

One of the focus areas at Together Research is new architectures for long context, improved training, and inference performance over the Transformer architecture. Spinning out of a research program from our team and academic collaborators, with roots in signal processing-inspired sequence models, we are excited to introduce the StripedHyena models. This release includes StripedHyena-Hessian-7B (SH 7B), a base model, and StripedHyena-Nous-7B (SH-N 7B), a chat model. StripedHyena builds on the many lessons learned in the past year on designing efficient sequence modeling architectures: H3, Hyena, HyenaDNA, and Monarch Mixer.

- StripedHyena is the first alternative model competitive with the best open-source Transformers in short and long-context evaluations. The same base model achieves comparable performance with Llama-2, Yi and Mistral 7B on OpenLLM leaderboard tasks, outperforming on long-context summarization.
- StripedHyena is faster and more memory efficient for long sequence training, fine-tuning, and generation. Beside attention, one core computational primitive for efficient inference is a state-space model (SSM) layer, building on pioneering work such as S4 (Gu el al.), enabling conversion of convolutional layers into recurrences. Using our latest research on fast kernels for gated convolutions (FlashFFTConv) and on efficient Hyena inference, StripedHyena is >30%, >50%, and >100% faster in end-to-end training on sequences of length 32k, 64k and 128k respectively, compared to an optimized Transformer baseline using FlashAttention v2 and custom kernels. StripedHyena caches for autoregressive generation are >50% smaller than an equivalently-sized Transformer using grouped-query attention.
- StripedHyena is designed using our latest research on scaling laws of efficient architectures. In particular, StripedHyena is a hybrid of attention and gated convolutions arranged in Hyena operators. Via a compute-optimal scaling protocol, we identify several ways to improve on baseline scaling laws for Transformers (Chinchilla) at the architecture level, such as hybridization. With these techniques, we are able to obtain higher quality models than Transformers at each training compute budget, with additional benefits at inference time.
- StripedHyena is optimized using a set of new model grafting techniques, enabling us to change the model architecture during training. StripedHyena was obtained by grafting architectural components of Transformers and Hyena, and trained on a mix of the RedPajama dataset, augmented with longer-context data.
We look forward to further pushing the boundaries of model architectures for fast training and inference, allowing us to improve on existing scaling laws and to obtain higher quality base models at each compute budget.
A single architecture for short and longer context tasks
For the past year, the Together AI team and our collaborators at Hazy Research have been working on the design of new sequence models for language and other domains. We’ve been especially excited by architectures that replace attention as the primary operator responsible for mixing sequences of embeddings, and replacing them with alternatives that are computationally cheaper. We’ve developed several models (H3, Hyena) that replace attention with implicit gated convolutions and gated SSMs, and trained some of the first alternative architectures rivaling Transformers on language.
Evaluation
We evaluate StripedHyena on a suite of benchmarks to establish performance on short-context tasks, as well as to probe its ability to process long prompts.
First, we test perplexity scaling on a subset of books from Project Gutenberg. We compute the perplexity on the last 2048 tokens of each sample, and repeat the experiment by including increasingly longer prefixes in the prompt of StripedHyena. We observe different behaviors depending on the structure of the sample; perplexity either saturates at 32k (the input length seen during the last stages of training), or keeps decreasing past 32k, suggesting that the model is able to incorporate some information from the longer prompt.

Quality on longer context makes StripedHyena an efficient baseline generalist model, competitive with Mistral 7B on summarization and longer context tasks:
Benchmarking StripedHyena-Hessian-7B (SH 7B) and Mistral 7B on zero-shot, long-context tasks from ZeroScrolls.
