
TL;DR
Learn how to evaluate and benchmark large language models using datasets like MMLU, GSM8K, and HumanEval. Going further, we’ll also explore methods and best practices for reliable, real-world LLM performance testing.
Large language models (LLMs) have transformed how we interact with AI, from powering chatbots to generating code and solving complex mathematical problems. But as these models become increasingly sophisticated, a critical question remains: How do we actually measure their capabilities and determine which models are truly better?
The answer is benchmarks and evaluation frameworks — the systematic approaches we use to test, compare, and understand LLM performance. Understanding how to properly evaluate LLMs is essential.
In this blog we'll explore everything you need to know about LLM evaluation, from the fundamental principles of good benchmarks to the various evaluation methodologies used in practice. Additionally, we also include practical code notebooks to help you get hands on running evals for real-world use-cases we see our customers working on everyday!
Why LLM benchmarks and evaluations matter
The foundation of progress
Benchmarks serve as the compass for AI development and progress. They allow us to answer fundamental questions: Is Kimi-K2 better than Claude for agentic coding tasks? How much have language models improved at mathematical reasoning over the past year? Which fine-tune of an open-source model performs the best on your internal evaluations?
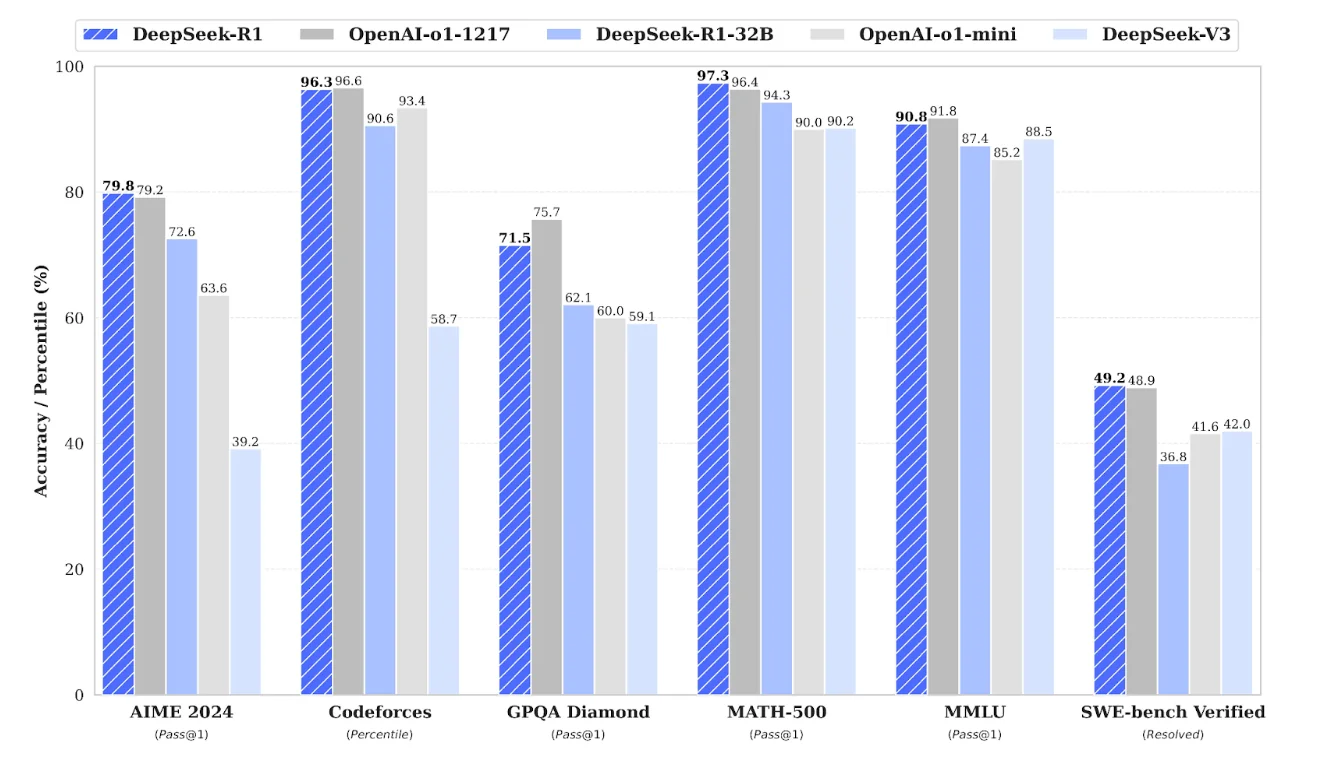
Consider the release of DeepSeek R1, which made headlines for its competitive performance against frontier models. The company's claims weren't based on subjective impressions, they were backed by systematic evaluation across six different benchmarks, including AIME 2024, CodeForces, GSM8K, and GPQA Diamond. This standardized comparison allowed the AI community to quickly understand where DeepSeek R1 stood relative to previously released and established models like OpenAI's o1 and Anthropic Claude series.
