

Together AI provides the fastest cloud platform for building and running generative AI. Today we are launching the Together Embeddings endpoint. As part of a series of blog posts about the Together Embeddings endpoint release, we are excited to announce that you can build your own powerful RAG-based application right from the Together platform with MongoDB's Atlas Vector Search.
.webp)
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) (original paper, Lewis et al.), leverages both generative models and retrieval models for knowledge-intensive tasks. It improves Generative AI applications by providing up-to-date information and domain-specific data from external data sources during response generation, reducing the risk of hallucinations and significantly improving performance and accuracy.
Building a RAG system can be cost and data efficient without requiring technical expertise to train a model while keeping other advantages mentioned above. Note that you can still fine-tune an embedding or generative model to improve the quality of your RAG solution even further! Check out Together fine-tuning API to start.
To use RAG, you first populate a vector database using an embedding model of your choice. For example, this database may contain recent knowledge, private documents, or domain specific information that can later guide your generative model to generate a correct answer. Once you have a vector database, you will retrieve relevant data examples to your query using the same embedding model you used to create the vector database with vector search. Lastly, you augment the retrieved information to your prompt, and obtain the final output from a generative model.
Below, we will walk you through step-by-step how to do this with a sample Airbnb listing review dataset in the Python environment.
Implementing RAG with Together and MongoDB Atlas
Step 1: Setting up
If you don't have an account already, first sign up for Together AI by clicking here. Once you sign up, you will be granted with $25 free credits, so that you can try out various models and products we provide. Visit our Playground and experience 100+ generative AI models and for more details about how to use our API, visit our Documentation page.
To access Together API for this tutorial, you will be using your private Together API key. Find your key on the API key page.
Additionally, set up a MongoDB Atlas account by visiting the Register page if you don't have an account yet. To access your database, you will need your MongoDB URI. Find your URI by clicking "Connect" > "Drivers" > "3. Add your connection string … " :
Now install the following python packages `pip install requests pymongo together`. On your main script, define your private key variables with the API key and URI you found above:
import together
import pymongo
TOGETHER_API_KEY = YOUR_TOGETHER_API_KEY
together.api_key = TOGETHER_API_KEY
client = pymongo.MongoClient(YOUR_MONGODB_URI)
Step 2: Set up the embedding creation function
Now we will define an embedding function using Together's Embeddings REST API:
from typing import List
def generate_embeddings(input_texts: List[str], model_api_string: str) -> List[List[float]]:
"""Generate embeddings from Together python library.
Args:
input_texts: a list of string input texts.
model_api_string: str. An API string for a specific embedding model of your choice.
Returns:
embeddings_list: a list of embeddings. Each element corresponds to the each input text.
"""
together_client = together.Together()
outputs = together_client.embeddings.create(
input=input_texts,
model=model_api_string,
)
return [x.embedding for x in outputs.data]
Choose your embedding model from the list of available models. Copy the model string for API to provide in your script. In this example, we will use the retrieval fine-tuned M2-BERT 8K model. Also, define the vector database field name, and choose the number of documents you will process to generate embeddings and save them. The more documents you use in the retrieval step, the more accurate your final output will be. However, you may hit the rate limit for a heavy use case. Consider switching to the Paid Account to avoid the rate limit.
embedding_model_string = 'togethercomputer/m2-bert-80M-8k-retrieval' # model API string from Together.
vector_database_field_name = 'embedding_together_m2-bert-8k-retrieval' # define your embedding field name.
NUM_DOC_LIMIT = 200 # the number of documents you will process and generate embeddings.
sample_output = generate_embedding(["This is a test."], embedding_model_string)
print(f"Embedding size is: {str(len(sample_output[0]))}")
Confirm that your embedding dimension meets the expected value. The expected value can be found on the available Models page.
Step 3: Create and store embeddings
In this tutorial, we are going to use the Airbnb listing review sample dataset in your Atlas database. You can see all other sample datasets in the documentation or under "Collections". To have its embeddings contain important information, we will select a set of keys to extract and concatenate their values as an input string. Below, we are generating embeddings for one document at a time, but you can also send a list of document strings at once.