StripedHyena is the first alternative architecture competitive with strong Transformer base models of the same size or larger, at scale. On short-context tasks, including OpenLLM leaderboard tasks, StripedHyena outperforms Llama-2 7B, Yi 7B and the strongest Transformer alternatives such as RWKV 14B:
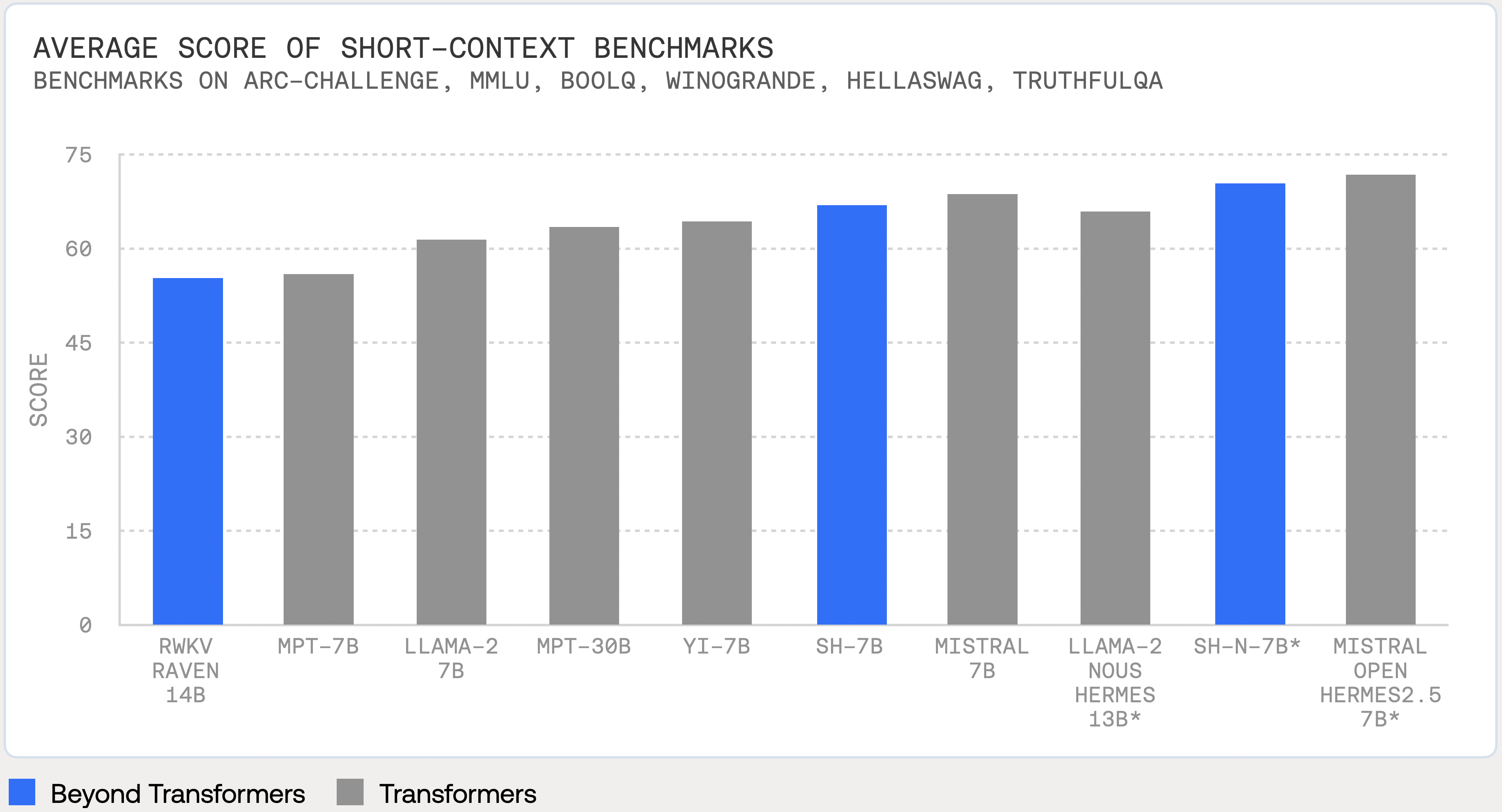
With our collaborators at Nous Research, we are excited to also release StripedHyena-Nous- 7B (SH-N 7B), a chat model, built with new fine-tuning recipes tailored to the StripedHyena architecture.