Tracking the AI revolution
Benchmarks also help us track broader trends in AI capabilities. Take the MMLU benchmark, which tests knowledge across 57 college-level subjects. By plotting MMLU performance over time, we can see that last year we passed this fascinating inflection point: open-source models are now on par in performance — or in some cases better than — closed-source systems, marking a significant shift in the AI landscape.
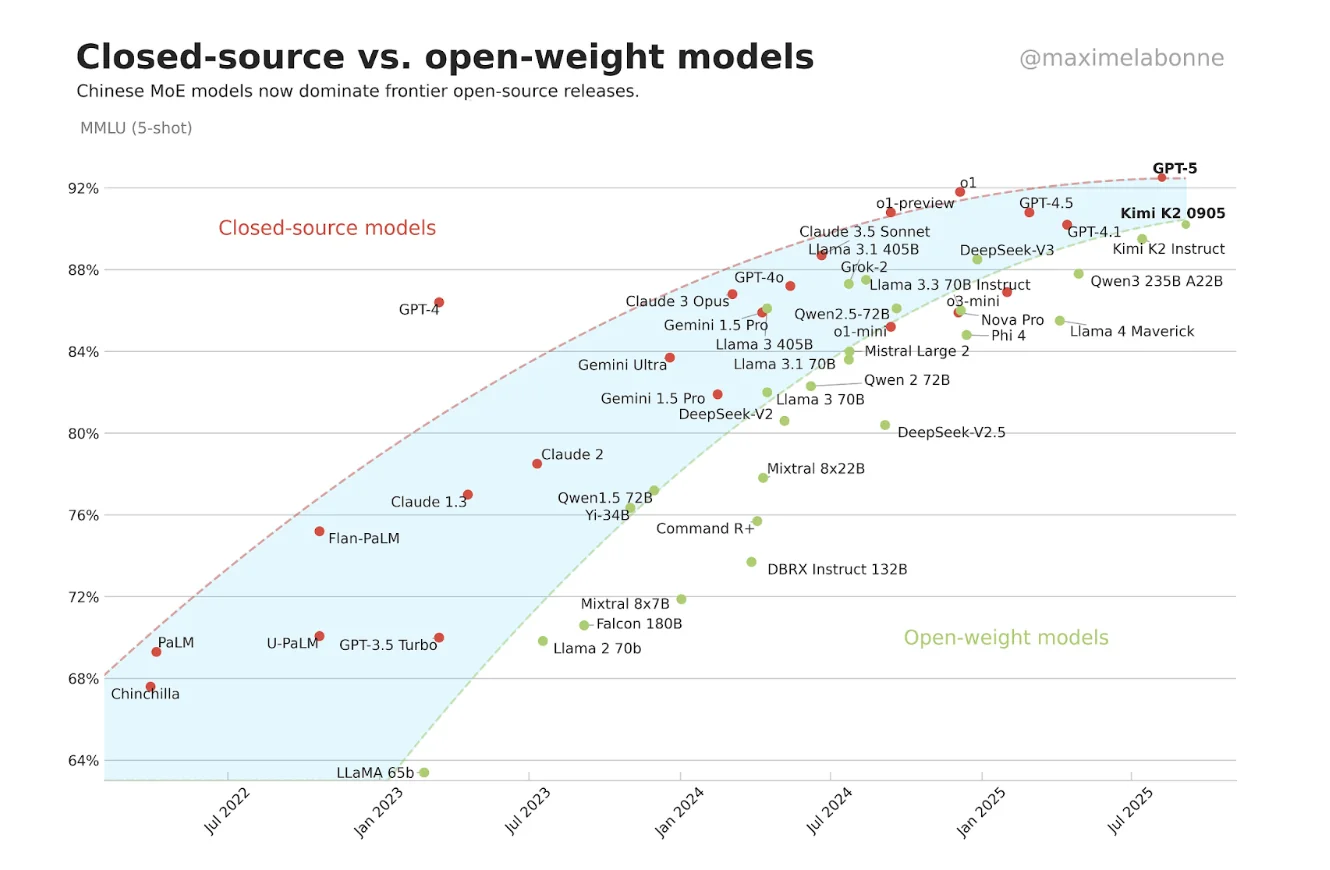
This convergence isn't just academic, it has profound implications for how organizations deploy AI, how researchers access cutting-edge capabilities, and how the entire AI ecosystem evolves.
