
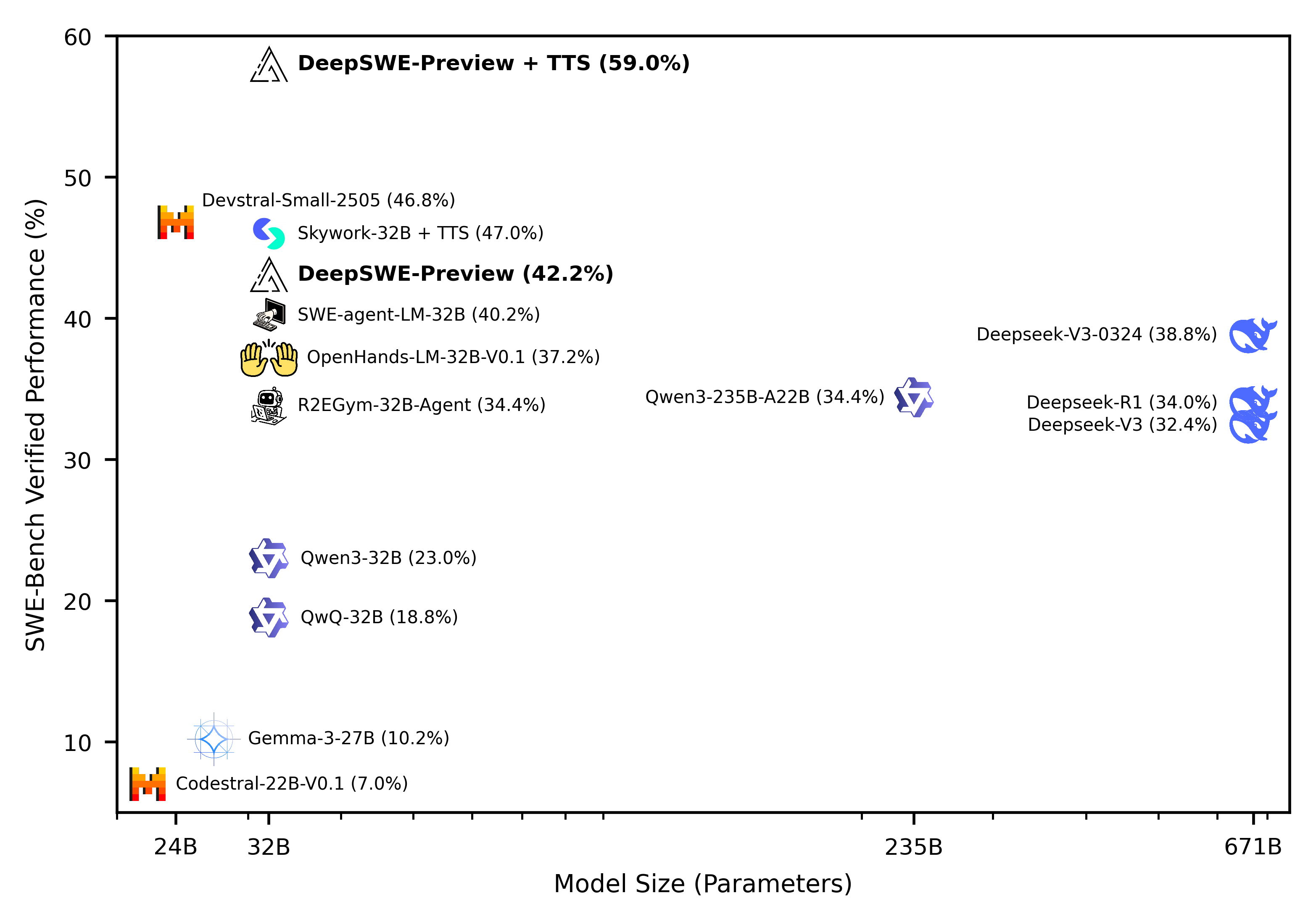
Through a joint collaboration between the Agentica team and Together AI, we introduce DeepSWE-Preview, a reasoning-enabled coding agent trained from Qwen3-32B with only reinforcement learning (RL). It achieves an impressive 59% on SWE-Bench-Verified with test-time scaling, reaching SOTA for open-weight coding agents (42.2% Pass@1, 71.0% Pass@16).
DeepSWE is trained using rLLM, Agentica's framework for post-training language agents. We've open sourced everything—our dataset, code, training, and eval logs, for everyone to progress on scaling and improving agents with RL.
DeepSWE-Preview

Recent months have seen tremendous progress in training reasoning-based large language models (LLMs) using reinforcement learning, including our recent works DeepScaleR [1] and DeepCoder [2]. However, scaling RL-based reasoning models to long-horizon, multi-step, agentic tasks remains a challenging and open problem.
Autonomous software engineering (SWE)—a domain involving complex tasks such as resolving GitHub issues, implementing new code features, and debugging—is one prominent example of such challenging multi-step scenarios. Real-world software engineering poses uniquely difficult demands, requiring agents to navigate extensive codebases, contextualize file interactions, apply targeted code edits, run shell commands for building and testing, and iteratively refine and verify solutions while resolving real-life pull requests.
In this blog, we fully democratize the training recipe for developing a 32B model into an intelligent coding agent. We introduce DeepSWE-Preview, a state-of-the-art open-source coding agent trained entirely from scratch atop Qwen/Qwen3-32B using only reinforcement learning. Trained over 4,500 real-world SWE tasks taken from the R2E-Gym training environments [3] across six days on 64 H100 GPUs, our model achieves state-of-the-art performance among open-source/open-weight models on the challenging SWE-Bench-Verified benchmark.
