

Future of AI
Most current AI benchmarks focus on answering questions about the past, either by testing models on existing knowledge (in a static manner, such as HLE or GPQA, or augmented, like BrowseComp or GAIA) or previously solved problems (like PaperBench, DABStep, or most coding evaluations). However, we believe that more valuable AI, and ultimately AGI, will be distinguished by its ability to use this past to forecast interesting aspects of the future, rather than merely reciting old facts.
Forecasting future events is a complex and holistic task: it requires sophisticated reasoning, synthesis, weighing probabilities and genuine understanding, rather than pattern matching against or searching existing information. Evaluating models on their ability to predict future outcomes, whether in science, economics, geopolitics, or technology tests the kind of intelligence that creates real-world value.
Beyond its inherent importance, this forecasting-based approach also solves many methodological problems faced by current evaluations and benchmarks. Traditional benchmarks that measure accuracy on fixed test sets are inevitably affected by possible data contamination, and without access to the full reproducible training pipeline of a model, it's hard to trust the results. The most serious evaluation efforts now keep their test sets completely private, creating a frustrating arms race between evaluators and potential "gaming the leaderboard" mechanics (Singh et al., 2025).
Forecasting makes contamination impossible by design, as you can't train on data that doesn't yet exist! This creates a level playing field where success depends on reasoning capability rather than memorization.
Perhaps most importantly, predictions about the future are inherently verifiable. We can wait and see who was right, creating an objective, time-stamped measure of model performance.
We therefore propose evaluating agents on their ability to predict future events (Ye et al., 2024; Karger et al., 2025). FutureBench draws from real-world prediction markets and emerging news to create interesting prediction tasks grounded in actual future outcomes. We collect events from platforms and live news coverages and manifolds markets, filtering them to focus on emerging events worth predicting. Using an agent-based approach, we curate scenarios that require genuine reasoning rather than simple pattern matching. Think geopolitical developments, market movements, or technology adoption trends - events where informed analysis actually matters.
Can Agents Predict Future Events?
This is the obvious question, and it's at the heart of what makes this benchmark interesting! We believe the answer cannot be a simple "yes" or a "no", as it mostly depends on the actual questions; there are always important caveats to consider.
Humans constantly use their ability to weigh current information to predict future events. Aren't most career moves, relationship choices, or even business strategies essentially bets on future outcomes?
Some predictions involve irreducible uncertainty (Will it rain on December 17th, 2027 at noon?), but many don't. When a skilled analyst predicts a company's quarterly earnings or a policy expert forecasts election outcomes, they're using available information to make informed decisions. This is precisely what we're asking AI agents to do with FutureBench! The task isn't to get agents to fortune-tell, but rather to synthesize information and reason under stronger uncertainty than most other benchmarks.
The agent's prediction quality directly reflects its ability to search relevant information, synthesize complex data, and reason about cause-and-effect relationships. These are precisely the capabilities we want to measure in real-world applications.
Tools like DeepResearch are already used for market analysis and strategic planning. The quality of information collection strongly correlates with decision-making effectiveness. FutureBench is inspired by this evaluation process and tries to compute agents' quality with objective, verifiable outcomes.
FutureBench
How We Generate Prediction Questions
Building a benchmark that tests real prediction capabilities requires a steady stream of meaningful questions. We've developed two complementary approaches that capture different types of future events:
1. News-Generated Questions: Finding Tomorrow's Headlines Today
Our first approach uses AI to mine current events for prediction opportunities. We deploy a smolagents-based agent to scrape a few major news websites, analyze front-page articles, and generate prediction questions about their likely outcomes. The agent reads through and identifies interesting articles and formulates specific, time-bound questions from their content, for example "Will the Federal Reserve cut interest rates by at least 0.25% by July 1st, 2025?".
We guide this process with carefully crafted prompts that specify what makes a good prediction question—events that are meaningful, verifiable, and uncertain at extraction time.
Technical Stack:
- Model: DeepSeek-V3 for reasoning and question generation
- Scraping: Firecrawl for reliable content extraction
- Search: Tavily for additional context when needed
The agent typically generates 5 questions per scraping session, with a time horizon of a single week, meaning that we assume we'll know the answer to the question after seven days. This gives us a natural pipeline of fresh evaluation material tied to real-world events.
2. Polymarket Integration: Leveraging Prediction Markets
Our second source draws from Polymarket. These questions come from a prediction market platform where real participants make forecasts about future events. We currently ingest around 8 questions per week.
However, the raw data needs filtering. We apply strong filtering to remove general questions regarding temperature and some questions regarding the stock and crypto markets, which would otherwise be too numerous for practical use in our benchmark.