Identifying capabilities and limitations
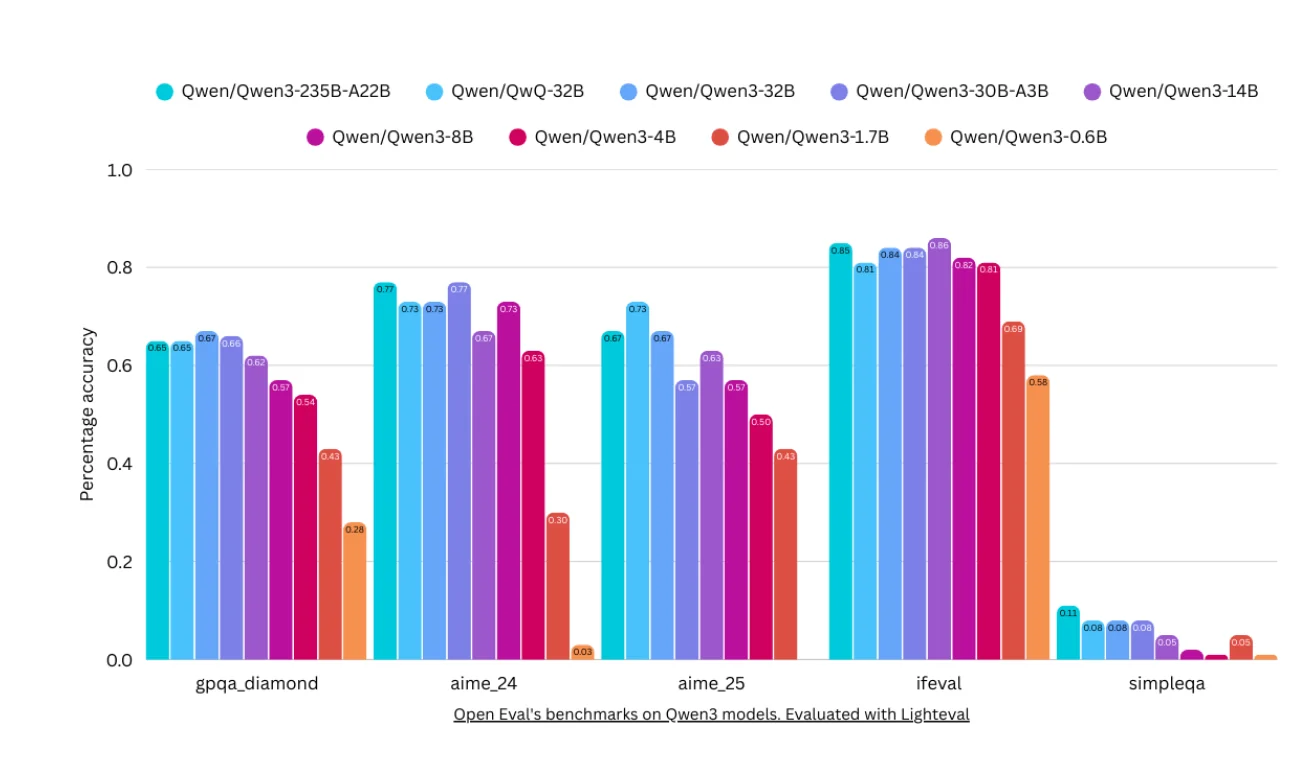
Perhaps most importantly, benchmarks also help us understand not just what models can do, but what they cannot do. They reveal blind spots, highlight areas needing improvement, and guide research priorities. This is crucial for building reliable AI systems and setting appropriate expectations for real-world deployment. A great example of this is seen in recently released models that actually show degraded performance on general knowledge benchmarks like SimpleQA from OpenAI. For example, Qwen3 235B outperformed many other models on most agentic and reasoning benchmarks — but when evaluated for general knowledge, it severely underperforms! This has since been rectified with the newer Instruct and Reasoning versions of Qwen3, performing significantly better on SimpleQA.
