
TL;DR: In our new ICML 2025 paper, we proposed Mixture-of-Agents Alignment (MoAA) as an effective post-training approach that harnesses the collective intelligence of open-source large language models (LLMs). Building on our previous work where Mixture-of-Agents ensembles outperformed GPT-4o, MoAA now achieves this collaborative advantage in a single, efficient model. We released our paper, SFT data along with the model weights for Llama-3.1-8B-Instructt-MoAA-SFT, Llama-3.1-8B-Instructt-MoAA-DPO, Gemma-2-9b-it-MoAA-SFT, and Gemma-2-9b-it-MoAA-DPO.
Around a year ago, we demonstrated the power of the Mixture-of-Agents approach: a combination of open-source models substantially outperforms GPT-4o in chat tasks, which we detail in our blog post and subsequent research paper (ICLR 2025 Spotlight). We are thankful for the community’s feedback and excitement on this concept. While MoA delivers state-of-the-art performance, its practical deployment faces two critical limitations: elevated computational costs and architectural complexity. To address these challenges, we present Mixture-of-Agent Alignment (MoAA), a novel distillation framework that synthesizes the collective intelligence of multiple models into a smaller yet more efficient LLM. Our experiments show that MoAA empowers smaller models to achieve performance levels comparable to those of models up to 10x their size, while retaining the efficiency and cost advantages of small models.
To illustrate the effectiveness of our method, we compare MoAA-developed language models with popular open-source models of much larger size. Models trained with our method show promising performance and are even competitive against models 10 times their size.
.png)
MoAA highlights the practical potential of open-source language models and underscores the impact of community-driven development in advancing AI capabilities. By harnessing the complementary strengths of diverse models and distilling them into a compact, efficient system, we move closer to realizing more accessible and scalable AI solutions.
The remainder of this post will delve into MoAA's key architectural elements and explore its integration into a self-improving model development pipeline, unlocking new pathways for iterative AI advancements.
The MoAA Recipe
.png)
Experimental Setup
In our experiments, we fine-tune two base models, namely Llama-3.1-8b-Instruct and Gemma-2-9b-it, and assess their performance on three challenging alignment benchmarks: AlpacaEval 2, Arena-Hard, and MT-Bench. These benchmarks utilize a direct comparison approach, where each model's response is paired against GPT-4's response, and a GPT-4-based evaluator determines the preferred response, thereby ensuring a consistent and high-quality evaluation.
MoAA-SFT — Use MoA to generate high-quality supervised fine-tuning data
Our model alignment process starts by generating high-quality responses that leverage the collective knowledge and capabilities of multiple open-source models. For each instruction or query, we first gather responses from a diverse set of open-source models, referred to as proposers in the Mixture-of-Agents (MoA) framework. These proposed responses are then synthesized by another open-source model, known as the aggregator in MoA. Specifically, the proposers used in our study are WizardLM-2-8x22b, Gemma-2-7b-it, Qwen-2-72b-Instruct, and Llama-3.1-70b-Instruct, while Qwen-1.5-110b-Instruct serves as the aggregator. To demonstrate the effectiveness of our approach, we subsample from two widely used open-source instruction tuning datasets: UltraFeedback and UltraChat. Our subsampling strategy involves utilizing the entire UltraFeedback dataset and randomly selecting 5,000 samples from UltraChat.
To demonstrate the efficacy of this synthetic dataset, we employ Supervised Fine-Tuning (SFT) to train our smaller target models, namely Llama-3.1-8b-Instruct and Gemma-2-9b-it. Through this process, the smaller models are able to leverage the collective knowledge of the larger models, effectively distilling their combined expertise.
.png)
As evident from the above table, our SFT models exhibit significant improvements over the baseline models. Notably, the SFT model trained on Llama-3.1-8b-Instruct surpasses most existing models of comparable size, with the exception of Gemma-2-9b-it. Moreover, the SFT model trained on Gemma-2-9b-it emerges as the top-performing model among its peers, and its performance is remarkably close to that of Llama-3.1-70b-Instruct.
.png)
More significantly, our method surpasses the performance of Llama-3.1-8b-Instruct fine-tuned using responses from stronger models, such as GPT-4o, on the same dataset. This outcome provides compelling evidence that our approach generates higher-quality synthetic data compared to GPT-4o. These findings suggest that our method can effectively distill a substantial portion of the Mixture-of-Agents' (MoA) capabilities into a more compact model.
In terms of cost, our MoA synthetic data is more cost-effective than using closed-source model such as GPT-4o. To generate the entire UltraFeedback subset, which has roughly 60k examples, our MoA method requires 366 US dollars, whereas GPT-4o requires 429 US dollars. This is a 15% decrease in cost while having better performance.
