

For AI models to be effective in specialized tasks, they often require domain-specific knowledge. For instance, a financial advisory chatbot needs to understand market trends and products offered by a specific bank, while an AI legal assistant must be equipped with knowledge of statutes, regulations, and past case law.
A common solution is Retrieval-Augmented Generation (RAG), which retrieves relevant data from a knowledge base and combines it with the user’s prompt, thereby improving the model's output. However, enterprise knowledge often resides in formats like PDFs, PowerPoint decks, or scanned documents, making it difficult to retrieve and prepare the relevant parts for injection into a prompt we can send to a LLM.
Traditionally, this problem is tackled by extracting text using pipelines that incorporate optical character recognition(OCR) for scanned text, language vision models to interpret visual elements like charts and tables, and augmenting text and descriptions with structural metadata such as page and section numbers. The challenge is that this process varies depending on the nature of the documents and the organization’s storage formats.
In this post, we’ll explore a new method, called ColPali, which allows us to index and embed document pages directly, bypassing the need for complex extraction pipelines. Combined with cutting-edge multimodal models like the Llama 3.2 vision series, ColPali enables AI systems to reason over images of documents, enabling a more flexible and robust multimodal RAG framework.
Code Notebook - PDF RAG with Nvidia Investor Deck
If you want to jump directly into the code where I show the implementation of multimodal RAG over Nvidia’s investor slide deck from last year refer to the notebook here. I use ColQwen2 as an image retriever and Llama 3.2 90B Vision on Together AI to enable users to ask questions to the PDF.
Basic RAG Overview
Retrieval-Augmented Generation (RAG) is a powerful technique that allows AI models to access and utilize vast amounts of external knowledge, far beyond what can fit within their context windows. This approach significantly enhances the AI's ability to provide accurate, up-to-date, and contextually relevant information.
RAG operates by preprocessing a large knowledge base and dynamically retrieving relevant information at runtime. Here's a breakdown of the process:
- Indexing the Knowledge Base:
The corpus (collection of documents) is divided into smaller, manageable chunks of text. Each chunk is converted into a vector embedding using an embedding model. These embeddings are stored in a vector database optimized for similarity searches.
- Query Processing and Retrieval:
When a user submits a prompt that would initially go directly to a LLM we process that and extract a query, the system searches the vector database for chunks semantically similar to the query. The most relevant chunks are retrieved and injected into the prompt sent to the generative AI model.
- Response Generation:
The AI model then uses the retrieved information along with its pre-trained knowledge to generate a response. Not only does this reduce the likelihood of hallucination since relevant context is provided directly in the prompt but it also allows us to cite to source material as well.

Now let’s discuss a new multimodal spin on this vanilla RAG pipeline!
Efficient Document Retrieval Using Vision Language Models
In the world of enterprise knowledge management, we often encounter a significant challenge: how to effectively index and retrieve information from complex document formats like PDFs, PowerPoint presentations, and scanned documents. Traditional methods involve multi-step processes that can be both time-consuming and error-prone. Enter ColPali, a new image retrieval approach that streamlines document retrieval by leveraging the power of vision language models.
The Traditional Approach vs. ColPali
Conventional document retrieval systems typically follow a complex pipeline:
- Optical Character Recognition (OCR) for scanned text
- Language vision models to interpret visual elements (charts, tables)
- Text extraction and structural metadata augmentation like page and section numbers
- Chunking and embedding of extracted text
This process varies depending on document types and organizational storage formats, making it difficult to implement a one-size-fits-all solution. ColPali, on the other hand, offers a refreshingly simple alternative:
- Direct indexing and embedding of document pages as images
- Retrieval based on visual semantic similarity
By eliminating the need for text extraction and complex preprocessing, ColPali provides a more flexible and robust framework for multimodal Retrieval Augmented Generation (RAG).

How ColPali Works:
ColPali's elegance lies in its straightforward approach to document processing. At its core, ColPali leverages advanced vision language models like Google's PaliGemma(hence the usage of Pali in the name) or more recently AliBaba's Qwen-2 to transform document page images into rich semantic representations. These encoders divide each image into patches, capturing the nuanced semantics of different document areas and preserving both textual and visual information as vectors. These patch vectors can then be efficiently stored in a vector database for quick retrieval.

When a user submits a query, the ColPali retriever processes it token by token, employing a Maximum Similarity (MaxSim) operation to precisely identify the most relevant page image by comparing query tokens against stored image patch tokens. The figure below shows how the MaxSim operation works.

This interaction of the vision tokens with the language tokens allows for a very semantically rich interaction between the query and the stored documents to establish similarity. This is the same process that was proposed and popularized for text based information retrieval systems in the ColBERT paper, this is where the Col in the name ColPali comes from!

This process culminates in the retrieval and ranking of the most relevant document pages to the query. As an added feature, ColPali can generate a semantic heatmap, visually highlighting the parts of the document that most closely align with the query, thereby offering users an intuitive insight into the retrieval process. This streamlined approach enables ColPali to handle complex document formats with efficiency and accuracy.