What makes a good LLM benchmark? Five key principles.
Not all benchmarks are created equal. The most valuable evaluation frameworks share five key characteristics that make them reliable indicators of model capability.
1. Difficulty: The moving target challenge
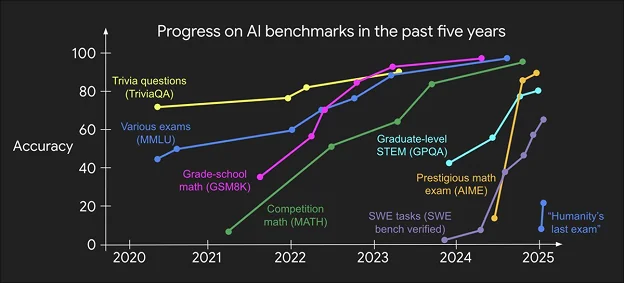
A good benchmark must be challenging enough to distinguish between different models. This might seem obvious, but it's harder to achieve than you might think. Consider MATH, a benchmark featuring competition-level mathematical problems (shown in green in the plot below). When it was first introduced, state-of-the-art models achieved single-digit accuracy scores — the problems seemed nearly impossible for AI systems to solve.
Fast-forward to today, and the same benchmark sees models achieving over 90% accuracy. What was once a discriminating test has become routine for modern systems. This illustrates the "benchmark saturation" phenomenon: as models improve, previously challenging benchmarks become easy, requiring researchers to constantly develop new, more difficult evaluations.
The trend is accelerating as can be seen in the plot above. While it took nearly four years for models to achieve high performance on MMLU, newer benchmarks like GPQA (PhD-level questions) saw rapid improvement within just a year. This acceleration reflects the unprecedented pace of AI development we're witnessing and highlights the importance of having increasingly difficult benchmarks that can help us distinguish between the best models.
2. Diversity: Beyond single-domain testing
Large language models are general-purpose systems that people use for everything from entertainment to work and everything in between, so their evaluation should reflect this breadth. A benchmark that only tests mathematical reasoning might miss crucial limitations in common sense reasoning or creative writing. The MixEval framework illustrates this principle well, showing how different domains — from STEM fields to social dynamics — occupy distinct regions in the evaluation space.
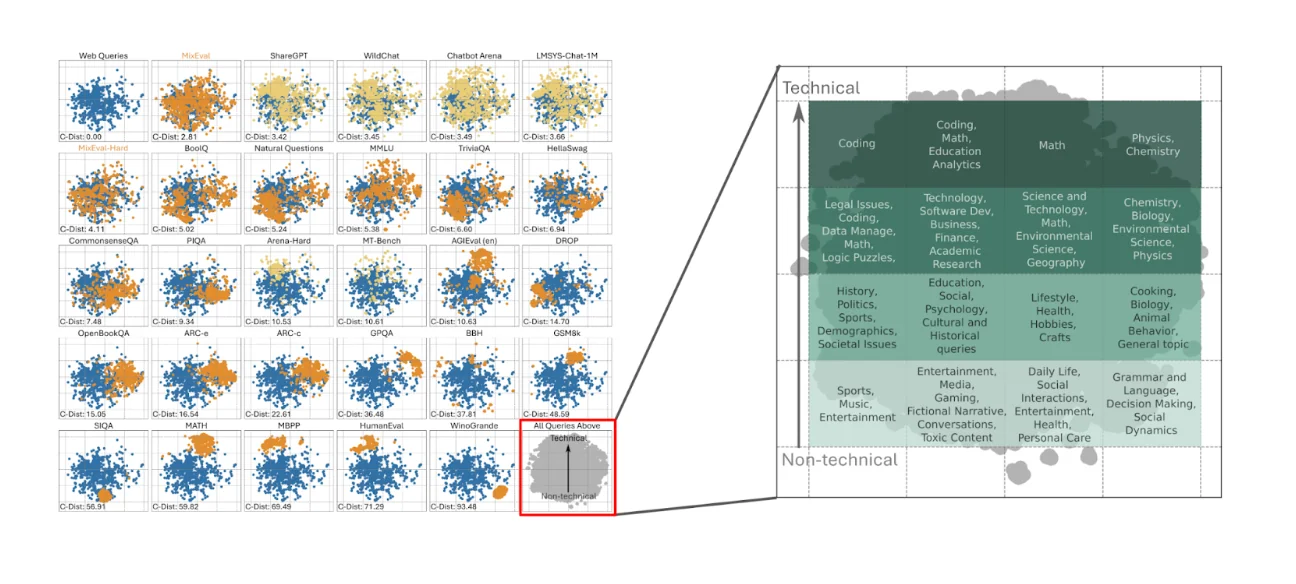
This diversity requirement operates on two levels. First, we need multiple benchmarks covering different capabilities. Second, individual benchmarks should contain varied question types to avoid being "gamed" by models that excel at specific patterns but lack genuine understanding.