MoAA-DPO — MoA for Direct Preference Optimization
DPO with a reward model
Building upon the strong foundation established by synthetic data generation and SFT, we discovered that further refinement through preference alignment can substantially boost the performance of our distilled model. To achieve this, we first generate preference data using the Mixture of Agents (MoA) as a reward model, and then employ Direct Preference Optimization (DPO) to further enhance performance.
To prepare the data for DPO, we sample 5 responses from the previously trained SFT model and use a reward model to select the preferred and rejected responses for preference learning. Specifically, we utilize the reward model to identify the highest-scoring response as the "chosen" response and the lowest-scoring response as the "rejected" response for each method, and here we propose a novel technique that leverages MoA as a reward model. Our results demonstrate that in this way DPO significantly improves upon the SFT model across all benchmarks for both Llama-3.1-8b-Instruct and Gemma-2-9b-it.
.png)
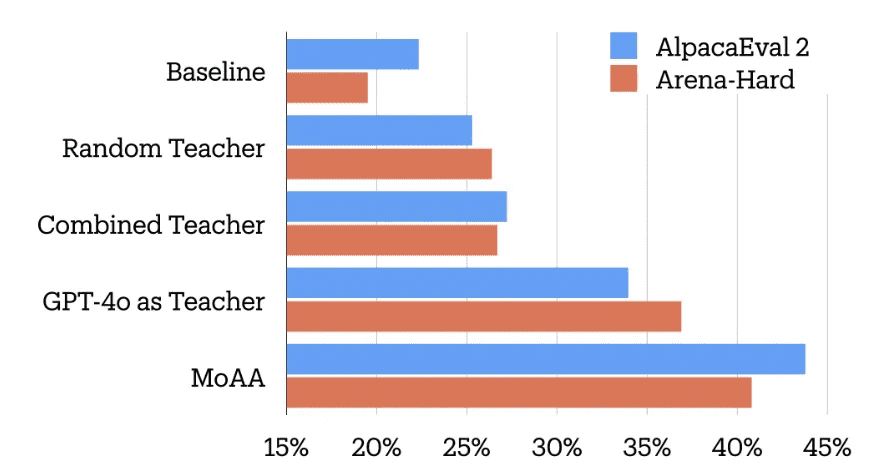
To compare the effects of reward models, we evaluated different reward models to curate the preference data: ArmoRM-Llama3-8B-v0.1, PairRM, Llama-3.1-70B-Instruct as reward model, gemma-2-27B-it as reward model, Qwen2-72B-Insutrct as reward model, and MoA as reward model.
These reward models are highly effective, and this comparison enables us to demonstrate the efficacy of our MoA as a reward model. Notably, our method outperforms several strong reward models that are specifically trained for this task, as well as GPT-4o, on two of the benchmarks.
.png)
The impact of preference alignment on our distilled model has been significant. As shown in the above figure, our results indicate that the DPO method yields substantial improvements over the best SFT model on AlpacaEval 2.0 and Arena-Hard compared to using GPT-4o as a reward model. While DPO slightly degrades the performance on MT-Bench (compared with DPO with GPT-4o), it remains higher than the original baseline. These findings demonstrate the effectiveness of our MoAA pipeline and highlight the potential for pushing the boundaries of Large Language Models by leveraging collective intelligence from multiple models.
MoAA enables a self-improving pipeline
We found that when the strongest model in the MoA mix is trained on MoA-generated data, it still achieves a substantial performance boost. This finding is particularly exciting, as it implies that our method has the potential to further advance the capabilities of open-source models without relying on supervision from more powerful LLMs. To investigate this further, we evaluated a small-scale MoA (MoA-SmallScale) configuration, comprising: Gemma-2-9B-it, Llama-3.1-8B-Instruct, and Mistral-7B-Instruct-v0.3 as proposers, and utilized a two-layer MoA architecture with Gemma-2-9B-it serving as the aggregator to generate the data mixture.
.png)
As evident from the table, our fine-tuned model (SFT on MoA-Small-Scale) significantly outperforms the strongest model in the mixture (Gemma-2-9b-it). This result provides strong evidence that a self-improving pipeline can be established to continuously enhance model performance.
Useful Links
- Paper
- SFT data
- gemma-2-9b-it-MoAA-SFT
- gemma-2-9b-it-MoAA-DPO
- Llama-3.1-8B-Instruct-MoAA-SFT
- Llama-3.1-8B-Instruct-MoAA-DPO
Citation
Please cite if you find our work is helpful.
(This blog post was written with the help of Together Chat)