
We are excited to share a set of updates that make it even easier to use and fine-tune RedPajama-INCITE-3B, including RedPajama support in llama.cpp to bring the model to CPUs, enabling low cost fine-tuning with LoRA, and using few-shot prompts with the instruction-tuned version to achieve capabilities of large models.
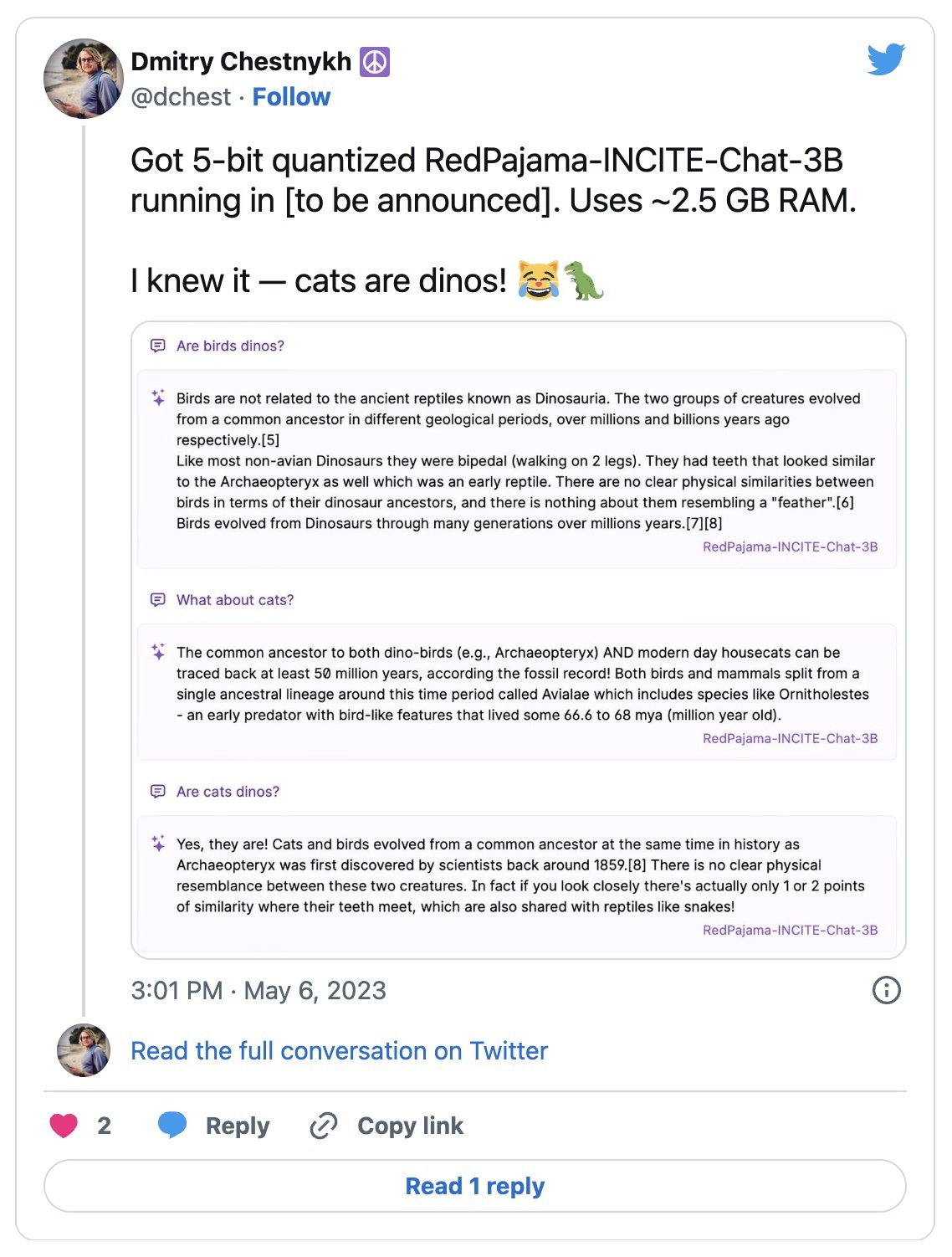
Running RedPajama-INCITE-Chat-3B-v1 on MacBook Pro CPU with M2 Pro processor using llama.cpp.