db = client.sample_airbnb
collection = db.listingsAndReviews
keys_to_extract = ["name", "summary", "space", "description", "neighborhood_overview", "notes", "transit", "access", "interaction", "house_rules", "property_type", "room_type", "bed_type", "minimum_nights", "maximum_nights", "accommodates", "bedrooms", "beds"]
for doc in tqdm(collection_airbnb.find({"summary":{"$exists": True}}).limit(NUM_DOC_LIMIT), desc="Document Processing "):
extracted_str = "\n".join([k + ": " + str(doc[k]) for k in keys_to_extract if k in doc])
if vector_database_field_name not in doc:
doc[vector_database_field_name] = generate_embedding([extracted_str], embedding_model_string)[0]
collection.replace_one({'_id': doc['_id']}, doc)
Step 4: Create a vector search index in Atlas
In this step, we will go to your Atlas page and follow this instruction to create the Atlas Vector Search Index. When you are selecting a database, select "sample_airbnb" > "listingsAndReviews".Select "sample_airbnb" > "listingsAndReviews". Provide an index name – here we used "SemanticSearch". Lastly, add a json config for your embeddings:
{
"fields": [
{
"type": "vector",
"path": "embedding_together_m2-bert-8k-retrieval",
"numDimensions": 768,
"similarity": "dotProduct"
}
]
}
Note that the field name should be the same as vector_database_field_name and the embedding dimension should be equal to the actual dimension. In this example, we are using dotProduct. For other options, see the Atlas Vector Search documentation.
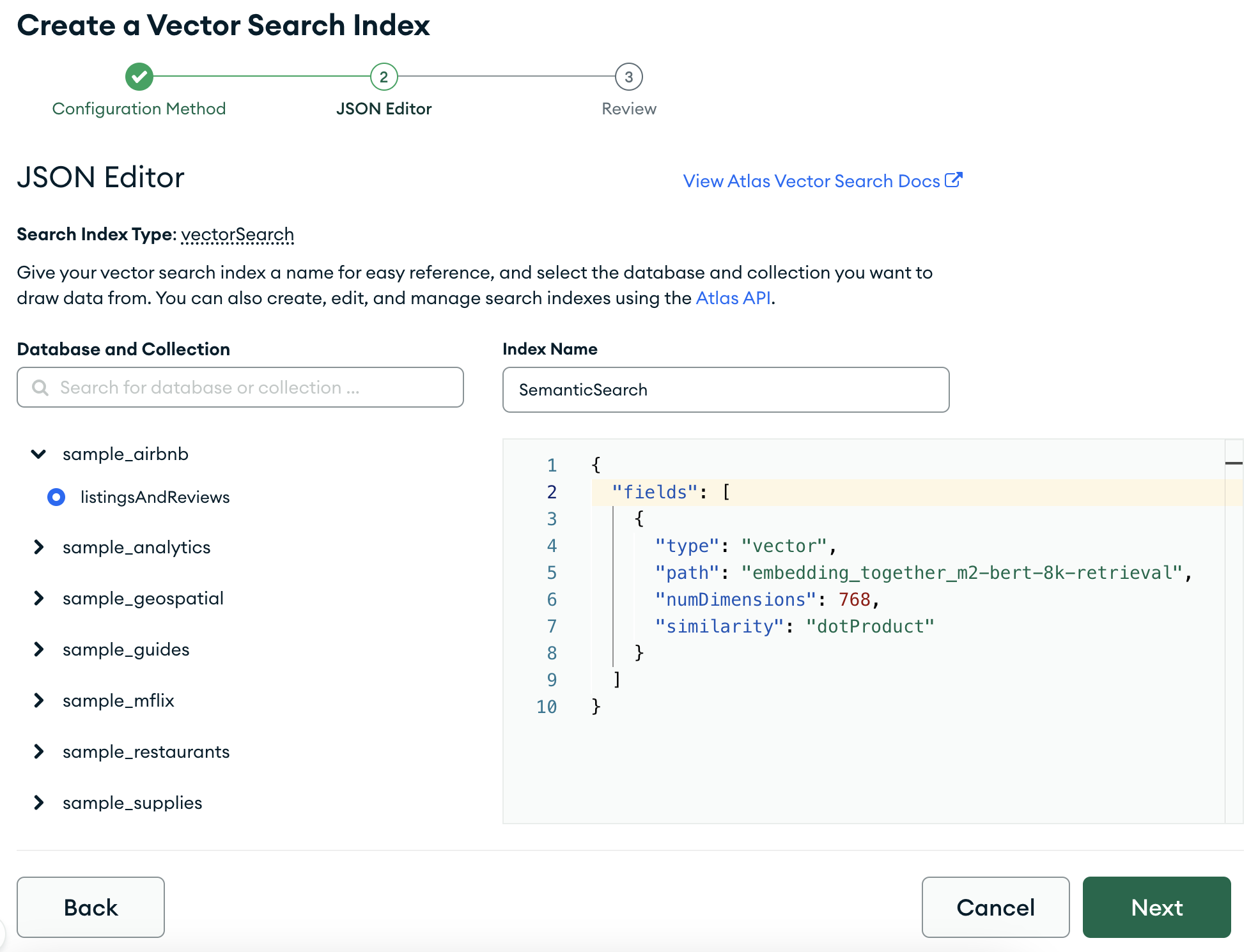
Click "Next" and then "Create Search Index" button on the review page.
Step 5: Retrieve
Now we will retrieve a number of documents from the sample database that may contain relevant information to the user query. For the definitions of fields that the $vectorSearch takes, see the documentation.