DeepSWE is trained with rLLM, Agentica's framework post-training for language agents. Check out rLLM's blog post for more.
1. Background
LLM Agents
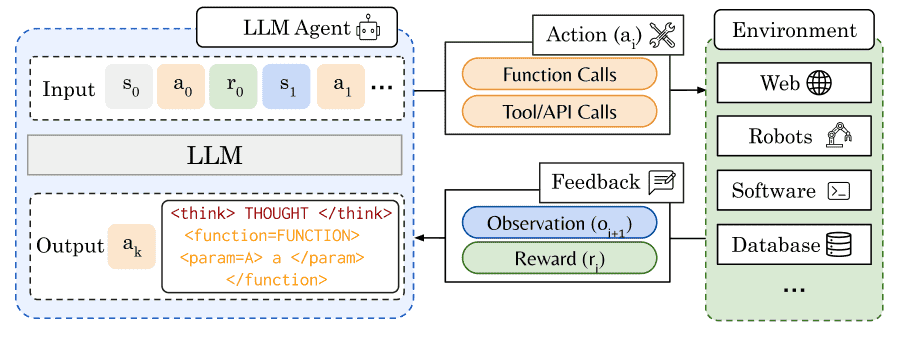
In reinforcement learning (RL), agents are autonomous entities that perform actions and receive feedback from an environment in the form of new observations and rewards. Such environments are highly diverse, ranging from simpler settings like Atari games to more complex domains including robotic-control, software development in codebases, managing databases, and protein discovery tasks.
Large language models (LLMs) serving as RL agents interact with their environments guided by internal representations built from previous observations and actions. Leveraging these representations, LLM-based agents invoke external tools or functions to carry out specific actions within their environments.
Software Engineering (SWE)
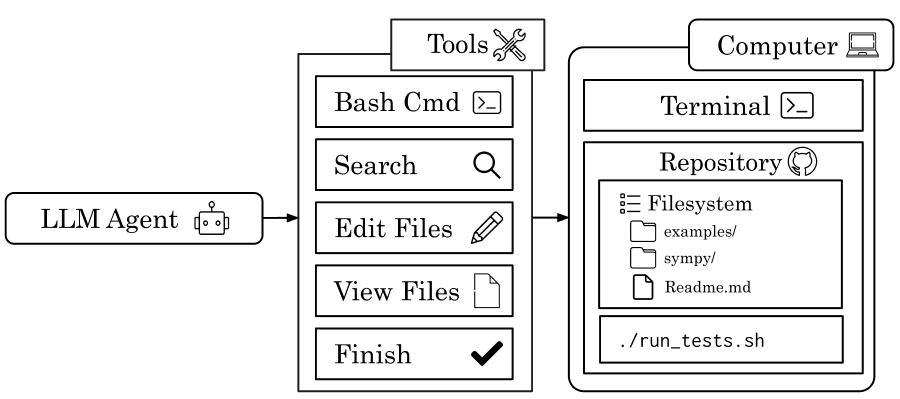
General software-engineering tasks—such as resolving a pull request—are formulated as reinforcement-learning environments (Figure 3). Given a pull request, an agent navigates a computer-based environment, equipped with a terminal and a filesystem with the corresponding codebase. Similar to how human developers interface with IDEs (such as VSCode, Cursor, IntelliJ), an agent is provided a set of tools that include bash execution, search, and file viewer/editor. An agent may also be given an additional finish tool to call when it believes it has finished the task. To assign a reward in RL, the project's automated test suite is run on top of the LLM's modified code. Successful execution of all tests yields a positive reward (pull request resolved), while test failures incur zero reward.
2. Training Recipe 🍽️
Our coding agent, DeepSWE-Preview , along with prior releases DeepCoder-14B-Previewand DeepScaleR-1.5B-Preview, are all trained on Agentica's post-training system, rLLM.
2.1 - Scalable Dataset Curation with R2E-Gym 🗄️
Our dataset contains 4.5K problems from a subset of R2E-Gym. To avoid data contamination during training, we filtered out problems that are derived from the same repositories as SWE-Bench-Verified , such as sympy. All problems map to individual Docker images.
2.2 - Environment 🌐
Our environment wraps around R2E-Gym [3], an existing Gym environment for scalable curation of high-quality executable SWE environments.
State & Action
R2E-Gym defines a set of four tools as part of the action space. The output of each tool (a Python program with stdout/stderr) represents the returned state. More specifically:
- Execute Bash - Outputs both stdout and stderr of an LLM-generated bash command.
- Search - Searches and returns all occurrences of an LLM-defined query in either a directory or a single file.
- File Editor - Allows for viewing, creating, replacing strings, inserting, and undoing edits to a specific file.
- Finish/Submit - LLM has decided that it has resolved the pull request, which terminates trajectory generation.
Reward
To keep things simple, our reward function employs a sparse Outcome Reward Model (ORM):
1- LLM's generated patch passes a selected sample of tests (Pass2Pass and Fail2Pass) within a time limit. To accelerate training, our max time limit is 5 minutes, while the official SWE-Bench evaluation is 30 minutes.0- We assign no reward if the LLM's code fails on at least one test case or times out.