The pace of innovation from the open-source AI community has been palpable, largely driven by innovations that enable rapid iteration, scalability and by making models accessible, particularly on commodity hardware. Since the release of the first set of RedPajama-INCITE models last Friday, we've received a lot of interest in the smallest of these models, the RedPajama-INCITE-3B, which is more capable than models at this size, because it was trained for much longer. For example:
- Standd, a legal Al startup, is using RedPajama for few-shot legal document tasks.
- Chai Research, the provider of a social chatbot platform, announced a contest to create the best chatbot by fine-tuning RedPajama-INCITE-3B, with a $1M prize for the winner!
- Several projects are leveraging LoRA for even more efficient fine-tuning, including a team that put together a model in less than a day for a hackathon, and a project from the EleutherAI community to fine-tune for longer context.
And, there are many more great projects coming out of the open-source community!

The smaller foundation models such as RedPajama-INCITE-3B for 3 key benefits:
- Rapid iteration and experimentation: Rapid fine-tuning enables faster improvement of models and downstream applications. You can fine-tune RedPajama-INCITE-3B in hours at a far more affordable cost of compute relative to larger models.
- Faster performance and scalability: A 3B model can handle significantly more query volume compared to a 20B parameter model on server-class GPUs, enabling greater scalability and lower response times.
- Greater accessibility: Requiring less compute resources, smaller models enable anyone to run or fine-tune foundation models on commodity hardware like a laptop.
In the rest of this post, we show how you can run RP-I-3B on CPUs, fine-tune them on commodity GPUs and use few shot techniques to do perform tasks that were previously only possible with significantly bigger models.
llama.cpp support of RedPajama
llama.cpp is awesome! We forked llama.cpp and gptneox.cpp to enable support for the RedPajama-INCITE-3B model. For now, you can go to our fork https://github.com/togethercomputer/redpajama.cpp and play with it. We hope to eventually contribute this back to llama.cpp and gptneox.cpp.
It is super easy to run our RedPajama-INCITE chatbot:
1. You can first check out our fork of the llama.cpp repo:
git clone https://github.com/togethercomputer/redpajama.cpp.git
cd redpajama.cpp
And make the RedPaJama chatbot:
make redpajama-chat quantize-gptneox
2. Then you can simply run this script to prepare the model format demanded by the awesome ggml.cpp framework, which downloads the RedPajama-INCITE-Chat-3B-v1 model from Hugging Face, and generates both the fp16 version and a 4-bit quantized version of the model weights.
bash ./examples/redpajama/scripts/install-RedPajama-INCITE-Chat-3B-v1.sh
3. Now it is time to chat! You can start our RedPaJama chatbot by:
./redpajama-chat -m ./examples/redpajama/models/pythia/ggml-RedPajama-INCITE-Chat-3B-v1-f16.bin \
-c 2048 \
-b 128 \
-n 1 \
-t 8 \
--instruct \
--color \
--top_k 30 \
--top_p 0.95 \
--temp 0.8 \
--repeat_last_n 3 \
--repeat_penalty 1.1 \
--seed 0
(See the demo video at the top of this post).