Treating all documents as images means that the ColPali approach is document format agnostic; it can as easily process scanned documents as complex PDFs, and slide decks without the need for format-specific handling. This image-based approach also preserves the original document layout, a crucial factor in maintaining context and meaning, especially in visually rich documents.
Moreover, the underlying vision encoders from language vision models can be upgraded to improve the overall retrieval performance. Interpreting both textual and visual elements allows for a more holistic comprehension of the document's content. This capability is valuable when dealing with documents that combine text, charts, diagrams, and other visual data.
Some Shortcomings of ColPali:
The disadvantage of ColPali is that you now have to contend with a couple of orders of magnitude more vectors compared to the traditional approach. In the standard approach you might have chunked a page worth of content into 4 text chunks which could be embedded into 4 vectors. Now that same page will be split into thousands of patches and thus you end up with thousands of vectors.
There are a couple of ways to combat this growth in the number of vectors, one approach which is quite similar to ColPali is called the Document Screenshot Embedding(DSE) technique. DSE uses a bi-encoder approach for image retrieval, whereby all image patch vectors are summarized into one vector same as the query. The similarity between these two image and query vectors can then be captured using any distance metric such as cosine or euclidean similarity. The trade-off here is that now the vector isn’t as semantically rich as the ColPali multi-vector per document page approach

There are also other techniques to deal with the explosion in the number of vectors with ColPali but this is outside the scope of this post. If you’d like to explore how to efficiently handle multi-vectors please read this post.
From Retrieval to Understanding: Leveraging Llama 3.2 Vision for Image Understanding
It's important to note that ColPali's primary function is to retrieve and rank relevant document pages based on a query. It can tell you which image/page the answer or relevant content is however it won’t generate answers to questions directly. This is where we can leverage the power of advanced vision-language models like the new Llama 3.2 vision series.
By combining ColPali's efficient retrieval with Llama 3.2's ability to reason over retrieved images, we can create a powerful system that not only finds the right pages/images but also interprets and answers questions about their contents.
The new series of Llama 3.2 vision models use a technique called visual instruction tuning which is a training process that allows language models to “see” and process images! By projecting image tokens into the same latent space as text tokens and training to unify these two token spaces it imbues LLMs with vision capabilities.
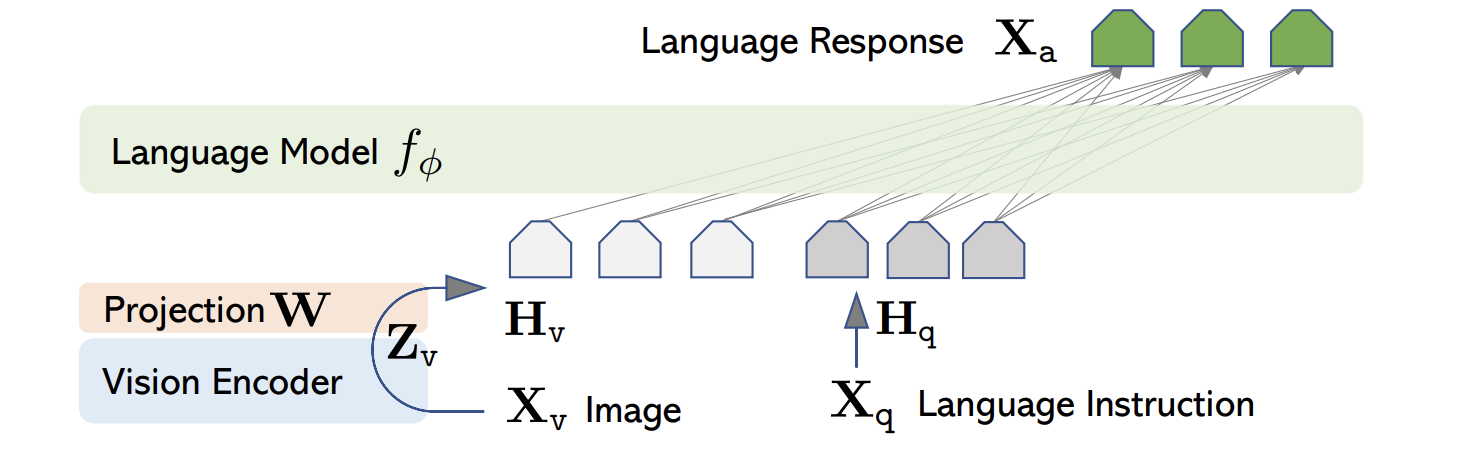
Having these vision capable language models we can complete our multimodal RAG workflow. Once ColPali identifies the top relevant pages for a given prompt, we can pass these pages along with the prompt into Llama 3.2 for completion.

Check out the Jupyter notebook connected to this blog to see this workflow implemented in code allowing you to chat with Nvidia’s detailed investor deck!