3. Usefulness: Connecting benchmarks to real-world AI use cases
A benchmark might be difficult and diverse, but if it doesn't connect to real-world applications, its value is limited. The best benchmarks test capabilities that either directly matter for users or serve as foundations for more complex tasks.
Take GSM8K, which tests mathematical word problems. Why does this matter? First, it serves as a foundation for more complex quantitative reasoning tasks like financial analysis. Second, it directly helps users (students can ask ChatGPT for homework help). Third, it provides a measurable proxy for broader reasoning capabilities, helping researchers study whether AI systems can truly "think" through problems.
Similarly, HumanEval tests coding abilities through LeetCode-style problems. This benchmark is valuable because coding skills transfer to building software agents, help users prepare for technical interviews, and provide insights into AI systems' ability to translate natural language into precise instructions.
4. Reproducibility: The hidden complexity
One of the most overlooked aspects of good benchmarks is reproducibility. The same evaluation should yield consistent results across different implementations and researchers. Unfortunately, this is harder to achieve than it might seem.
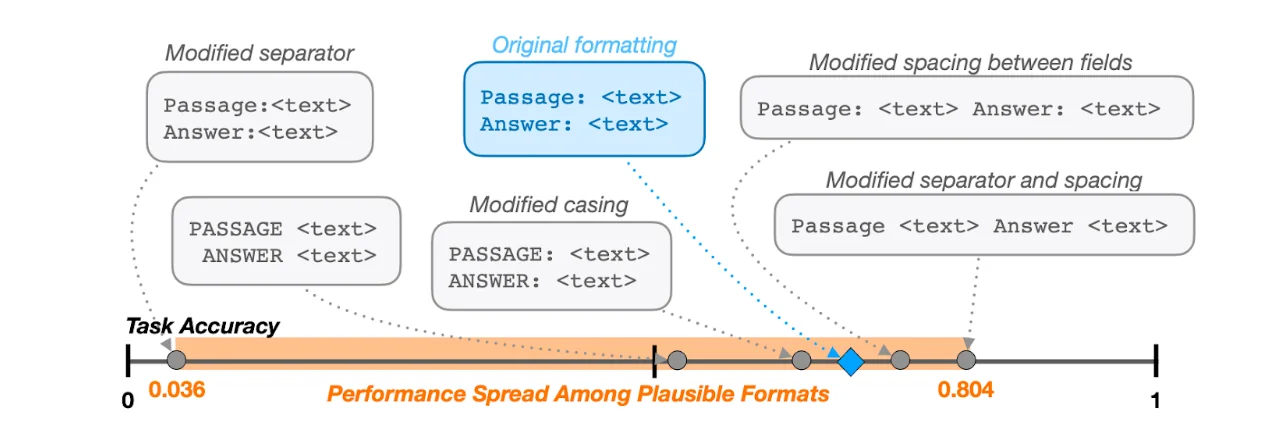
Consider the MMLU benchmark, which asks models to choose between four multiple-choice options. This sounds straightforward, but there are actually multiple ways to implement the evaluation:
- Original approach: Prompt the model with options A, B, C, D and compare the probability of each token
- Alternative approach: Include all possible tokens when comparing probabilities
- Sequence-based approach: Compare the probability of the full text description for each option
When researchers from different institutions implemented these approaches, they got different results and model rankings — this can be seen in the diagram below showing the high variance in performance from seemingly small input prompt changes. This inconsistency is concerning because it means conclusions about model capabilities might depend on implementation details, rather than actual performance differences.
