architectures have different attention patterns and computational profiles. TKC adapts to these variations without manual tuning.
When kernel optimization pays off
Custom kernels deliver the biggest gains in three scenarios. First, attention mechanisms, which are compute-heavy and memory-intensive. Flash Attention and similar algorithms reduce memory I/O dramatically, but only with careful kernel design. Second, matrix multiplications at small batch sizes, where standard libraries underperform because they can't saturate the hardware. Third, low-precision operations like INT8, FP8, and FP4, where custom kernels can leverage specialized hardware instructions that stock implementations miss.
The investment in kernel optimization makes sense when you're operating at scale. For high-throughput production workloads, even small percentage improvements compound into significant cost savings. For latency-critical applications, faster kernels mean better user experience. For research teams exploring new architectures, optimized kernels unlock experiments that would otherwise be prohibitively expensive.
The key is understanding your bottleneck first. Profile your workload. Identify where time is actually being spent. Start with drop-in solutions like TKC before building custom kernels. Test and validate carefully to avoid regressions. Kernel optimization is powerful, but it's also easy to introduce subtle bugs that only appear under specific conditions.
3. Near-lossless compression for faster inference
Memory bandwidth is the primary bottleneck in LLM inference. During autoregressive decoding, the GPU spends most of its time moving weights and activations between memory and compute units, not performing actual calculations. Lower precision means less data movement, which translates directly to faster inference. The economic impact is substantial: compression lets you fit larger models on the same hardware, reduce GPU count for a given workload, or serve more requests per dollar.
But compression is only valuable if it preserves what matters. The precision trade-off has historically been straightforward. FP16 is the baseline. INT8 offers modest speedups with minimal quality loss. FP8 pushes further, delivering roughly 2x throughput on modern hardware with acceptable degradation on most tasks. But beyond FP8, accuracy typically falls off a cliff. Aggressive quantization to INT4 or lower often introduces unacceptable noise, especially on reasoning-heavy tasks where small errors compound.
The challenge isn't just making models faster —it's making them faster without losing the capabilities you deployed them for. A 2x speedup means nothing if your model no longer handles edge cases or domain-specific reasoning your application depends on. Different tasks have different sensitivity to precision loss. Code generation might tolerate more aggressive compression than medical reasoning. Customer support models might degrade differently than financial analysis models. Pushing quantization this far requires deep expertise in how precision loss propagates through transformer layers and which operations tolerate compression. We've spent years refining these techniques across hundreds of production deployments.
This is why we benchmark every compressed model against your actual workload before deployment. NVFP4 enables 4-bit quantization with a quality that approaches FP8, meaning we can push further without crossing the accuracy threshold that breaks your use case. But even with better quantization formats, validation remains critical. We don't deploy a quantized model until we've verified it meets your quality requirements on representative data.
NVFP4: 4-bit floating point for production
NVFP4 is NVIDIA's 4-bit floating point format introduced with Blackwell architecture. Unlike INT4, which uses fixed-point representation, NVFP4 allocates bits to both exponent and mantissa. This matters for LLMs because weight distributions aren't uniform. Floating point representation handles outliers and dynamic ranges better than integer quantization, which means less quality degradation at the same bit width.
The performance characteristics are compelling. NVFP4 delivers 2–4x speedup over FP8 depending on the workload, with near-lossless quality. On most benchmarks, degradation is under 1%. Memory footprint drops by half compared to FP8, meaning you can run 70B models in the space previously required for 35B models. For memory-bound inference, this effectively doubles your effective hardware capacity.
Take the DeepSeek-R1-0526 for example. We validated this on LiveCodeBench v5, a suite of 267 coding tasks spanning easy, medium, and hard difficulty levels from August 2024 through February 2025. Code generation is particularly sensitive to quantization. Unlike benchmarks like GPQA or AIME — where slight numerical errors may not matter — coding tasks require precise reasoning and structured outputs. A single malformed token can break syntax.
