
Model customization is an extremely versatile tool that comes in handy for many kinds of AI developers. For instance, you can make the strongest open LLMs even better on business-critical tasks by fine-tuning them on domain-specific data. Moreover, it's possible to drastically reduce both inference costs and latency via training smaller but equally capable models.
Our goal with the Together Fine-Tuning Platform is to streamline the process of model training for AI developers, helping them quickly build the best models for their applications by offering convenient and affordable tools. This release showcases a new package of improvements, drastically expanding the scope of what you can train: from the native support for over a dozen latest LLMs to new DPO options and better integrations with the Hugging Face Hub. Learn more about the new features in this blog post!
Large models at Together AI
In 2025, we have seen a great number of models with over 100B parameters released to the public. These models, such as DeepSeek-R1, Qwen3-235B, or Llama 4 Maverick, offer a dramatic jump in capabilities, sometimes rivaling even the strongest proprietary models on certain tasks. With fine-tuning, you can further refine the abilities of these models, steering them towards the precise behavior you need or showing how to solve complex tasks by providing SFT demonstrations. However, training large models is a challenging matter: even orchestrating multi-node jobs reliably can be non-trivial, and running them efficiently requires huge time investments across the stack.
Now, you can train the latest large models on the Together Fine-Tuning Platform! By implementing the latest training optimizations and carefully engineering our platform, we made it possible to easily train models with hundreds of billions of weights at a low cost. We have recently announced the general availability of OpenAI's gpt-oss fine-tuning on our platform, and now we support even more model families, covering recent releases by DeepSeek, Qwen, and Meta.
The full list of new large models is as follows:
- openai/gpt-oss-120b
- deepseek-ai/DeepSeek-V3.1
- deepseek-ai/DeepSeek-V3.1-Base
- deepseek-ai/DeepSeek-R1-0528
- deepseek-ai/DeepSeek-R1
- deepseek-ai/DeepSeek-V3-0324
- deepseek-ai/DeepSeek-V3
- deepseek-ai/DeepSeek-V3-Base
- Qwen/Qwen3-Coder-480B-A35B-Instruct
- Qwen/Qwen3-235B-A22B (context length 32768 for SFT and 16384 for DPO)
- Qwen/Qwen3-235B-A22B-Instruct-2507 (context length 32768 for SFT and 16384 for DPO)
- meta-llama/Llama-4-Maverick-17B-128E
- meta-llama/Llama-4-Maverick-17B-128E-Instruct
- meta-llama/Llama-4-Scout-17B-16E
- meta-llama/Llama-4-Scout-17B-16E-Instruct
Unless stated otherwise, we support a context length of 16,384 tokens for SFT and 8,192 tokens for DPO training. Once the training run finishes, you can start a Dedicated Endpoint to run inference for these models, as well as download their final or intermediate checkpoints.
See the complete list of models supported for fine-tuning in our docs, and check out the pricing page for details about the cost of fine-tuning 100B+ parameter models.
Context length extensions
With recent progress on tasks such as long-document processing, editing of large codebases, and agentic interaction chains, reliable handling of long contexts is as important as ever. Ideally, you want these long examples to be present in your training data, as this eliminates the test-time domain mismatch, boosting the results on the target task.
Given this trend, we wanted to make it possible for AI developers to harness long-context abilities in fine-tuning. To make this happen, we have overhauled our training systems and identified ways to increase the maximum supported context length for most of our models — at no additional cost to you. On average, you can expect 2x-4x increases to the context length, with some settings (like Llama 3.1-8B or Gemma 3-4B) jumping to their maximum length of 131k tokens.
See the picture below for the example context length increases:
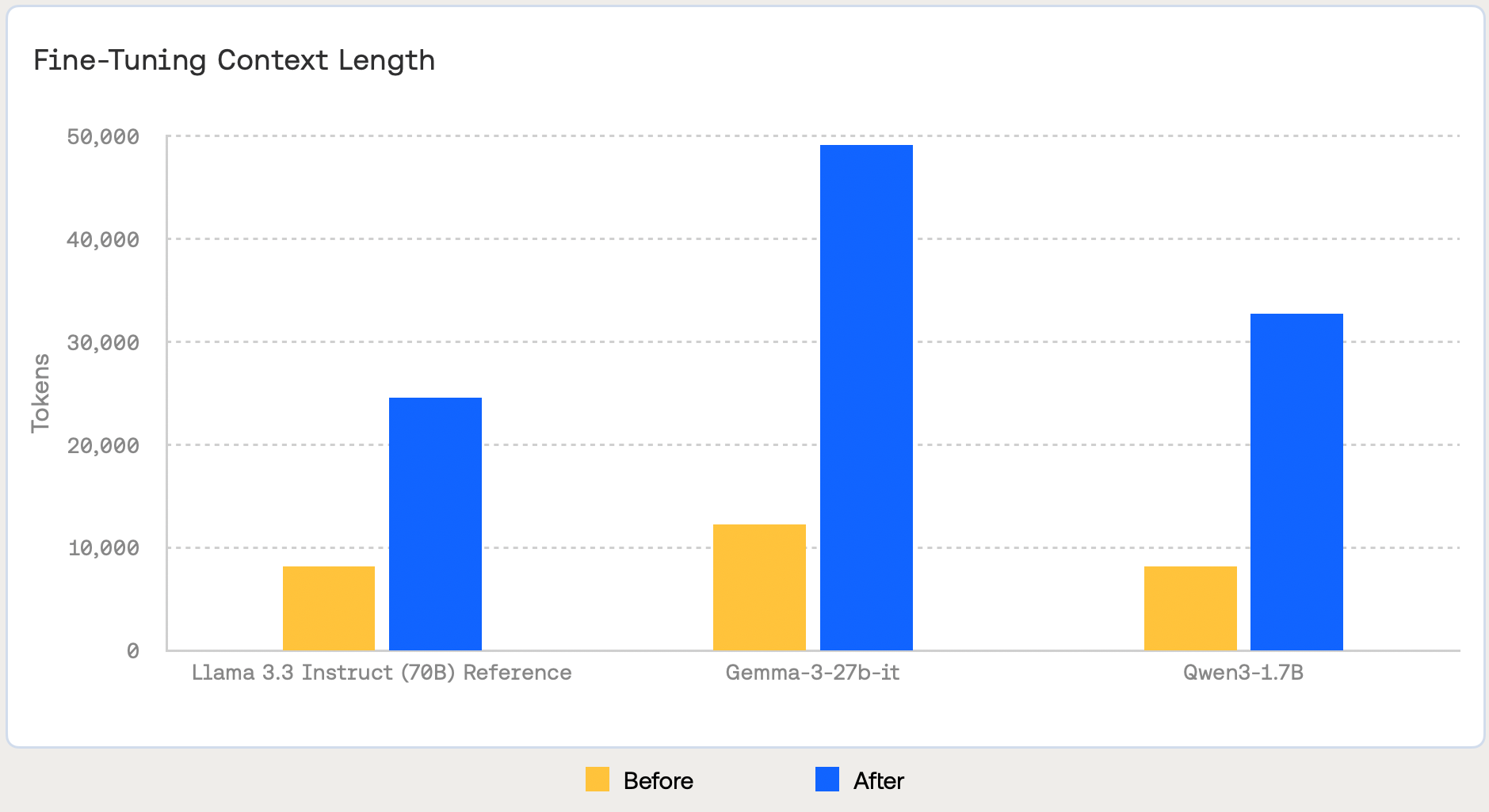
Slingshot AI, the company behind the AI therapy app Ash, built a foundation model for psychology and fine-tuned it with long-context clinical conversations. For their use case, long-context fine-tuning was essential to capture the full scope of these conversations.
"The technical challenge was running our multi-stage pipeline reliably at the conversation lengths our therapy models require," explains Daniel Cahn. "Together AI's platform eliminated the context length constraints and job failures we hit elsewhere, letting us experiment rapidly." - Daniel Cahn, Co-founder & CEO, Slingshot AI