Kubernetes (Scalable Agent Rollout Collection)
A challenge we encountered was scaling up SWE-Bench environments. During our final training run each RL iteration spawned 512 (BS=64, 8 passes) Docker containers in parallel. The demanding nature of RL, together with parallel experiments, generated thousands of containers at any given time, overloading Docker's API server and eventually crashing the Docker daemon (dockerd).
To remove that bottleneck, we integrated Kubernetes support into R2E-Gym, letting the orchestrator schedule containers across a pool of nodes. Each worker node has about 200 CPU cores and over 6 TB of local NVMe SSD. We preload the SWE-bench images, ensuring that nearly every layer is served from disk for fast startup and to avoid excessive pulls from Docker Hub.
The cluster can scale beyond 1000 CPU cores and relies on the Kubernetes Cluster Autoscaler to add or remove nodes automatically. When pods remain unschedulable for a short period, the autoscaler provisions additional worker nodes; conversely, it removes nodes that stay underutilized for roughly twenty minutes. This elastic setup lets us collect millions of trajectories reliably while keeping compute costs proportional to load.
2.3 - Training SWE Agents by Scaling RL
Extending GRPO to Multi-Turn
Since Deepseek-R1, math and coding reasoning as single-step RL environments are largely trained via GRPO. From prior work (i.e. RAGEN [7], Verl [11], ROLL [8], ART [9], Sky-RL [10]), extending GRPO to the multi-turn, or agent, setting involves masking out environment observations, or user messages in ChatML format, for each trajectory.
GRPO++: A Stable, More Performant GRPO
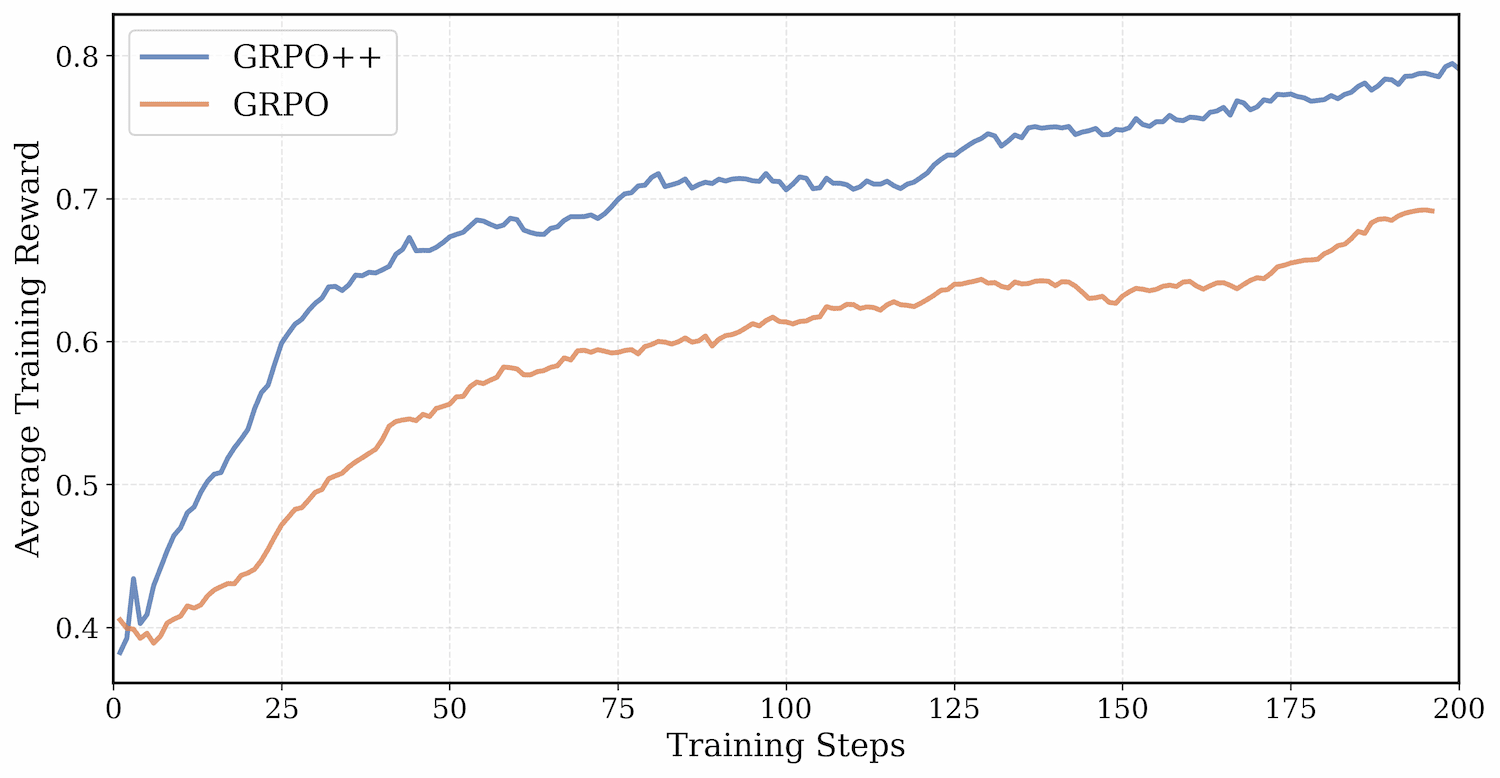
Similar to GRPO+ in our DeepCoder work, we enhance the original GRPO algorithm, integrating insights from DAPO [12], Dr. GRPO [13], LOOP/RLOO [14], and our innovations to enable stable training and improved performance, as shown in Figure 4 for FrozenLake. Our final, amalgamate algorithm consists of:
- Clip High (DAPO): Increasing the upper bound of GRPO/PPO's surrogate loss encourages exploration and stabilizes entropy.