5. Data contamination: The invisible problem
Perhaps the most insidious challenge in LLM evaluation is data contamination, when benchmark questions appear in a model's training data. Modern language models are trained on vast amounts of internet text, potentially including academic papers, textbooks, and websites containing benchmark questions.
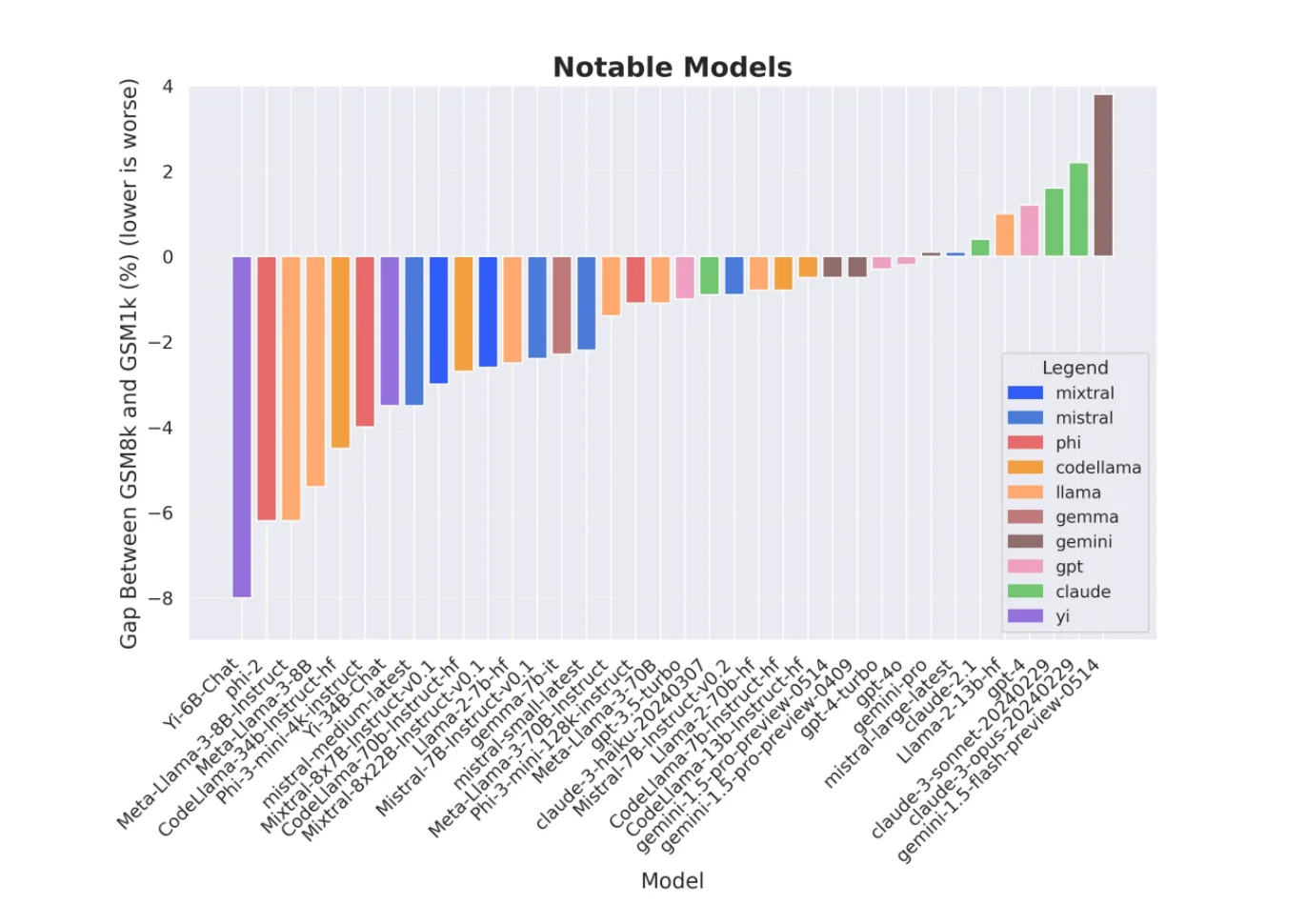
The GSM8K vs. GSM1K comparison illustrates this problem perfectly. GSM8K is a widely-used benchmark of mathematical word problems, while GSM1K contains similar problems that are guaranteed to be novel. When researchers compared model performance on both benchmarks, they found that many models scored significantly lower on GSM1K, suggesting that high GSM8K scores might partially reflect memorization — rather than genuine mathematical reasoning ability.