Understanding the architecture design space: Many ways to improve scaling
Hybridization
Early in our scaling experiments, we noticed a consistent trend: given a compute budget, architectures built out of mixtures of different key layers always outperform homogenous architectures. These observations echo findings described in various papers: H3, MEGA (among others) and find even earlier connections to the hybrid global-local attention design of GPT-3 (from Sparse Transformers) and GPTNeo.
To understand this phenomenon, as well as the improvement on scaling coefficients – for example, the expected loss reduction per floating point operation (FLOP) in the budget – for a class of architectures, we carried out an extensive compute-optimal scaling analysis. We found hybrids composed of multi-head attention, gated MLPs and gated convolutions to outperform strong Transformer architectures such as Llama across compute budget, and identified optimal ways to mix these components, in both ordering and quantity.
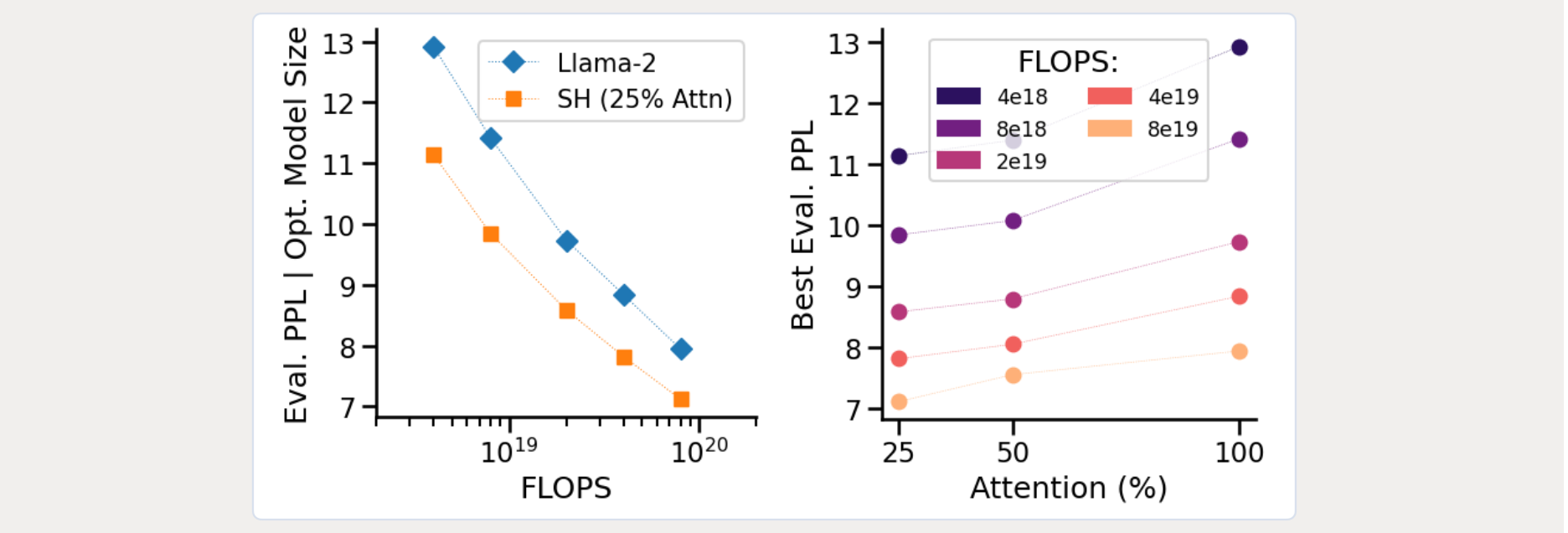

With our academic partners, we have been developing theory and synthetic tasks to understand how and why this occurs. We have identified a variety of regimes where layers specialize to particular sub-tasks of sequence modeling, providing valuable signals for further architecture optimization. This continues our general line of work on mechanistic design, which involves small-scale, synthetic tasks carefully constructed to stress-test architecture capabilities.