- No KL Loss (DAPO): Eliminating KL loss prevents the LLM from being constrained to the trust region of the original SFT model.
- No Reward Standard Deviation (Dr.GRPO): Removing reward standard deviation removes difficulty bias in GRPO's loss, ensuring hard and easy problems are better differentiated.
- Length Normalization (Dr.GRPO): Dividing surrogate loss by max context length removes length bias present in GRPO, which increases the length of incorrect responses.
- Leave One Out (Loop/RLOO): Removing one sample for advantage estimation reduces variance for policy gradient without introducing bias.
- Compact Filtering (Us): Inspired by DAPO, we mask the loss for trajectories that reach max context length, timeout during generation (20 minutes), or reach maximum steps. Described further below.
- No Entropy Loss (Us): Entropy loss introduces higher instability and eventually leads to exponentially increasing entropy, which collapses training. Provided that the base model's token-level entropy is within 0.3-1, entropy loss is not needed.
Compact Filtering: Extending Overlong Filtering
DAPO introduced overlong filtering, where max context trajectories are effectively masked out from the loss. For multi-turn, agentic scenarios, trajectories hit termination when they timeout (either due to long generation times or environment execution) or hit maximum environment steps. Naturally, we introduce compact filtering, which masks trajectories that reach max context, max steps, or timeout.

Compact filtering benefits training for two reasons:
- Prevents or delays reward collapse during training (Figure 6). LLM agents may stumble upon correct patches and pass all tests without knowing. Training with these positives rewards reinforces undesired behaviors across steps (e.g. LLM answers correctly in first 10 steps but patches random files later on), leading to collapse when such behaviors accumulate. Ensuring that reward is only assigned when an LLM agent deliberately submits encourages rigorous testing so that the LLM can be more confident in its final submission.
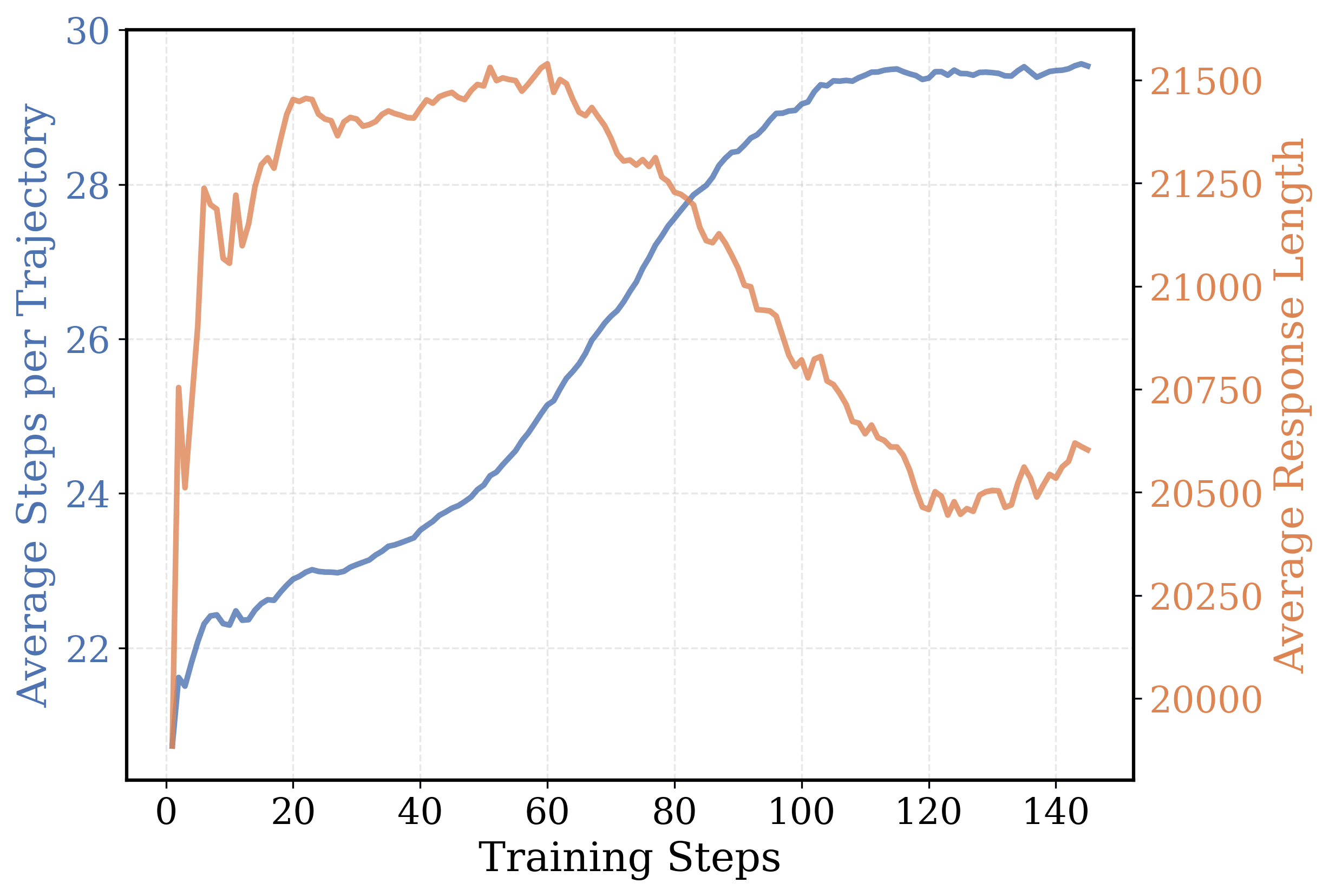
- Reduces excessive thinking per step and encourages long-form reasoning across steps. Figure 7 illustrates this phenomenon, where the average response length decreases but the average environment steps increase during training, indicating that the average thinking per step drops sharply.
