Build on the AI Native Cloud
Engineered for AI natives, powered by cutting-edge research

































The Together AI Platform
Develop and scale AI native apps
Reliable at production scale
Built for scale, with customers going to trillions of tokens in a matter of hours without any depletion in experience.
Industry leading unit economics
Continuously optimizing across inference and training to keep improving performance, thus delivering better total cost of ownership.
Frontier AI systems research
Proven infra and research teams ensure that latest models, hardware and techniques are made available on day 1.
Full stack development
for AI Native apps
Model Library
Evaluate and build with open-source and specialized models for chat, images, videos, code, and more. Migrate from closed models with OpenAI-compatible APIs.
Inference
Reliably deploy models with unmatched price-performance at scale. Benefit from inference-focused innovations such as ATLAS speculator system and Turbo engine. Deploy on custom hardware of choice, such as GB200 and GB300.
Fine-Tuning
Fine-tune open-source models with your data to create task-specific, fast, and cost effective models that are 100% yours. Easily deploy into production through Together AI's highly performant inference stack.
Pre-Training
Securely and cost effectively train your own models from ground up, leveraging research breakthrough such as Together Kernel Collection (TKC) for reliable and fast training.
GPU Clusters
Scale globally with our fleet of data centers across the globe.
Industry leading AI research and open source contributions
Flash Attention
Mixture of Agents
Dragonfly
Red Pajama Datasets
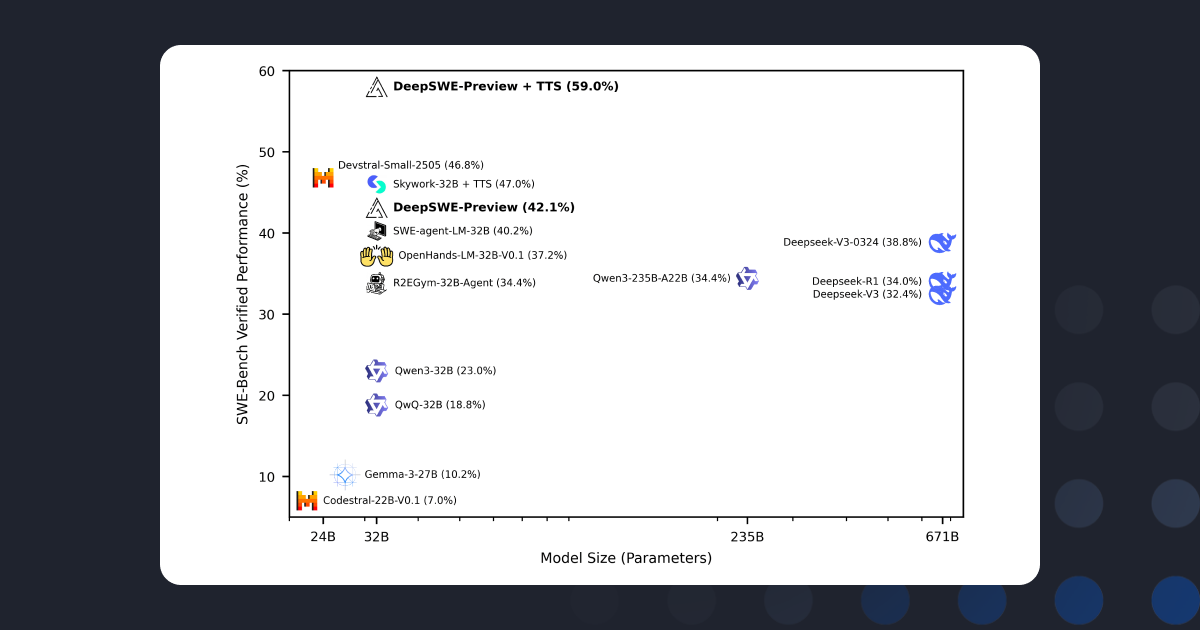
DeepCoder
Open Deep Research
Flash Decoding
Open Data Scientist Agent

Customer Stories
AI native companies are partnering with Together AI to build the next generation of apps






Proven results
Get to market faster and save costs with breakthrough innovations
Faster
Inference3.5X
Faster
Training2.3x
Lower
Cost20%
Network
Compression117x