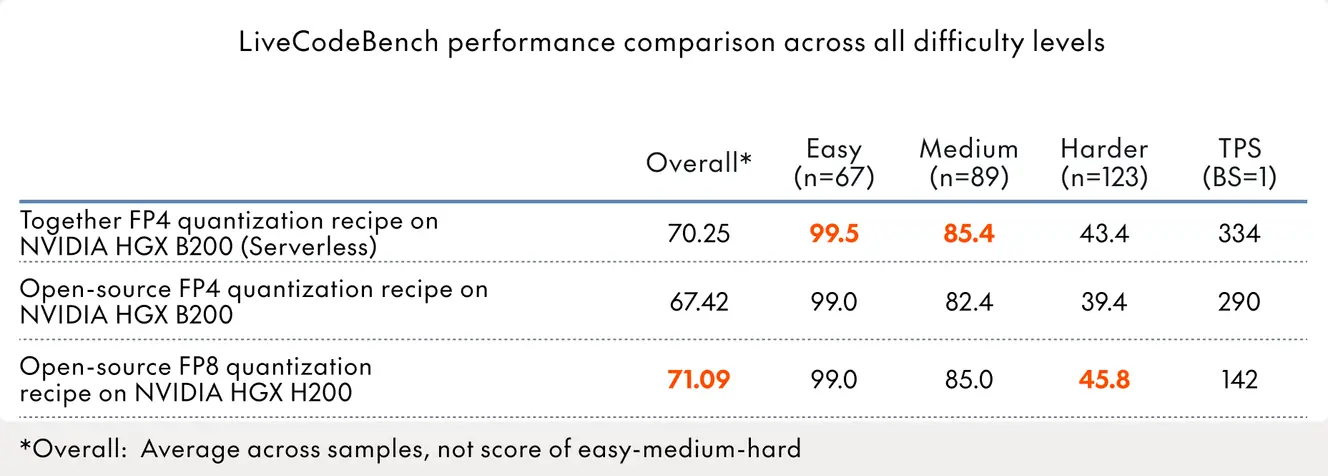
The results show Together's inference engine on HGX B200 tracks unquantized deployments nearly point-for-point across all difficulty levels. On harder problems, where reasoning demands are highest, Together's FP4 quantization strategy maintains 43.4% pass@1, compared to 45.8% for public FP8 implementations and 41.7% for NVIDIA's standard FP4 approach. Overall performance is 70.25%, effectively matching FP8 quality while running at 334 tokens per second on serverless infrastructure.
This is the core advantage: Together's quantization recipe delivers FP8-level quality at FP4 speeds. Standard open-source FP4 quantization can't close this gap. The difference comes down to our approach to calibration. NVIDIA's FP4 format provides the foundation, but reaching production-grade quality requires a custom recipe that recovers the accuracy most implementations leave on the table.
The gap widens only when using relaxed acceptance criteria for multi-token prediction, which introduces too much noise. All production comparisons use strict MTP settings to ensure quality thresholds are met.
Implementation: Making FP4 work in production
NVFP4 is native to Blackwell architecture, where the tensor cores include dedicated instructions for 4-bit floating point operations. On Hopper, FP4 can still work but with reduced benefits since the hardware lacks native support. The calibration process matters. Per-layer quantization strategies can preserve quality better than full-model quantization by keeping sensitive layers at higher precision. Dynamic quantization adapts precision based on activation statistics at runtime, trading some throughput for better accuracy.
The key is task-specific validation. Some applications tolerate aggressive quantization better than others. Chatbots with casual conversation often see minimal impact even at FP4. Code generation and mathematical reasoning are more sensitive. Chain-of-thought prompting can degrade if intermediate reasoning steps accumulate rounding errors. The only way to know is to test on your actual workload.
When FP4 makes sense
NVFP4 excels in three scenarios. First, a large model serving where memory is the constraint. If you're running 70B or 405B models and hitting capacity limits, FP4 doubles effective memory without significant quality loss. Second, batch inference workloads where throughput matters more than latency. Higher throughput per GPU means lower cost per token. Third, cost-sensitive deployments where maximizing utilization per GPU directly impacts economics.
The quantization strategy should be incremental. Start with FP8, and validate quality on your benchmarks. If degradation is acceptable, push to FP4 and validate again. Use per-layer quantization for sensitive operations. Test dynamic quantization if your workload has variable precision requirements — and build testing frameworks that catch regressions early, before they reach production.
