Cogito V1 Preview Qwen 14B
Best-in-class open-source LLM trained with IDA for alignment, reasoning, and self-reflective, agentic applications.

About model
Cogito V1 Preview Qwen 14B is a hybrid reasoning model that generates text based on input, optimized for coding, STEM, and instruction following, with high multilingual and tool calling capabilities, suitable for commercial use.
To run this model, you first need to deploy it on a Dedicated Endpoint.
Model card
The Cogito LLMs are instruction tuned generative models (text in/text out). All models are released under an open license for commercial use.
- Cogito models are hybrid reasoning models. Each model can answer directly (standard LLM), or self-reflect before answering (like reasoning models).
- The LLMs are trained using Iterated Distillation and Amplification (IDA) - an scalable and efficient alignment strategy for superintelligence using iterative self-improvement.
- The models have been optimized for coding, STEM, instruction following and general helpfulness, and have significantly higher multilingual, coding and tool calling capabilities than size equivalent counterparts.
- In both standard and reasoning modes, Cogito v1-preview models outperform their size equivalent counterparts on common industry benchmarks.
- Each model is trained in over 30 languages and supports a context length of 128k.
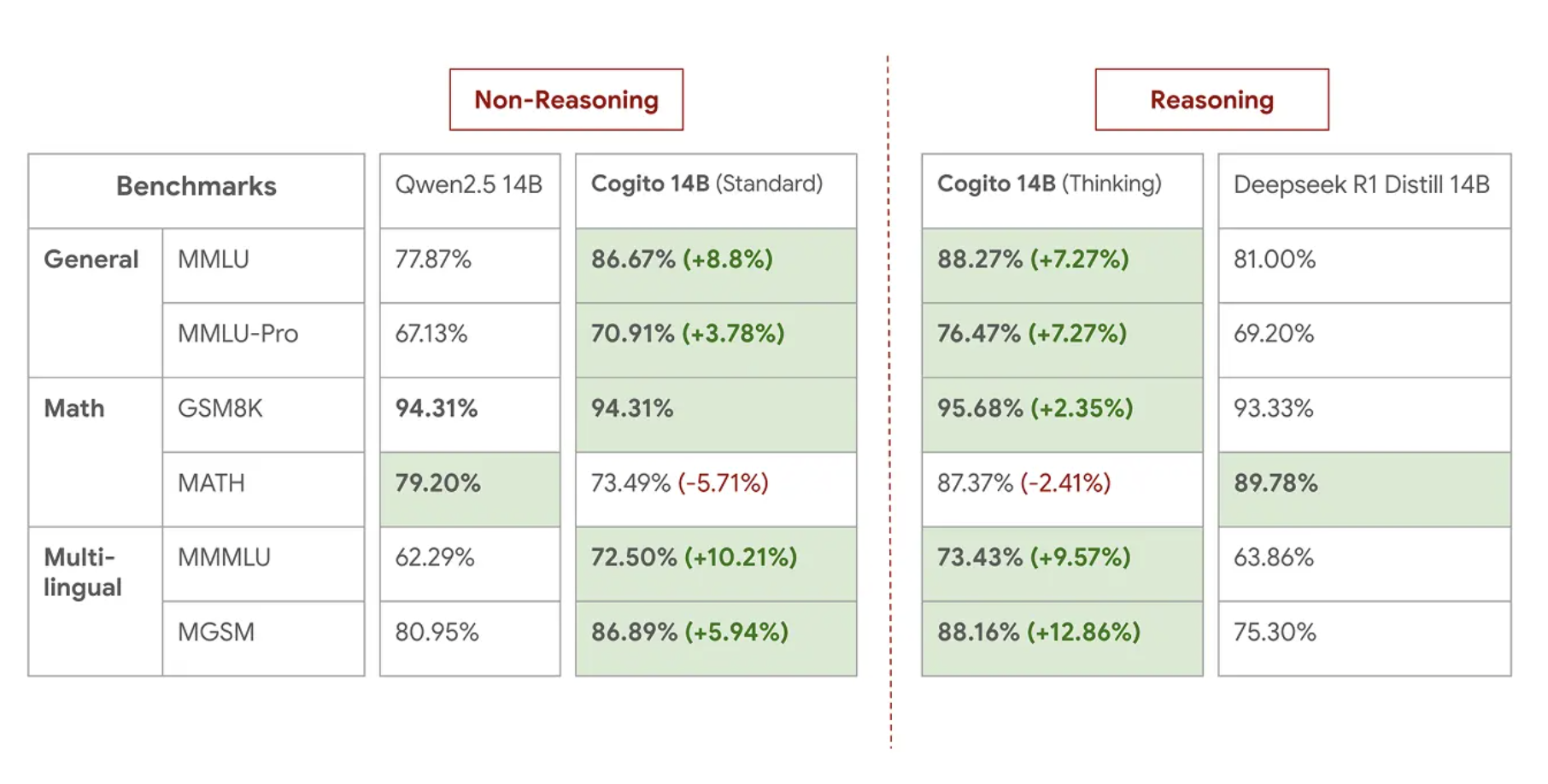
Evaluations
We compare our models against the state of the art size equivalent models in direct mode as well as the reasoning mode. For the direct mode, we compare against Llama / Qwen instruct counterparts. For reasoning, we use Deepseek's R1 distilled counterparts / Qwen's QwQ model.
