

00:00
/
00:00

Summary
Cursor is an AI-powered coding platform where in-editor agents must respond inside the editor feedback loop, making worst-case latency under concurrency a hard requirement. Cursor partnered with Together AI to deploy production inference on NVIDIA Blackwell (GB200 NVL72 / HGX B200), optimize the stack end-to-end, and stand up a repeatable path from new weights to a production-like test endpoint via quantization (TensorRT-LLM + NVFP4).
Cursor is an AI-powered coding platform with continuous background intelligence, built by a research team that trains agentic coding models and ships them into production. As developers type, Cursor maintains a live model of the code context — predicting edits, refactoring code, and managing context in real time.
Delivering that experience requires responses inside the editor's feedback loop. That constraint shifts the serving problem from batch-style to real-time, low-latency inference. Cursor partnered with Together AI, the AI Native Cloud, to build infrastructure for this loop — using the NVIDIA Blackwell architecture and tuning the inference stack to meet strict latency targets.
Why latency is different inside an editor
In-editor agents generate outputs while the developer is actively editing, so timing determines whether a suggestion lands in the same local context the model used to generate it. Once the developer moves to a different region of code, the output often no longer lines up with the state it was meant to support.
In Cursor, those agents debug issues, generate features, and execute refactors while the developer continues working. That workload requires predictable worst-case latency under concurrency, consistent context handling across overlapping requests, and stable operation under sustained load.
Engineering on NVIDIA Blackwell
Meeting the latency budget at scale led the teams to NVIDIA Blackwell GB200 NVL72 and NVIDIA HGX™ B200, with higher memory bandwidth and tensor throughput to support faster serving. Deploying production workloads early in the lifecycle meant driving reliability and optimization across the full stack — hardware, firmware, host software, and the serving layer.
- Frontier infrastructure with NVIDIA Blackwell: Together AI worked with Cursor to deliver and collaborate on NVIDIA Blackwell's early rollout. For Cursor, early hardware access is a product advantage and Together engineers worked on fast upgrades and replacements to deliver this new frontier infrastructure. These efforts delivered these new chips quickly and reliably for Cursor to use.
- Full throughput on ARM hosts: GB200 NVL72 pairs the GPUs with the NVIDIA Grace™ CPU on the ARM instruction set. Much of the high-performance inference ecosystem assumes x86 hosts. Porting the inference stack to ARM required kernel and host-level tuning for GB200 NVL72.
- Custom kernels for Blackwell Tensor Core: Blackwell introduces new Tensor Core instructions optimized for lower-precision formats. Together AI built kernels for Blackwell, targeting these instructions directly, capturing more of the hardware’s throughput.
- Efficient parallelism across NVIDIA GB200 NVL72: GB200 NVL72 connects 72 NVIDIA Blackwell GPUs in an all-to-all topology. Distributing a model across that domain adds communication and synchronization overhead between chips. Together designed parallelism meshes for GB200 NVL72, so coordination costs stayed bounded — and the compute gains carried through to inference.