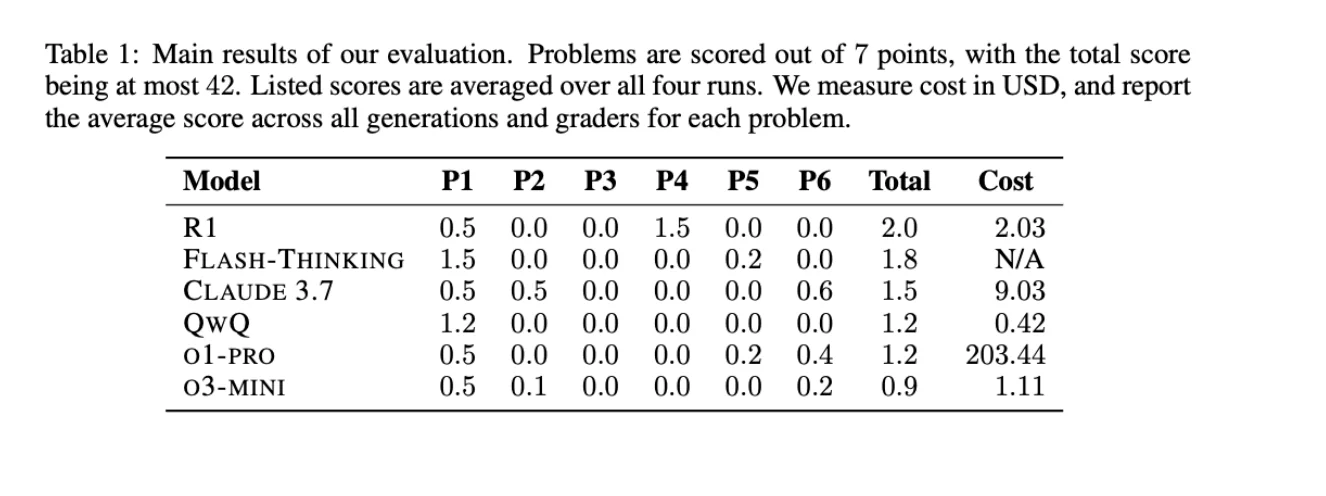
This problem is even further highlighted when looking at data contamination in MATH benchmarks. When SoTA models were evaluated on the U.S. Math Olympiad (USAMO 2025) hours after it was released (to eliminate the possibility of data contamination at all) even the best reasoning models at the time performed horribly at below 5%!
This contamination problem is particularly acute for open-source models and datasets, where the training data overlap with test data is more likely and harder to detect.
Types of LLM evaluation methods
LLM evaluation encompasses several distinct approaches, each with its own strengths and appropriate use cases.
Multiple choice and classification benchmarks
The most straightforward evaluations present models with multiple-choice questions or classification tasks. These benchmarks offer clear, objective scoring and are easy to implement at scale. Examples here include:
- MMLU (Massive Multitask Language Understanding): Tests general knowledge
- HellaSwag: Common sense reasoning
- MATH: mathematical problem solving
The evolution of these benchmarks reveals an interesting pattern. We often see benchmark "families" where newer versions replace older ones as models improve. SWAG was superseded by HellaSwag, GLUE by SuperGLUE, and MMLU by MMLU-Pro (which increased the number of answer choices to make problems more challenging).