Quantization is not a one-size-fits-all optimization. It's a precision tool that requires careful calibration and validation. But when applied correctly, it unlocks performance and cost improvements that would be impossible through software optimizations alone. NVFP4 makes 4-bit quantization practical for production LLM deployments, delivering speed without unacceptable quality compromise.
4. Hardware as the performance multiplier
Software optimizations have limits. You can write the perfect kernel, implement flawless speculative decoding, and quantize aggressively, but ultimately silicon determines the ceiling. The gap between Hopper and Blackwell isn't just "faster." It's a different class of capability that makes previously impractical optimizations production-ready.
Why NVIDIA Blackwell changes the equation
Blackwell delivers 2.5x more FP8 compute throughput and doubles memory bandwidth from 4TB/s to 8TB/s. But the real story is how these improvements compound with the optimizations we've discussed.
Native FP4 support. On Hopper, FP4 quantization is emulated, which limits practical speedups. Blackwell's tensor cores include dedicated FP4 instructions, turning "technically possible" into "production viable." This is why our NVFP4 results show 334 TPS on Blackwell serverless infrastructure while maintaining quality. That level of performance would require significant quality compromises on earlier hardware.
Memory bandwidth for speculative decoding. Speculative decoding requires running two models simultaneously: a draft model and target model. Memory bandwidth determines how quickly you can load weights for verification. Blackwell's doubled bandwidth means higher acceptance rates translate more directly to end-to-end speedup. The same speculative decoding strategy that delivers 1.5x gains on Hopper can push 2-3x on Blackwell because the hardware can actually keep up with the draft model's output.
Tensor core improvements for attention. Flash Attention and other optimized kernels rely on keeping tensor cores fed. Blackwell's enhanced tensor cores have deeper pipelines and better support for the WGMMA instructions that our kernels depend on. This means kernels that run at 75% utilization on Hopper can approach 85-90% on Blackwell without changing a single line of code.
Real-world impact: Where performance compounds
For DeepSeek-R1 inference, the difference between generations is dramatic. At batch size 1, the latency-critical regime where most interactive applications operate, Together's optimized B200 deployment reaches 386 tokens per second on dedicated endpoints. That's 2.7x faster than H200 without Together's inference engine, which manages only 142 TPS. Even B200 without our optimizations hits 290 TPS, demonstrating that hardware alone delivers substantial gains.
But the real story emerges when you layer optimizations on top of better hardware. B200 with Together's full stack (speculative decoding, custom kernels, FP4 quantization) delivers 84 TPS more than B200 baseline at batch size 1. At batch size 8, the gap is 29 TPS. At batch size 32, it's 26 TPS. These aren't just additive improvements. They're multiplicative. Better hardware makes better algorithms possible, which extracts more from the hardware, more sophisticated algorithms.
%20by%20Batch%20Size_%20B200-Together%20(Dedicated%20Endpoint)%20vs.%20Baselines.webp)
The throughput curve tells another story. At batch size 1, where memory bandwidth matters most, the gap between optimized B200 and unoptimized H200 is massive. As batch size increases to 8 and 32, performance converges somewhat because you're saturating memory bandwidth regardless of optimization quality. But even at batch size 32, where compute starts to dominate over memory, Together's B200 deployment maintains a 26 TPS advantage over baseline B200 and an 88 TPS advantage over H200.
Dedicated Endpoints: Tuning for production
For teams with high-performance production requirements, Dedicated Endpoints unlock an additional layer of optimization beyond our serverless configurations. With dedicated infrastructure, we can fine-tune the deployment environment to your specific workload characteristics. This delivers up to 84 tokens per second speedup at batch size 1 (302→386 TPS), 29 TPS at batch size 8 (198→227 TPS), and 26 TPS at batch size 32 (107→133 TPS), compared to deployments without Together's inference engine.
These improvements maintain strict quality standards while giving customers more control over the latency-accuracy trade-off. Dedicated endpoints are ideal for production workloads where every millisecond counts and where infrastructure can be tailored to specific traffic patterns. If you're running code generation at high volume, we can optimize for that. If you're doing batch processing with consistent request shapes, we can tune accordingly. The hardware capability is the foundation, but dedicated tuning extracts the maximum from it.