For some of the larger models like Llama-3.3-70B, we also offer a separate option of full-context fine-tuning. See the complete list of such models, as well as the context lengths we support, in the docs.
Our work here is far from done: as we discover and implement additional optimizations of our training systems, we will push for larger context lengths (even for 100B+ models) while aiming to keep the runtime and costs of training low. If you need long-context training for a model that is currently missing or need to further increase the context length, we would love to learn more about your use case and support it!
Fine-tune your own model, upload to HF Hub
Given the tempo of acceleration in AI nowadays, you can often see increasingly stronger models trained for specific tasks and released nearly every single day by the community. Some of these models are further fine-tuned variants of base models released by companies like DeepSeek or Meta, while others have a similar architecture but a different configuration or were trained from scratch. No matter the setup, it is almost a given that these models are published on the Hugging Face Hub — the most popular choice for hosting checkpoints these days.
Today, we are making this plethora of models from the Hugging Face Hub available for fine-tuning through Together AI! Our reasoning was simple: if there exists a model that's already adapted for a relevant task, you should be able to use it as a starting point for further fine-tuning. Similarly, you can also save the outputs of your runs directly into a repository on the Hub. Just specify the HF API key with the appropriate permissions (either when starting your job or in your Together AI profile on the website), and your runs will be able to read or write any checkpoints that this key can access.
Our pioneer customers, such as Slingshot and Parsed, have already been using this feature for training their best models, seamlessly integrating the Together Fine-Tuning Platform into their pipelines by using the Hugging Face Hub as an intermediate step. Now, we're making this feature available for every user of Together AI.
To showcase how you can start training models from the Hugging Face Hub and upload the final model to your organization, read our deep-dive blog post, written in partnership with Hugging Face. Keep in mind this feature is experimental and best-effort: while we are continuously stress-testing our platform against a broad variety of models, expect some rough edges for more exotic setups. For a detailed description of Hugging Face integrations, you can also refer to our guide in the docs!
Further improvements
We are also expanding the support for Preference Optimization with more advanced training objectives, inspired by training recipes of state-of-the-art models that used DPO variants. In particular, we now support variants such as length-normalized DPO (LN-DPO), DPO+NLL (from the Iterative RPO paper), and SimPO through corresponding flags --dpo-normalize-logratios-by-length, --rpo-alpha, and --simpo-gamma. Depending on the target setting, you can combine those options to arrive at the best setup for training on preference data. ****
Lastly, we now fully support batch_size="max" when starting your jobs through the API or the Python client. It is a convenience option that will always set the batch size to the highest value we support on the platform, regardless of the model or the training mode (SFT or DPO). We highly recommend keeping the batch size set to max , unless you need to control it for your experiments. This way, you'll automatically benefit from further training optimizations as we roll them out.
Looking ahead
At Together AI, we aim to offer the best set of tools for engineers and researchers working with large language models. With the latest set of additions to our Fine-Tuning Platform, you can easily kick off even the most demanding and sophisticated training runs with little manual effort. At the same time, thanks to our research in ML systems, running experiments via Together AI is remarkably fast and cost-effective, which helps you turn fine-tuning into a natural part of your AI development cycle.
We are thrilled to see what you will build with the features and models we've added! As always, if you have any feedback about fine-tuning at Together AI or want to explore it for your tasks in more depth, feel free to reach out to us!