3 - Test-Time Scaling 📈

Existing math and coding reasoning models scale their test-time compute and Pass@1 performance by scaling the number of tokens. For example, our prior DeepCoder-14B-Preview model increased LiveCodeBench Pass@1 performance from 57.8→60.6% by scaling the max context length from 32K→64K tokens. For agents, test-time performance also scales with the number of trajectories computed during inference. In Figure 8 given N generated trajectories, the agent must identify which one solves the task correctly.
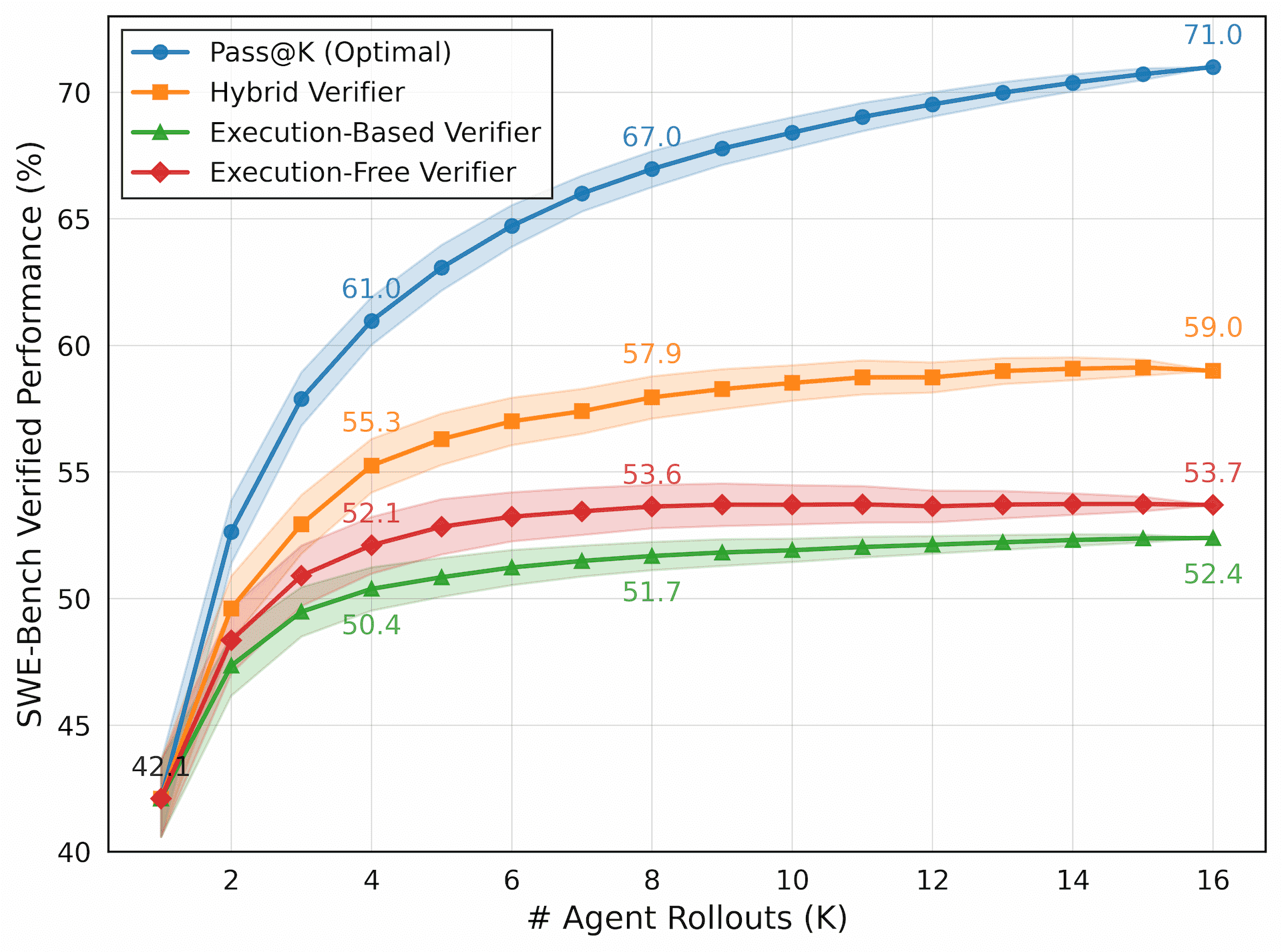
In an execution-free verifier approach (i.e., in R2EGym [3], Openhands Critic [4], Skywork [6]), the best trajectory is selected by a verifier LLM. Oftentimes, the verifier LLM is trained to identify correct and incorrect trajectories. Notably, our execution-free verifier, DeepSWE-Verifier , is trained for 2 epochs over correct/incorrect patches. In contrast, an execution-based verifier (i.e., R2EGym) employs another LLM to generate a diverse coverage of tests and edge cases, where the best trajectory passes the most tests. Finally, DeepSWE-Preview 's test-time scaling combines both paradigms with hybrid scaling (refer our recent paper R2E-Gym [3]) to achieve significantly better Pass@1 performance.