Shortening the weights-to-production cycle
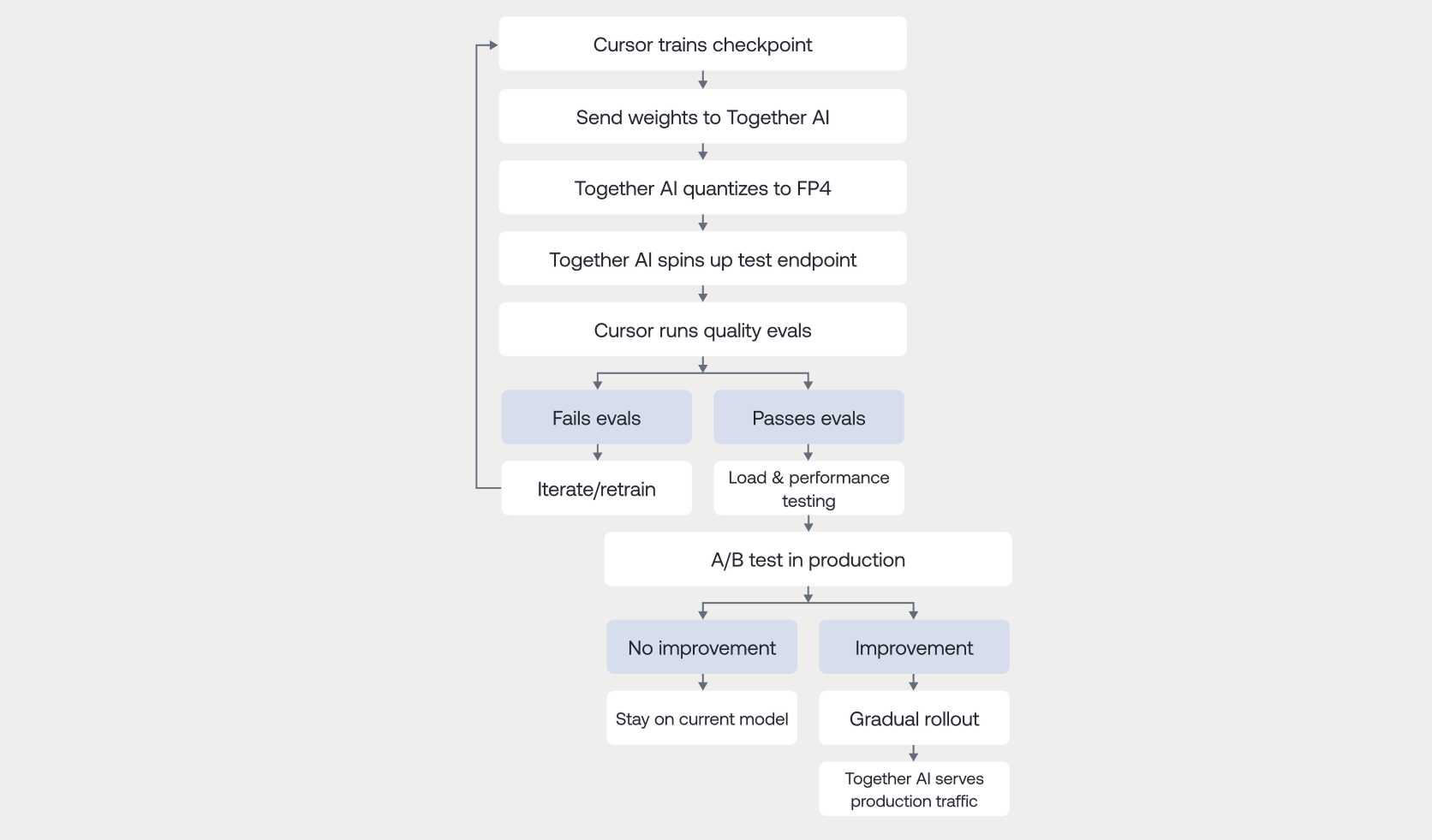
Cursor’s research team trains models internally — combining proprietary data with targeted optimization for coding workflows — and produces new candidate weights. The collaboration with Together AI established a repeatable path to move these weights to a production-like endpoint for immediate testing.
A key step in that path is quantization. Real-time serving runs on tight memory and compute budgets, and quantization reduces both by representing weights with fewer bits. In coding contexts, a quality drop can surface as subtle logic mistakes or syntax errors, so quantization has to preserve output quality while improving latency and cost.
Together AI implemented a quantization pipeline built around NVIDIA TensorRT LLM and NVFP4 on Blackwell — threading the needle between aggressive compression and the quality bar Cursor's coding models require. When Cursor produces a new candidate, Together quantizes it, validates it, and spins up a test endpoint within days. Cursor runs internal evaluation suites, then stages A/B testing under production traffic before completing a cutover. Cutovers are gated by validation and live-traffic checks.
What’s next — from latency to throughput
Cursor’s production deployment runs on NVIDIA Blackwell GPUs across multiple data centers. NVIDIA GB200 NVL72 handles inference, and the infrastructure supports model iteration as Cursor’s research team ships new weights.
With that latency path running in production, the focus shifts to throughput and utilization. Cursor and Together AI are building higher-throughput endpoints on the NVIDIA Blackwell platform to improve per-GPU economics as usage grows.
.svg)