Together AI helps with running classification evaluations in our new Evaluations API, if you’d like to see coded implementations check out our notebook!
Generation and open-ended evaluation
While multiple-choice questions are easy to score, they don't capture how we actually interact with language models. In practice, we ask models to generate free-form responses, making generation evaluation crucial for understanding real-world performance. Examples here include:
- GSM8K (Grade School Math): Tests step-by-step mathematical reasoning with automatic answer verification
- HumanEval: Evaluates code generation through function completion with test cases
- TruthfulQA: Measures factual accuracy and resistance to hallucination
These evals trade-off being closer to real-world use-cases for ease of evaluation. It’s easy to mark multiple choice questions or closed-form math problems, but more difficult to evaluate all the right steps it took to get the right answer or evaluate between the various correct ways to code up a solution to a problem.
Human evaluation
If we want to even further improve how to run eval models in real-world usage, we can look at human evaluation, which captures nuanced quality factors that automated metrics often miss — though it comes with challenges of scale and consistency.
LM Arena represents the gold standard for human evaluation. Users interact with anonymous models and vote on which responses are better. This crowdsourced approach generates Elo rankings that reflect real user preferences across diverse queries.
The Arena's strength lies in its scale, capturing and crowdsourcing preferences across millions of conversations spanning every topic imaginable. However, the queries tend to be heavily weighted toward casual conversation, rather than specialized professional tasks.
Specialized Human Evaluation focuses on specific domains like coding Code Arena, software engineering (SWE-bench) or HealthBench. These evaluations often involve domain experts who can assess technical correctness and quality factors that general users might miss.
LLM-as-a-judge
Using language models to evaluate other language models has gained significant traction due to its scalability and flexibility. This approach mixes the practicality of evals being representative of real-world usage, while still keeping scalability in mind with the use of LLM’s — instead of humans to perform the actual evaluation of other LLMs!
Alpaca Eval 2.0 uses GPT-4 as a judge to rate model responses against reference answers, providing win rates for different models. Arena Hard curates difficult prompts from the Chatbot Arena to create a challenging evaluation set. Multi-turn benchmarks assess conversational ability across extended interactions.
The major advantage of LLM-as-a-judge is customizable evaluation criteria. Unlike fixed metrics, you can instruct the judge to evaluate specific aspects like technical accuracy, clarity for beginners, or use of industry terminology.
However, this approach has notable limitations. Judge models tend to prefer longer responses regardless of quality, and they often exhibit bias toward responses from models of their own family (GPT models preferring GPT responses, etc.). Proper calibration and bias correction are essential for reliable results an example of this is the style control added to LM Arena.
We help make running LLM as a judge evaluations in our new Evaluations API, if you’d like to see coded implementations check out our notebook!
Best practices for reliable LLM evaluation
Effective LLM evaluation requires using multiple complementary benchmarks rather than relying on any single metric, as different benchmarks capture different aspects of model capability. Align your evaluation criteria with your actual use cases: if you're building a customer service chatbot, prioritize helpfulness and conversational ability over creative writing or mathematical reasoning. Account for data contamination risks by using novel test sets and interpreting results with appropriate skepticism.
For production systems, implement continuous evaluation frameworks to monitor performance over time, as models can drift due to changes in user behavior, data distribution, or updates. Conduct A/B testing with real users to validate that benchmark improvements actually translate to better experiences, and establish clear triggers for retraining or replacement when performance degrades below acceptable thresholds.
Evaluating LLMs is both an art and a science, requiring careful consideration of not just what to measure, but how to measure it reliably and meaningfully. As language models become more powerful and ubiquitous, robust evaluation frameworks grow increasingly critical. The evaluation landscape evolves rapidly with new benchmarks and methodologies emerging constantly, but the core principles remain: use multiple perspectives, align evaluations with real-world needs, and maintain healthy skepticism about any single metric. The ultimate question isn't whether models can pass our tests, it's whether our tests are sophisticated enough to ensure these systems safely and effectively serve their intended purposes.