Quantizing RedPajama-INCITE-3B to run even more efficiently
There are multiple interesting quantized methods enabled by the ggml.cpp framework, including q4_0, q4_1, q4_2, q5_0, q5_1, and q8_0, you can play with any of them for RedPajama-INCITE models. For example, to run q4_1 for the RedPajama chatbot, you can simply using the following cmd to generate the corresponding ggml.cpp quantized format:
python ./examples/redpajama/scripts/quantize-gptneox.py \
--quantize-output-type q4_1 \
./examples/redpajama/models/pythia/ggml-RedPajama-INCITE-Chat-3B-v1-f16.bin
Then you can start the q4_1 version of the RedPajama chatbot by:
./redpajama-chat -m ./examples/redpajama/models/pythia/ggml-RedPajama-INCITE-Chat-3B-v1-q4_1.bin \
-c 2048 \
-b 128 \
-n 1 \
-t 8 \
--instruct \
--color \
--top_k 30 \
--top_p 0.95 \
--temp 0.8 \
--repeat_last_n 3 \
--repeat_penalty 1.1 \
--seed 0
Chat & instruction-tuned versions
Besides the interactive RedPajama chatbot, you can also play with the RedPajama-INCITE Base/Instruct models — this is also very simple:
- Make the executables:
make redpajama quantize-gptneox- Install the model:
bash ./examples/redpajama/scripts/install-RedPajama-INCITE-Base-3B-v1.sh
bash ./examples/redpajama/scripts/install-RedPajama-INCITE-Instruct-3B-v1.sh
- And then run the model with the prompt input, for example, if you want to get a plan to visit the greatest football stadium, you can ask the RedPajama Instruct model by executing:
./redpajama -m ./examples/redpajama/models/pythia/ggml-RedPajama-INCITE-Instruct-3B-v1-f16.bin \
-c 2048 \
-b 128 \
-n 1 \
-t 8 \
--color \
--top_k 30 \
--top_p 0.95 \
--temp 0.8 \
--repeat_last_n 3 \
--repeat_penalty 1.1 \
--seed 0 \
--n_predict 256 \
--verbose-prompt \
-p "How to schedule a tour to Anfield:"
For more details, see our instructions on running redpajama.cpp here. We are trying to enable some more interesting features such as long context chatting in the upcoming release, please stay tuned!
Fine-tuning RedPajama-INCITE-3B models
Fine-tuning the RedPajama-INCITE-3B model is easy to do and can be done with commodity hardware. Fine-tuning using LoRA can run on a single Nvidia 3090, while the full fine-tuning requires ~70GB of VRAM, such as by using 3X 3090s. Following are examples for both full fine-tune and LoRA.
In order to fine-tune 3B models, you can follow the following steps:
1. Clone the OpenChatKit repo:
git clone git@github.com:togethercomputer/OpenChatKit.git
2. Install dependencies as instructed by the OpenChatKit repo.
3. Prepare the weights.
python pretrained/RedPajama-3B/prepare.py
This script will download the weight from HuggingFace and prepare it for our finetuning. The prepared weights will be saved at:
/pretrained/RedPajama-3B/togethercomputer_RedPajama-INCITE-Chat-3B-v1
4. Prepare the training data. We provide an example script that downloads a small slice from OIG data. To download this sample dataset, please run:
bash data/OIG-chip2/prepare.sh
Then the sample dataset will be saved at /data/OIG-chip2/unified_chip2.jsonl.
If you have your own data, you can prepare them in the following format. Your dataset should be a jsonl file where each line is a JSON object that contains a "text" field. In the "text" field, you need to format the dialog as:
<human>: {PLACEHOLDER_FOR_HUMAN_REQUEST}\n<bot>: {PLACEHOLDER_FOR_BOT_RESPONSE}\n<human>: {ANOTHER_TURN}\n<bot>...<br>
Each line in the jsonl file is a training sample, and the entire jsonl file should look like:
{"text": "<human>: {REQUEST_1}\n<bot>: {RESPONSE_1}\n<human>: ..."}<br>{"text": "<human>: {REQUEST_2}\n<bot>: {RESPONSE_2}\n<human>: ..."}<br>
5. Start the training script. We provide an example training script at /training/finetune_RedPajama-INCITE-Chat-3B-v1.sh. Please configure the parameters (e.g., learning_rate, batch_size, dataset_path) according to your hardware configuration. Then to start training, simply run:
bash /training/finetune_RedPajama-INCITE-Chat-3B-v1.sh
6. Convert to HF format. The fine-tuned model will be saved to /model_ckpts/redpajama-incite-chat-3b-sample/checkpoint_{steps}. In order to use it for inference, you will need to convert it to the HuggingFace format. To do so, run the following script (as an example, please change the checkpoint path, n-stages and n-layer-per-stage according to the training script):
python tools/convert_to_hf_gptneox.py --config-name togethercomputer/RedPajama-INCITE-Chat-3B-v1 --ckpt-path model_ckpts/redpajama-incite-chat-3b-sample/checkpoint_10/ --save-path model_ckpts/hf --n-stages 4 --n-layer-per-stage 8
Then you are ready to go!