Below we evaluate DeepSWE-Preview over different TTS strategies:
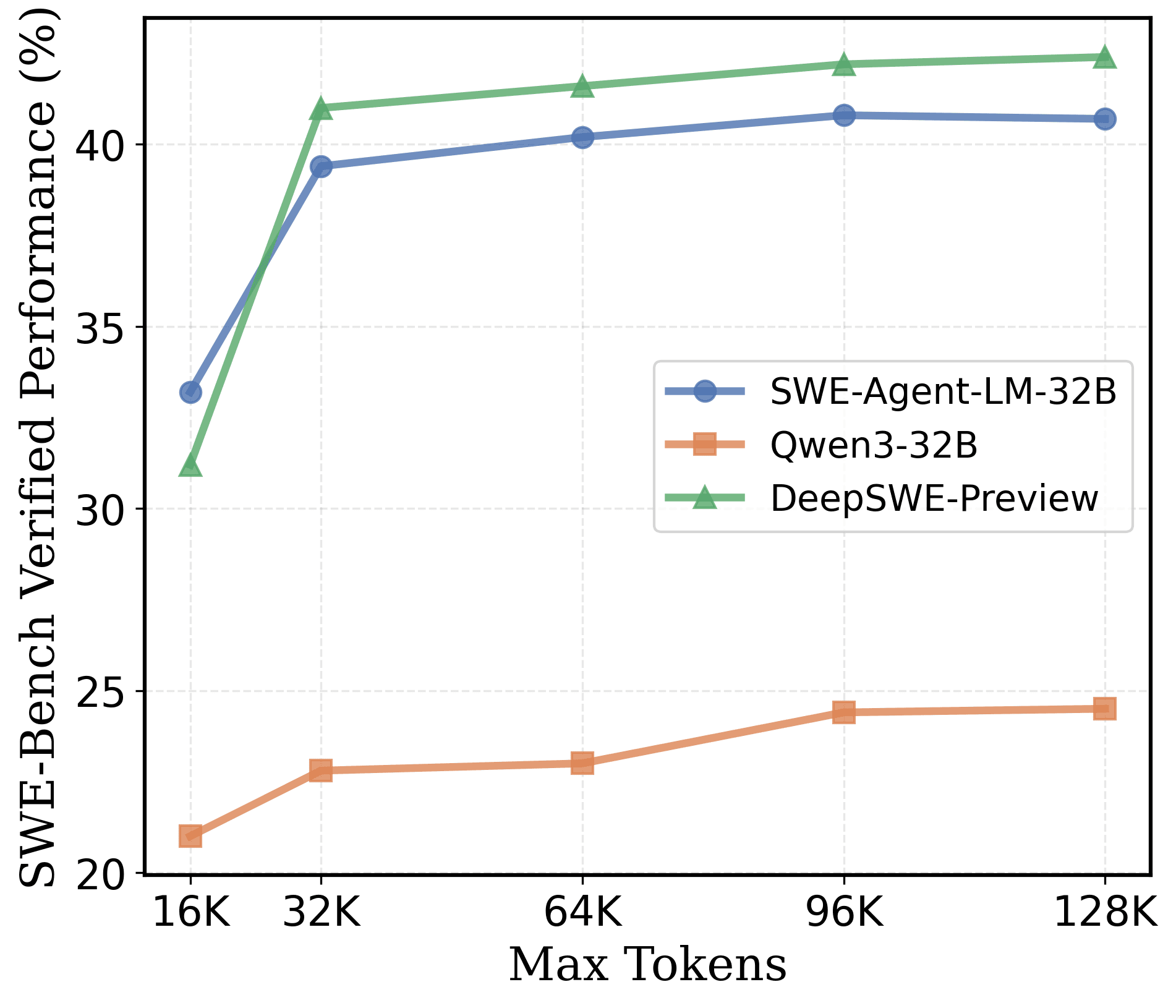
Scaling with Number of Tokens. In Figure 9, when scaling max context length from 16K→128K tokens, performance scales for DeepSWE-Preview and other baselines. However, the performance increase beyond 32K context is marginal (≤2%). For SWE-related tasks, scaling the number of output tokens does not seem to be effective.
Scaling with Number of Rollouts. Figure 10 ablates DeepSWE-Preview's performance with respect to different TTS techniques. Pass@K refers to the theoretical optimal performance that trajectory-level TTS techniques can achieve (100% accuracy). Notably, existing TTS techniques are far from optimal. However, hybrid scaling performs significantly better, with DeepSWE-Preview reaching 59.0% using K=16 rollouts, than that of execution-based and execution-free verifiers.
For most practical scenarios, a majority of TTS's performance gains can be achieved with K=8.
4 - Evaluation 📝
DeepSWE-Preview is evaluated via the official R2E-Gym codebase at 64k max context length and 100 max environment steps. DeepSWE's generated patches are then ported over to the offical SWE-bench repo to calculate final score. Below, we report Pass@1 accuracy averaged over 16 runs.