Livebench Global Average:
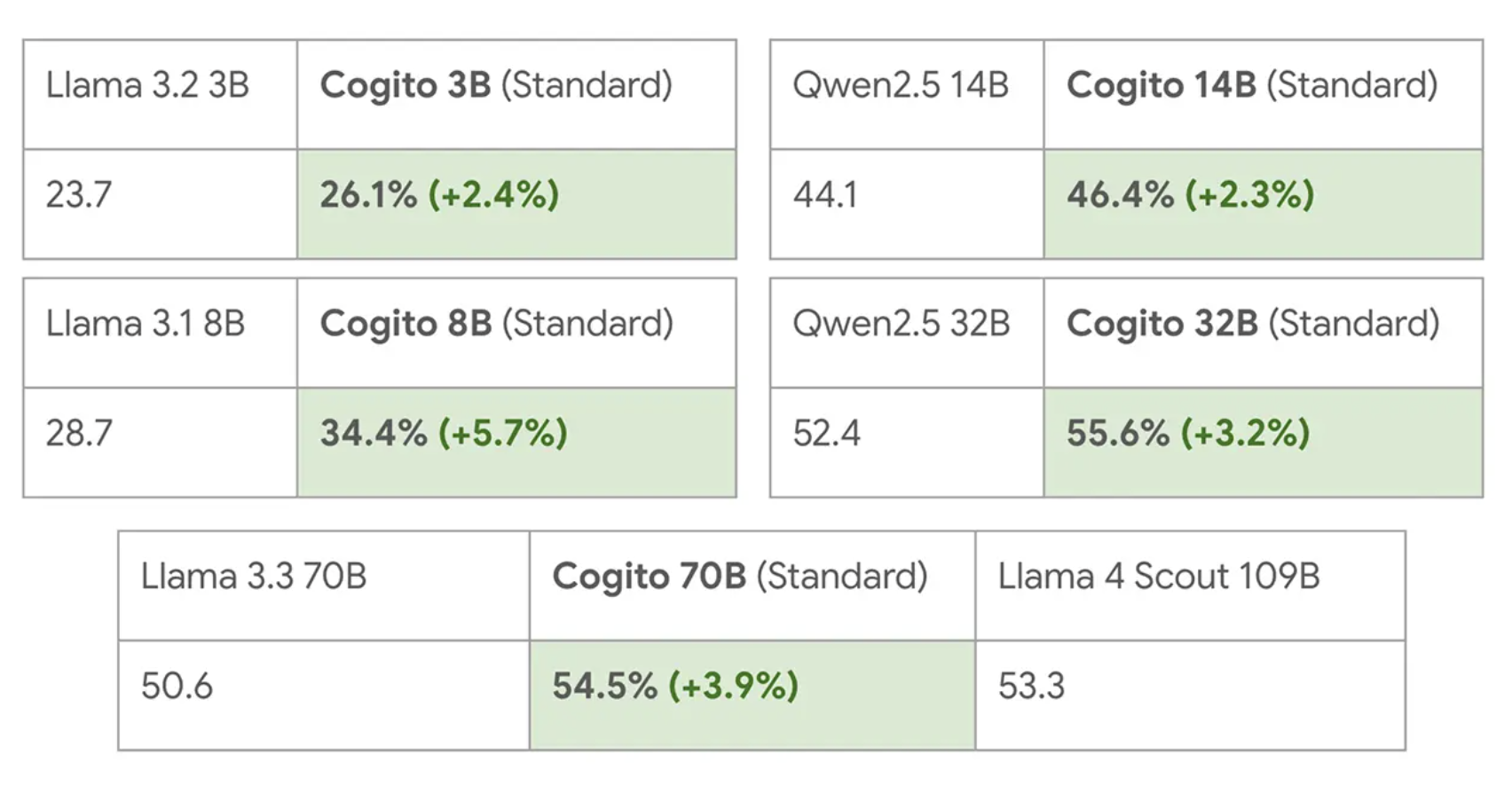
For detailed evaluations, please refer to the Blog Post.
- TypeChatCodeReasoning
- Main use casesChatSmall & Fast
- DeploymentOn-Demand DedicatedMonthly Reserved
- Parameters14.8B
- Context length128K
- Input modalitiesText
- Output modalitiesText
- ReleasedMarch 31, 2025
- External link
- CategoryChat