Please note the above finetuning takes around 60GB VRAM to fit everything in to GPU, and may take even more to fit training data. If you do not have such GPUs, we also provide the low-rank finetuning scripts that works with 14GB VRAM. Here's the steps to get started.
- Clone the OpenChatKit repo, install dependencies and prepare the dataset. These steps are the same as full fine-tuning.
- The sample low-rank finetuning script is at /training/lora/redpajama-incite-chat-3b.py, please modify this script to accommodate your own training data and preferred configuration.
- Then you can start low-rank finetuning by running this script.
- Once the finetuning is finished, the resulting low-rank adapter will be saved to /outputs, and you can do inference with the following script.
python training/lora/redpajama-incite-chat-3b_inference.py
Instruction-tuned model for few shot applications
We released three versions of RedPajama-INCITE-3B and 7B models: the base model, an instruction-tuned model, and a chat model. The instruction-tuned model is designed for few-shot prompts. On HELM, the 3B instruction version is only 1.2 point behind Llama-7B (which is not instruction tuned) and the 7B instruction version achieves higher few-shot performance than Llama-7B.
| Models | Type | HELM (Average score over 16 core scenarios) |
|---|---|---|
| RedPajama-INCITE-Instruct-3B-v1 | Instruction-tuned | 0.453 |
| Llama-7B | Base model | 0.465 |
| RedPajama-INCITE-Instruct-7B-v0.1 | Instruction-tuned | 0.499 |
Most real-world applications of LLMs leverage few-shot examples in their tasks. For example, Standd, a legal Al startup, helps lawyers generate insights about their legal work and business development from unstructured data. They use few-shot prompts with RedPajama 7B for a variety of tasks. As one example, they instruct RedPajama 7B to highlight important sentences as part of a text search platform in their product, shown in the sentence highlighting example below, along with other examples of few-shot prompts.
Sentence Highlighting
You are a sentence highlighter. You highlight sentences that can be used to answer a specific question. To highlight a sentence you return the full text of a sentence in a bulleted list. If none should be highlighted return None.
Question: Who is the cow?
Paragraph: My name is Stephen. I am a cow. My favorite drink is soda.
Highlights:
- My name is Stephen.
- I am a cow.
Question: Who is the duck?
Paragraph: Today was a weird day. The sun was hot and I am tired.
Highlights:
None
Question: What is the largest deer?
Paragraph: The moose (in North America) or elk (in Eurasia) (Alces alces) is a member of the New World deer subfamily and is the only species in the genus Alces. It is the largest and heaviest extant species in the deer family. Most adult male moose have distinctive broad, palmate ("open-hand shaped") antlers; most other members of the deer family have antlers with a dendritic ("twig-like") configuration. Moose typically inhabit boreal forests and temperate broadleaf and mixed forests of the Northern Hemisphere in temperate to subarctic climates. Hunting and other human activities have caused a reduction in the size of the moose's range over time. It has been reintroduced to some of its former habitats. Currently, most moose occur in Canada, Alaska, New England (with Maine having the most of the lower 48 states), New York State, Fennoscandia, the Baltic states, Poland, Kazakhstan, and Russia.