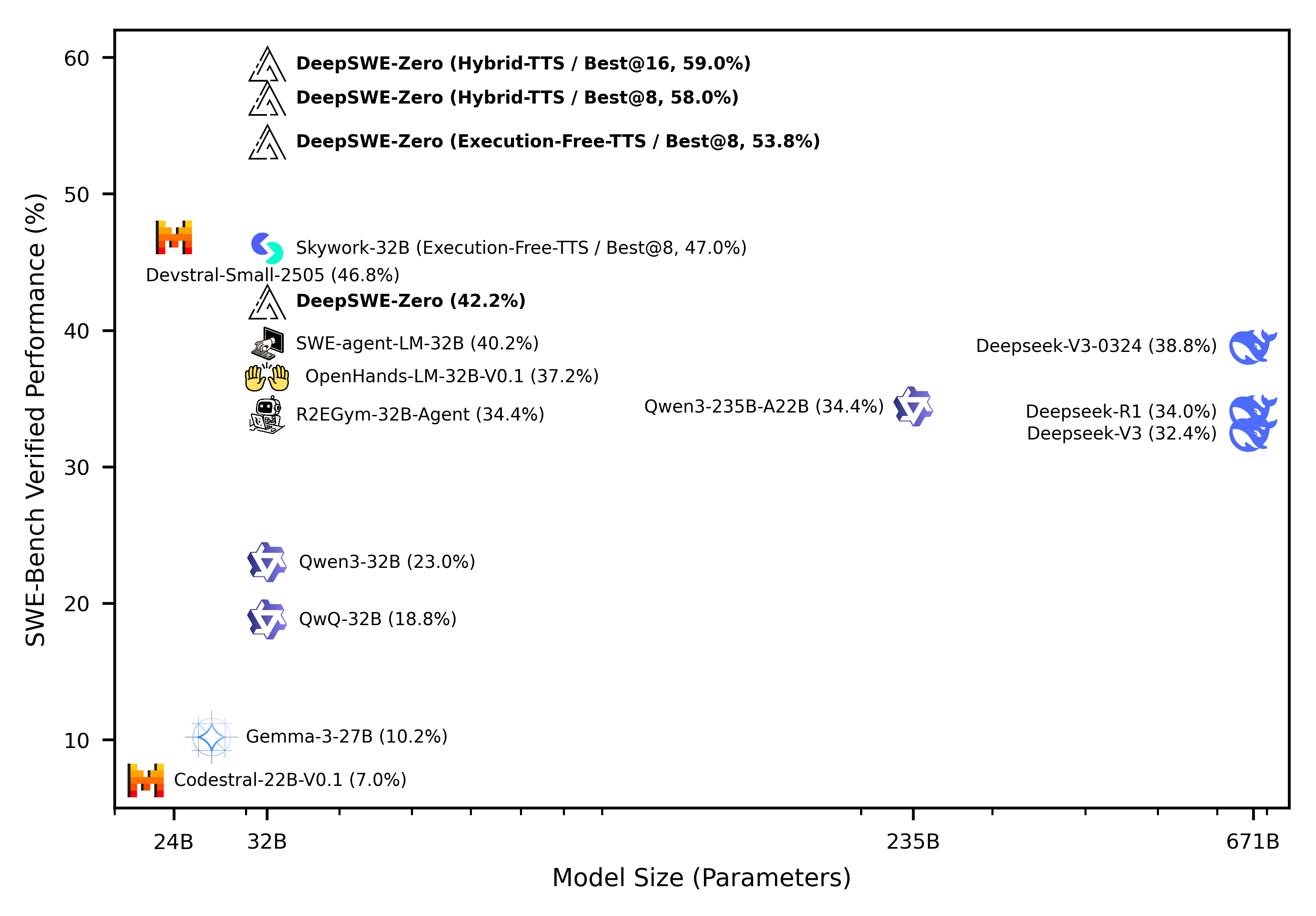
| Model | Scaffold | Type | SWE-Bench Verified (%) |
| DeepSWE-Preview (32B) | R2E-Gym | Agent + Hybrid Best@16 | 59% |
| DeepSWE-Preview (32B) | R2E-Gym | Agent + Hybrid Best@8 | 57.9% |
| DeepSWE-Preview (32B) | R2E-Gym | Agent | 42.2% |
| Devstral-Small (24B) | OpenHands | Agent | 46.6% |
| Openhands-LM (32B) | OpenHands | Agent (Iterative) | 37.2% |
| SWE-Agent-LM (32B) | SWE-Agent | Agent | 40.2% |
| R2EGym-Agent (32B) | R2E-Gym | Agent | 34.4% |
| Skywork-SWE (32B) | OpenHands | Agent | 38.0% |
| Skywork-SWE (32B) | OpenHands | Agent + Execution-Free Best@8 | 47.0% |
| SkyRL-Agent (14B) | OpenHands | Agent | 21.6% |
Our DeepSWE-Preview model achieves 42.2% pass@1 on the SWE-Bench Verified Benchmark using just reinforcement learning on top of the Qwen/Qwen3-32B model. Notably, training with only reinforcement learning (RL) outperforms various prior approaches which leverage similar or more training data and distillation, or SFT, from stronger proprietary teacher models [3, 4, 5, 6].