In addition to this, polymarket questions have less constraints regarding the final "realization" time, the actual outcome of the event could be available only next month or by the end of the year. These are still very relevant questions, but the data collection of the outcome is more sparse.
Example Questions
Here's an example of what comes out of our question generation pipeline:

Three Levels of Systematic Evaluation
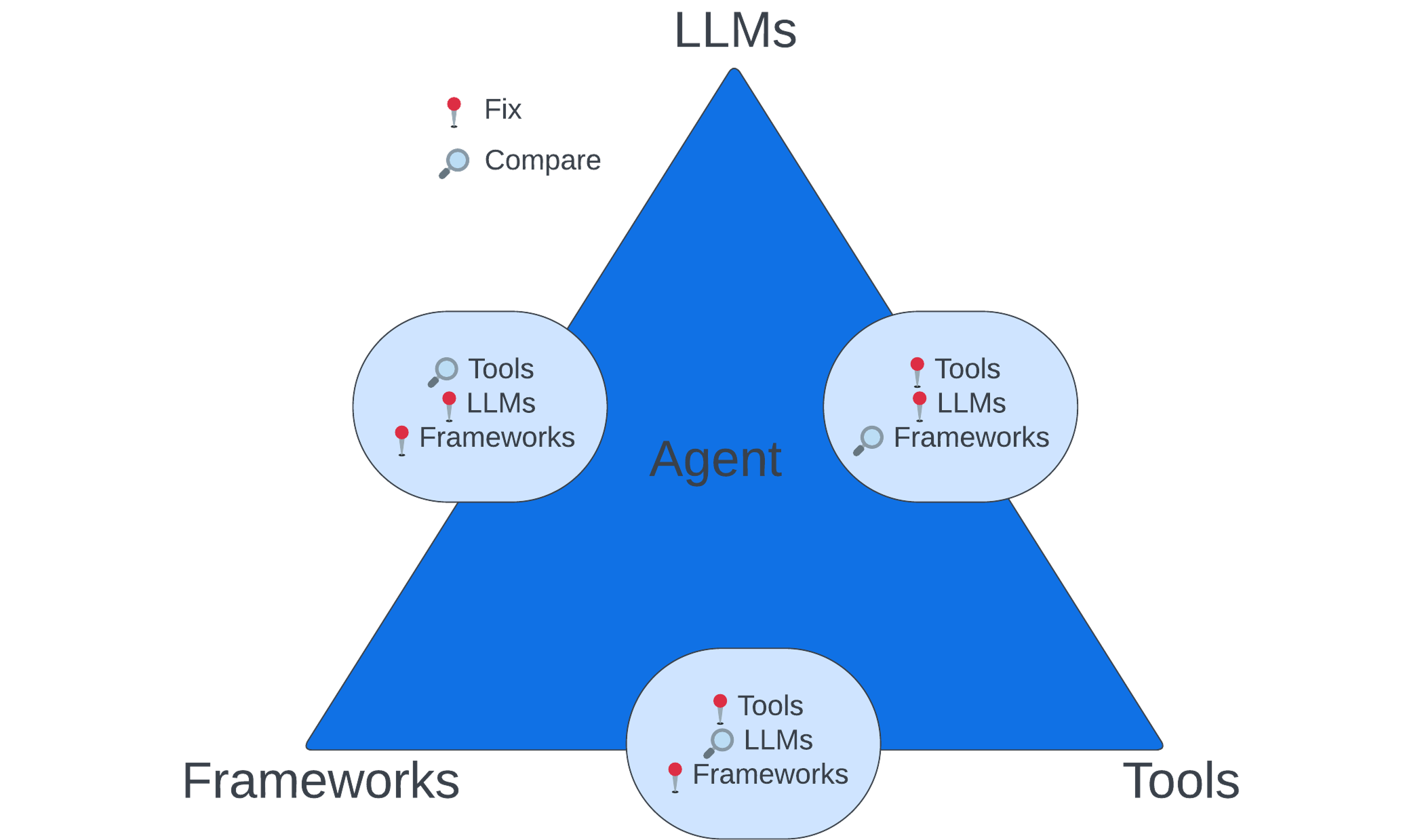
The next question is, what does this type of benchmark allow us to measure? The framework operates on three distinct levels, allowing us to isolate exactly what we're measuring:
Level 1: Framework Comparison
Keep the underlying LLMs and tools constant while varying frameworks. How does a LangChain-based agent compare to one built with CrewAI when both use GPT-4 and the same search tools? This isolates the impact of different agentic frameworks.
Level 2: Tool Performance
Fix the LLM and framework while comparing different implementations. Which search tool (for example Tavily, Google, Bing) leads to better predictions than other search engines, holding everything else constant? This reveals which tools actually provide value. How much value do tools bring in general with respect to models without tools?