Multi-head gated convolutions
Another way to improve over Transformer rates is to introduce additional computation in the form of multiple heads in gated convolutions. This design, inspired by linear attention, has been validated in architectures such as H3 and MultiHyena, and is provably more efficient at encoding associative recall circuits.

These are two of many architectural design techniques that can result in improved scaling over Transformers. With StripedHyena, we focus in particular on the synergy between attention and gated convolutions.
A shift in the computational footprint of language models: Cheaper fine-tuning, faster inference
Optimizing models built on a different architecture requires rethinking computational trade-offs of training, fine-tuning, and inference. For these new architectures, a different set of computational bottlenecks emerges, and we’re proud to have developed the key technologies enabling these models as well, such as FlashFFTConv and its predecessors.
For training and fine-tuning workloads on long sequences, SH 7B is always faster than optimized Transformers (>10%, >20% and >50% end-to-end faster than FlashAttention v2 processing sequences of lengths 32k, 64k and 128k, at batch size 1), with the speedup growing larger on longer sequences and with larger batches. StripedHyena models are optimal candidates for fine-tuning on long-context tasks – for tasks at length 128k, SH 7B can finetune on more than twice as many tokens as a Transformer given the same budget.
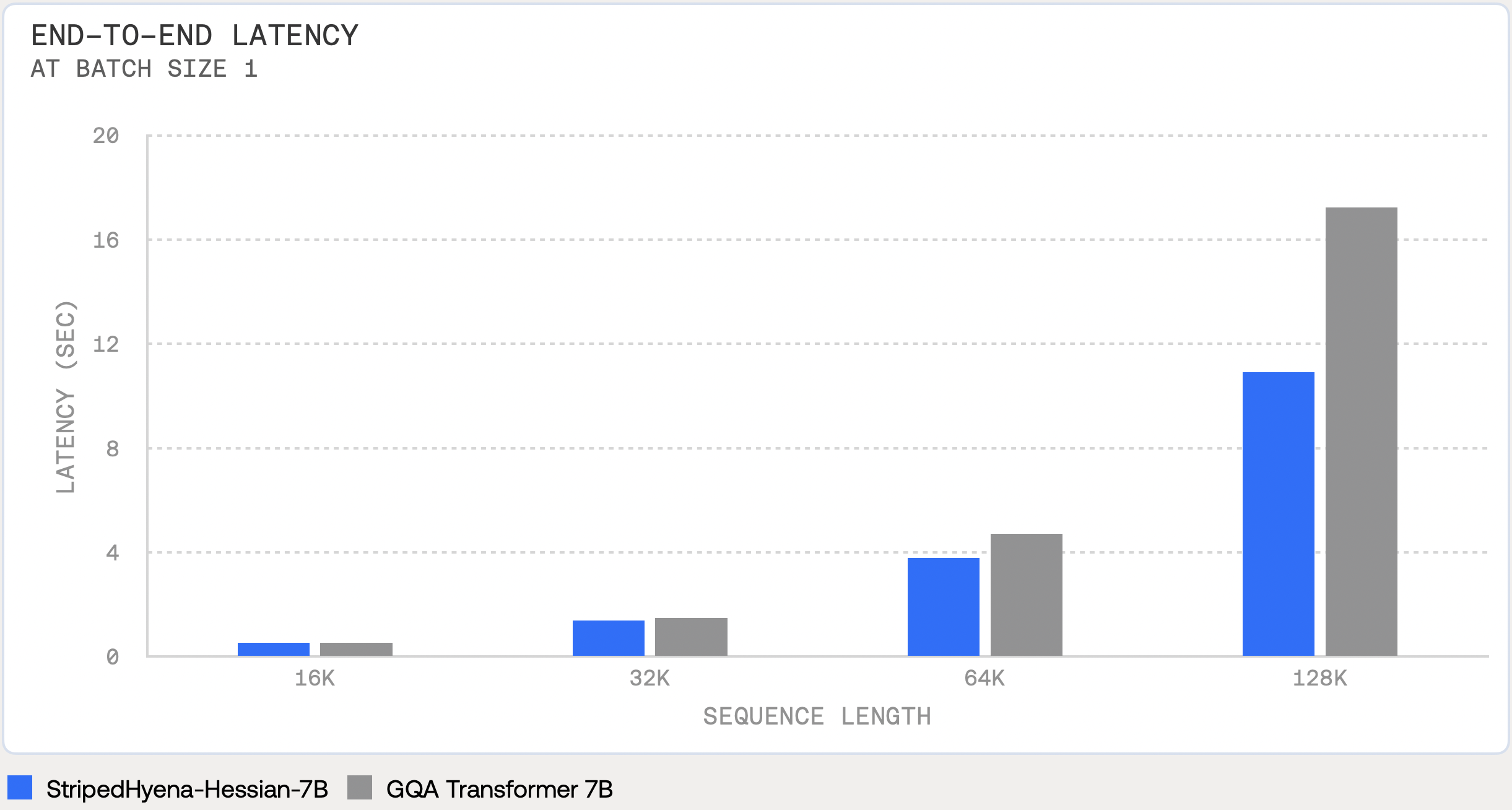
These improvements are driven by the different asymptotic scaling and computational profile of layers in the hybrid architecture. We look forward to even faster models with refined mixing ratios and layers.
Reducing memory for inference
One additional advantage of SH 7B is a >50% reduced memory footprint during autoregressive generation, compared to a Transformer (both with grouped-query attention). In Transformers, the key and value entries of each layer are cached during the prefilling phase to avoid recomputation and speed up incremental decoding. Gated-convolution layers introduce significantly more degrees of freedom during inference, as there are several ways to represent and optimize computation. We explore these trade-offs in our recent research on distillation and representation of convolutions in Hyena. These new techniques have been used in SH 7B to further reduce the memory footprint by identifying and pruning redundant states.