Highlights:
- The moose (in North America) or elk (in Eurasia) (Alces alces) is a member of the New World deer subfamily and is the only species in the genus Alces
- It is the largest and heaviest extant species in the deer family.
Question: What architecture is RedPajama based on?
Paragraph: RedPajama-INCITE-Base-3B-v1 is trained over the RedPajama v1 dataset, with the same architecture as the popular Pythia model suite. We chose to start with the Pythia architecture to understand the value of training with the much larger RedPajama dataset with respect to the current leading open-source dataset, the Pile. Training on Summit leveraged the DeeperSpeed codebase developed by EleutherAI. We are excited to see that at 800B tokens, RedPajama-Base-INCITE-3B has better few-shot performance (measured in HELM, as the average score over 16 core scenarios) and better zero-shot performance (measured in Eleuther's LM evaluation harness) compared with open models of similar size, including the well-regarded GPT-Neo and Pythia-2.8B (trained with 420B and 300B tokens, respectively, with the Pile). On HELM, it outperforms these models by 3-5 points. On a subset of tasks from lm-evaluation-harness, outperforms these open models by 2-7 points.
Highlights:
- RedPajama-INCITE-Base-3B-v1 is trained over the RedPajama v1 dataset, with the same architecture as the popular Pythia model suite.
- We chose to start with the Pythia architecture to understand the value of training with the much larger RedPajama dataset with respect to the current leading open-source dataset, the Pile.
- Training on Summit leveraged the DeeperSpeed codebase developed by EleutherAI.
Geographical Question Answering
Please answer the following question:
Question: What is the capital of Canada?
Answer: Ottawa
Question: What is the currency of Switzerland?
Answer: Swiss franc
Question: In which country is Wisconsin located?
Answer: United States
Sentiment Analysis
Label the tweets as either 'positive', 'negative', 'mixed', or 'neutral':
Tweet: I can say that there isn't anything I would change.
Label: positive
Tweet: I'm not sure about this.
Label: neutral
Tweet: I liked some parts but I didn't like other parts.
Label: mixed
Tweet: I think the background image could have been better.
Label: negative
Tweet: I really like it.
Label: positive
Thank You!
Last Friday we released the first collection of models in our RedPajama-INCITE family, including base models of the size 3B and 7B, along with instruction-tuned and chat versions, all with a permissive Apache v2 license. We are humbled by the excitement we received from the community, and are in the process of trying to improve both models.
Acknowledgements
The training of the first collection of RedPajama-INCITE models is performed on 3,072 V100 GPUs provided as part of the INCITE compute grant on Summit supercomputer at the Oak Ridge Leadership Computing Facility (OLCF). This grant was awarded to AAI CERC lab at Université de Montréal, LAION and EleutherAI in fall 2022 for their collaborative project on Scalable Foundation Models for Transferrable Generalist AI.
We are thankful to all the project team members helping to build the RedPajama dataset and supporting training, including Ontocord.ai, ETH DS3Lab, AAI CERC Lab at the Université de Montréal, Stanford Center for Research on Foundation Models (CRFM), Stanford Hazy Research research group, LAION and EleutherAI. We are grateful to Quentin Anthony (EleutherAI and INCITE project team) for porting DeeperSpeed and the GPT-NeoX training framework to Summit, and assisting with distributed training setup.
We are also appreciative to the work done by the growing open-source AI community that made this project possible. That includes:
- Meta AI — Their inspiring work on LLaMA shows a concrete path towards building strong language models, and it is the original source for our dataset replication.
- EleutherAI — This project is built on the backs of the great team at EleutherAI — including the source code they provided for training GPT-NeoX.
- INCITE project team — Their work on GPT-NeoX adaptation to Summit during early 2023 enabled distributed training that scaled efficiently to thousands of Summit GPUs, and ensured smooth training of the models.
- This research used resources of the Oak Ridge Leadership Computing Facility (OLCF), which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725. We are grateful for the invaluable support provided to us by the OLCF leadership and by the OLCF liaison for the INCITE project.