5- Analyzing Emergent Behaviors 🔎
Surprisingly, we found that when trained using pure RL with 0/1 verifiable rewards, the agent automatically learns some interesting behaviors which help it solve complex real-world SWE tasks more reliably. We next provide some anecdotes analyzing some interesting emergent behaviors from the DeepSWE-Preview model, with additional examples given in the Appendix.
Trying to always think of edge cases and repository regression tests
One of the most challenging problems for current SWE agents, is that while they may fix the proposed bug, the generated patch may not consider edge cases or introduce new bugs which break existing functionality of the codebase. Surprisingly, we find that during the course of RL run, the agent learns to automatically think through the edge cases (different inputs, data types etc) when trying to fix the bug. Furthermore, the agent seems to always try to find the relevant tests in the current repository to ensure that the proposed changes don't break existing regression tests on the codebase.

Adaptive Use of More Thinking Tokens Depending on Step Complexity
Unlike single-step non-agentic coding tasks, a key characteristic of multi-step SWE tasks is that different steps might have highly varying complexity. For instance, consider a human solving a SWE task or Github issue. While they may spend longer thinking about the root cause and how to fix the bug, other steps such as scrolling through a file or running existing scripts might take little to no thinking.
We find a similar behavior also emerges from the DeepSWE-Preview model as RL training progressed. The model learns to allocate a large number of thinking tokens while trying to localize and think of how to fix the bug (often using ~2K tokens for thinking at a single step). However, for other steps such as moving through a file or searching for a term in the codebase, it uses very few thinking tokens (~100-200).
6 - Other Attempted Experiments 🔬
We also share some other attempted experiments that did not work well for us during the training process. While the same might not indicate a negative assertion, it may provide some insights for the research community which can learn or further build upon our attempts.
SFT using Claude-Sonnet 3.7/4 instead of Cold Start
We have attempted RL on top of four SFT'ed models, Claude-Sonnet 3.7/4 with thinking/non-thinking trajectories on top of Qwen3-32B . For all attempts, the model performance did not improve after 100 iterations. Our SFT'ed models were slightly less performant than SWE-agent-LM-32B.
Different RL Training Datasets and Environments
In addition to R2E-Gym we have attempted RL on two alternative datasets—SWE-Smith [5] and SWE-Gym [6]. In our experiments, so far we observed limited performance improvements with the other datasets, often showing high solve-none rate (across different GRPO attempts) during training. Overall, we found that R2E-Gym works best for RL training, since it provided sufficient curriculum learning for the agent to solve increasingly more difficult problems over time.
We leave the study of optimal data curation for scalable RL with SWE agents, as a direction for exciting future work.
Non-thinking mode
We've also tried RL over non-thinking mode for Qwen3-32B and observed limited performance improvement. However, given that Claude-4's non-thinking and thinking mode achieve similar performance for SWE-Bench-Verified, this may just be a model capacity issue.
7 - Future Work
DeepSWE-Preview marks our first step demonstrating that pure RL-driven reasoning can be used to scale long-horizon multi-step agents given high-quality execution environments such as R2E-Gym. In future, we plan to explore some very exciting avenues for further research which we didn't explore yet due to time & resource constraints.
As DeepSWE-Preview is trained from scratch, similar to DeepSeek-R1-Zero, we plan to further train another model on top of DeepSWE-Preview analogous to DeepSeek-R1 , in addition to training larger models with longer context. Finally, we're expanding into different agentic domains, such as web agents.
8 - Conclusion
We are thrilled to unveil DeepSWE-Preview, a coding agent trained exclusively with Reinforcement Learning (RL) from the Qwen3-32B model. It achieves a e 59.2% pass rate with TTS (42.2% Pass@1 and 71.0% Pass@16) on SWE-Bench-Verified.
DeepSWE-Preview is powered by rLLM, Agentica's open-source framework for post-training language agents. Our mission is to democratize RL for LLMs, and DeepSWE-Preview is our latest milestone, building on the foundation of our previous math and coding models, DeepScaleR and DeepCoder.
To accelerate community progress, we are open-sourcing everything: the dataset, our training code & recipe, and evaluation logs. We believe scaling agent capabilities is a collective endeavor. Explore our work, reproduce our results, and help us push the frontiers of RL and agentic AI.
Let's build the future, together.
Major Individual Contributions
This project is a product of a beautiful joint collaboration between the Agentica team and Together AI. Here are the following contributions for different members:
- Michael Luo - Trained the DeepSWE RL model; developed the Kubernetes wrapper for R2E-Gym; implemented the agent/environment abstractions for rLLM, and optimized rLLM's performance.
- Naman Jain, Jaskirat Singh - Developed R2E-Gym and performed extensive data filtering for high-quality RL datasets. Designed the DeepSWE agent scaffold; prepared SFT data (thinking / non-thinking), trained SFT models, and trained verifiers (hybrid, execution-free, and execution-based) for effective test-time scaling.
- Sijun Tan, Colin Cai - Designed and implemented the initial rLLM system for training DeepSWE; co-developed trajectory- and step-level GRPO/PPO algorithm; validated the RL training loop and supported early-stage agent training.
- Ameen Patel, Qingyang Wu, Alpay Ariyak (Together AI team) - Co-led project, including experiment design, with Michael and Sijun. Generated R2E-Gym trajectories for SFT+verifier training; evaluated DeepSWE and baseline models for final experiments; and managed GPU/Kubernetes infrastructure, resolving technical challenges throughout the RL training lifecycle.