What this means for production
Hardware isn't a separate optimization axis. It's the foundation that determines which software optimizations are viable. On Hopper, aggressive FP4 quantization introduces too much quality degradation for production use. On Blackwell, it becomes practical. Speculative decoding with larger draft models becomes feasible because memory bandwidth can support it. Custom kernels can push higher utilization because the tensor cores have headroom.
The platforms that win aren't just buying new GPUs. They're redesigning their inference stack to exploit new capabilities. This is why our approach emphasizes full-stack optimization: speculative decoding algorithms designed for Blackwell's memory characteristics, kernels written for its tensor core pipeline depth, quantization strategies that leverage native FP4 support. Each optimization is built with the hardware in mind, and the hardware makes each optimization more effective.
Conclusion: The compounding advantage
Inference optimization isn't a single lever you pull. It's a system of interdependent techniques that compound when designed together. Speculative decoding works better with custom kernels because those kernels reduce verification overhead. FP4 quantization works better on Blackwell because the hardware has native support. Custom speculators work better when they're trained with knowledge of the kernel implementations they'll run on. Each optimization multiplies the others.
This is why deep expertise matters. Building a competitive inference stack requires understanding the full vertical: silicon characteristics, memory hierarchies, instruction scheduling, quantization calibration, speculative decoding algorithms, and model architecture patterns. Most teams don't have dedicated inference engineering groups with expertise across this range. Even large AI companies often treat inference as an afterthought, focusing engineering resources on training and model development while relying on off-the-shelf serving frameworks.
The gap between generic inference and optimized inference is massive. These aren't incremental gains: they're the difference between a product that feels sluggish and one that feels instant. They're the difference between profitable unit economics and burning capital on excess hardware.
The integrated approach means co-designing across layers. Our speculators are trained with knowledge of how our kernels handle memory layouts. Our quantization strategies account for which operations have optimized FP4 implementations, and our scheduling logic understands Blackwell's memory bandwidth characteristics. When you control the full stack, you can make trade-offs that aren't possible when integrating disparate components.
Why this matters for AI-native companies
Speed is a competitive moat. Users notice the difference between 150 TPS and 380 TPS. That's the gap between a response that feels like a conversation, and one that feels like waiting for a page to load. For coding assistants, it's the difference between real-time suggestions and interrupting flow. For customer support, it's the difference between instant answers and visible latency. Speed shapes user experience, which shapes adoption, which shapes business outcomes.
Cost matters too. Running DeepSeek-R1 at 380 TPS instead of 150 TPS means you need 60% fewer GPUs for the same traffic. At scale, that's millions of dollars in infrastructure costs — not to mention operational simplicity. Fewer GPUs means less complexity in orchestration, networking, and reliability engineering. The optimization effort pays for itself quickly when you're serving millions of requests per day.
But optimization isn't static. New models ship with different architectural patterns. Hardware evolves. Workloads change as products mature. The inference stack that's optimal today won't be optimal in six months. Staying ahead requires continuous investment in profiling, benchmarking, and tuning. It requires teams that understand the latest research on speculative decoding, the newest quantization techniques, and the characteristics of upcoming hardware generations.
Next steps
If you're building AI-native applications at scale, you face a build versus partner decision. Building in-house gives you control but requires dedicated engineering teams with specialized expertise. Partnering gives you immediate access to state-of-the-art optimizations but means relying on external infrastructure. The right choice depends on your scale, engineering resources, and strategic priorities.
For teams evaluating their inference strategy:
Profile your current stack. Understand where time is actually being spent. Is it prefill or decode? Memory bandwidth or compute? Kernel overhead or scheduling latency? You can't optimize what you don't measure.
Identify quick wins. Some optimizations deliver immediate value with minimal risk: upgrading to Blackwell if you're on Hopper; adopting FP8 quantization if you're running FP16, and implementing basic request batching if you're processing one at a time.
Evaluate strategic partnerships. If inference performance is critical to your product and you don't have a dedicated optimization team, partnering with a platform that has invested in full-stack optimization can accelerate time to market and reduce operational burden.
The inference landscape is evolving rapidly. New models, new hardware, new optimization techniques. The platforms that win will be the ones that treat inference as a first-class engineering problem, not an afterthought. Speed isn't just a feature. It's a fundamental product quality that shapes everything downstream.