From signal processing to language models
The flexibility of StripedHyena is a direct consequence of the existence of multiple equivalent representations and parametrization of linear systems: convolutional, modal, canonical. Each form is better suited to a specific training and inference workload.
Borrowing terminology from classical signal processing, SH convolutional filters can be broadly treated as either finite (FIR) or infinite (IIR). FIR caching for a convolution is analogous to standard key-value caching (kv caching) in attention – particularly the sliding window kind – and grows in memory footprint (until a maximum value).
IIR filters on the other hand can be applied by caching a constant-size state, then updated during decoding via a recurrent step. The IIR representation can itself be customized. Fixed-size states, in contrast to kv caches, open up several key optimizations at the inference stack level, streamlining techniques such as continuous batching and speculative decoding.
What’s ahead
Our primary objective with the StripedHyena models is to push the frontier of architecture design beyond Transformers. StripedHyena only scratches the surface of what is possible with careful architecture design via mechanistic design and scaling laws, and with ideas such hybridization, implicit convolutions and state caching. We hope these models can inspire the open source community to explore new exciting builds with diverse architectures.
In future versions we will explore:
- Larger models with longer context.
- Multi-modal support.
- Further performance optimizations.
- Integration of StripedHyena into retrieval pipelines for full utilization of longer context.
Acknowledgments
This work would not have been possible without our collaborators at HazyResearch, Hessian.AI, Nous Research, MILA, HuggingFace, DFKI.
We are grateful to Hessian.AI Innovation Lab (funded by the Hessian Ministry for Digital Strategy and Innovation) and the hessian.AISC Service Center (funded by the Federal Ministry of Education and Research (BMBF)) for the collaboration and joint use of their AI supercomputer forty-two. Special thanks also go to the German Center for Artificial Intelligence (DFKI).