Level 3: Model Capabilities
Hold the framework and tools constant while testing different LLMs. Given access to the same set of tools, does DeepSeek-V3 use them as effectively as GPT-4? This measures pure reasoning ability.
This systematic approach lets us understand exactly where performance gains and losses occur in the agent pipeline.
The benchmark also serves as a robust test of instruction following. Agents must respect specific formatting requirements and generate actions that can be correctly parsed and executed. In practice, this often reveals where smaller language models struggle with complex multi-step reasoning.
🚀 Try it yourself! Explore the live leaderboard: FutureBench Interactive Leaderboard
Predicting The Future: Agents and Initial Results
We use SmolAgents as a baseline agent framework for all the questions. We also compute performance on the base models. For the prediction task itself, the agents get access to a focused toolkit:
- Search: Tavily integration for finding recent information and expert analysis
- Web Scraper: A simple web scraping tool for following up on specific sources and getting detailed context.
This intentionally lean setup forces agents to be strategic about information gathering while still providing the tools needed for informed predictions.
Initial Results

We compare different models using smolagents as a baseline. We also run the standard language models without internet access to estimate a general prior. As expected, we see agentic models performing better than simple language models; stronger models show more stable prediction quality. Overall we also find interesting patterns in how different models try to approach a question:
Interesting Action Patterns
Running this benchmark has revealed insights into how different models approach information gathering. One striking difference is with respect to scraping. GPT-4.1 appears to rely more on search results. Claude3.7 and 4 explore the web space in more detail and tend to use web scraping more frequently; this thorough approach also means collecting many more input tokens during the research process, thus increasing the cost.
Models show interesting approaches to making predictions, for example, to answer the question "Will annual inflation increase by 2.6 or more in June?":
- The DeepSeekV3 agent analyzed June 2025 inflation prospects by searching recent CPI data (finding current inflation at 2.4-2.8%), considered tariff impacts as upward pressure, and concluded inflation would exceed the 2.6% threshold.
- Claude3.7 analyzed June 2025 inflation through comprehensive research (11 searches vs DeepSeekV3's 3), systematically gathering May 2025 CPI data (2.4% year-over-year), identifying decelerating monthly trends (0.2%→0.1%), weighing tariff pressures against Fed restrictive policy, calculating precise 0.2% gap needed, and concluded recent deceleration made reaching 2.6% threshold unlikely, answering "No."
- GPT4.1 analyzed June 2025 inflation through targeted searches for market consensus and forecasts, identified May 2025 CPI at 2.4% (below 2.5% expectations), noted weak 0.1% monthly increases, found no forecaster predictions of 2.6%+ for June, and concluded the jump from 2.4% to 2.6% was unlikely given recent below-expectation trends.
Interestingly, Claude was the only model that tried to access the Bureau of Labor Statistics website to scrape it directly, which failed because it is a .gov website and we do not allow this type of action.
The models exhibit distinct reasoning patterns in their outputs. GPT's analysis focused on consensus forecasts as the key signal for future events rather than extrapolating from current data, while Claude's approach exhibited rigorous analytical structure with its systematic pro/con framework and quantitative gap analysis, and DeepSeekV3's output displayed explicit acknowledgment of data limitations and systematic methodology adjustments when initial approaches encountered constraints.
These behavioral differences reveal interesting patterns in how different models approach information gathering. The variations in web usage and token consumption suggest that models have distinct strategies for tackling prediction tasks, which FutureBench can help us measure and understand.
Limitations and Future Directions
One challenge is that evaluation can be expensive due to the large number of input tokens. For example, Claude tends to visit web pages frequently, thus accumulating many input tokens. In a multi-turn loop, this can make the number of input tokens skyrocket very quickly. This increases the cost of any subsequent generation, even though most tokens are eventually cached.
FutureBench is an evolving benchmark, as we discover new findings and better patterns, we'll keep incorporating them. We would love feedback from the community to understand how to better source questions, which experiments to run and which data is the most interesting to analyze.
References
Singh, S., Nan, Y., Wang, A., D'souza, D., Kapoor, S., Ustun, A., Koyejo, S., Deng, Y., Longpre, S., Smith, N., Ermiş, B.H., Fadaee, M., & Hooker, S. (2025). The Leaderboard Illusion. ArXiv, abs/2504.20879.
Karger, E., Bastani, H., Yueh-Han, C., Jacobs, Z., Halawi, D., Zhang, F., & Tetlock, P.E. (2025). ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities. ICLR.
Ye, C., Hu, Z., Deng, Y., Huang, Z., Ma, M.D., Zhu, Y., & Wang, W. (2024). MIRAI: Evaluating LLM Agents for Event Forecasting. ArXiv, abs/2407.01231.