# Example query.
query = "apartment with a great view near a coast or beach for 4 people"
query_emb = generate_embedding([query], embedding_model_string)[0]
results = collection_airbnb.aggregate([
{
"$vectorSearch": {
"queryVector": query_emb,
"path": vector_database_field_name,
"numCandidates": 100, # this should be 10-20x the limit
"limit": 10, # the number of documents to return in the results
"index": "SemanticSearch", # the index name you used in Step 4.
}
}
])
results_as_dict = {doc['name']: doc for doc in results}
print(f"From your query \"{query}\", the following airbnb listings were found:\n")
print("\n".join([str(i+1) + ". " + name for (i, name) in enumerate(results_as_dict.keys())]))
The output for this example will look like this:
From your query "apartments with a great view near a coast or beach for 4 people", the following airbnb listings were found:
1. Private OceanFront - Bathtub Beach. Spacious House
2. March 2019 availability! Oceanview on Sugar Beach!
3. Asia House, Garden Room, Princevile
4. Aquilla House - Ocean Views Newport
5. 302 Kanai A Nalu Ocean front/view
6. Jubilee By The Sea (Ocean Views)
7. enjoy nature in Istanbul
8. Makai Hideaway
9. Lovely room in Caueway Bay!
10. Pineapple Paradise
Step 6: Augment and Generate
In this last step, we will augment the retrieved data and provide it to a generative model of our choice to generate the final output on our prompt.
First, the prompt we will use in this example is:
your_task_prompt = (
"From the given airbnb listing data, choose an apartment with a great view near a coast or beach for 4 people to stay for 4 nights. "
"I want the apartment to have easy access to good restaurants. "
"Tell me the name of the listing and why this works for me."
)
Next, we will combine the retrieved data as one string to add to the prompt. Since it contains some not useful information such as _id and embedding_together_m2-bert-8k-retrieval, we will filter them out.
listing_data = ""
for doc in results_as_dict.values():
listing_data += f"Listing name: {doc['name']}\n"
for (k, v) in doc.items():
if not(k in keys_to_extract) or ("embedding" in k): continue
if k == "name": continue
listing_data += k + ": " + str(v) + "\n"
listing_data += "\n"
augmented_prompt = (
"airbnb listing data:\n"
f"{listing_data}\n\n"
f"{your_task_prompt}"
)
Finally, choose a generative model and run the inference using Together Inference API. You can find the full list of available models here. Consider selecting a model that can accept your input length. Additionally, we will check the default prompt format and stop sequences, and update the prompt before running the inference.
response = together.Complete.create(
prompt=formated_prompt,
model=model_api_string,
max_tokens = 512,
temperature = 0.8,
top_k = 60,
top_p = 0.6,
repetition_penalty = 1.1,
stop = stop_sequences,
)
print(response["output"]["choices"][0]["text"])
Run the inference (see more information about the parameters in our documentation):
response = together.Complete.create(
prompt=formated_prompt,
model=model_api_string,
max_tokens = 512,
temperature = 0.8,
top_k = 60,
top_p = 0.6,
repetition_penalty = 1.1,
stop = stop_sequences,
)
print(response["output"]["choices"][0]["text"])
The example output looks like this:
Based on the given criteria, the most suitable apartment for your stay would be "March 2019 availability! Oceanview on Sugar Beach!" This apartment offers a great view of the ocean, easy access to a beautiful beach, and various amenities such as a pool and barbecue area. Additionally, it is located close to nearby attractions like shopping centers and malls. The host is also available to assist you during your stay.
You can see "March 2019 availability! Oceanview on Sugar Beach!" is indeed in the retrieved list! To further check if this satisfies the query, let's take a look at the listing of this place from the original database:
for (k, v) in results_as_dict["March 2019 availability! Oceanview on Sugar Beach!"].items():
if k in keys_to_extract:
print(f"{k}: {v}")
name: March 2019 availability! Oceanview on Sugar Beach!
summary:
space: NIGHTLY RATE INCLUDES ALL TAXES! The Kealia Resort - Just a few steps from the warm sand of Sugar Beach, Maui's longest white-sand beach. With gorgeous views, ... and close proximity to town ...
...
minimum_nights: 4
maximum_nights: 1125
accommodates: 4
...
It's close to the proximity to town instead of particular restaurants, but overall, it satisfies most of the requirements in our query!
Conclusion
This tutorial showed how to use Together Inference to generate embeddings and language responses. We also demonstrated how to use MongoDB's Atlas Vector Search to store embeddings and perform the semantic search to retrieve relevant data examples for your natural language query. Combining these learnings, we presented an example of building a RAG application with a sample Airbnb listing data and how the generative AI model can recommend a place that meets our criteria while adhering to factual information.
This is one example, and we are looking forward to seeing many amazing applications that will be built using Together APIs and MongoDB's Atlas Vector Search!