
Summary
Dedicated Container Inference lets teams deploy custom generative media models — like video generation, avatar synthesis, and image processing — with production-grade orchestration they don't have to build themselves. Bring your Docker container; Together handles autoscaling, queuing, traffic isolation, and monitoring. For teams already training on Together's GPU Cloud, going from training to production requires zero artifact transfers. Customers like Creatify and Hedra have seen 1.4x–2.6x inference speedups, driven by both the platform architecture and hands-on optimization from Together's research team.
Since Together’s inception, we have powered large-scale LLM inference. We understand this space deeply and have built a product to optimize for stateless requests, token-based latency, and highly optimized serving paths.
Dedicated Container Inference is built for a different class of workloads.
Over the last year, we have worked closely with teams deploying custom, non-LLM models into production. These go far beyond text-in, text-out APIs: video generation pipelines, avatar synthesis, large-scale image processing, and custom audio/media models with real business constraints.
What these teams consistently needed was not just GPUs or containers. They needed a way to run custom inference code in production without building their own job orchestration layer. Autoscaling, queuing, traffic isolation, retries, and monitoring all mattered, but none of them wanted to reimplement that stack in-house.
Dedicated Container Inference is our answer to that gap - bringing production-grade orchestration for custom models to the AI Native Cloud.
You bring your container and inference logic. We handle deployment, autoscaling, queuing, and monitoring at the job level, built specifically for GPU-intensive workloads.
How is this different?
Most inference platforms optimize around a single abstraction, either a stateless endpoint or a large batch job. That works until you have real-time and batch traffic, customer tiers, and sudden demand spikes at the same time.
Dedicated Container Inference is built around job orchestration for your container which enables:
- Multiple independent queues instead of a single FIFO stream
- Policy-driven traffic control rather than per-request priority
- Isolation between batch, real-time, and untrusted traffic
- Predictable behavior during spikes without over-provisioning
The difference though, is not just at inference time. Together is an end-to-end training-to-inference platform. Models trained on Together’s GPU Cloud can be deployed directly as Dedicated Containers without any artifact transfers or additional work.
For teams building custom models, this tight loop reduces operational overhead and makes it easier to move from training to production without introducing new failure modes.
Architecture at a glance
Dedicated Container Inference is built on a container-based deployment framework where jobs and queues are first-class concepts. Instead of forcing inference into a single request-response shape, we treat your container as the unit of execution and manage everything around it.
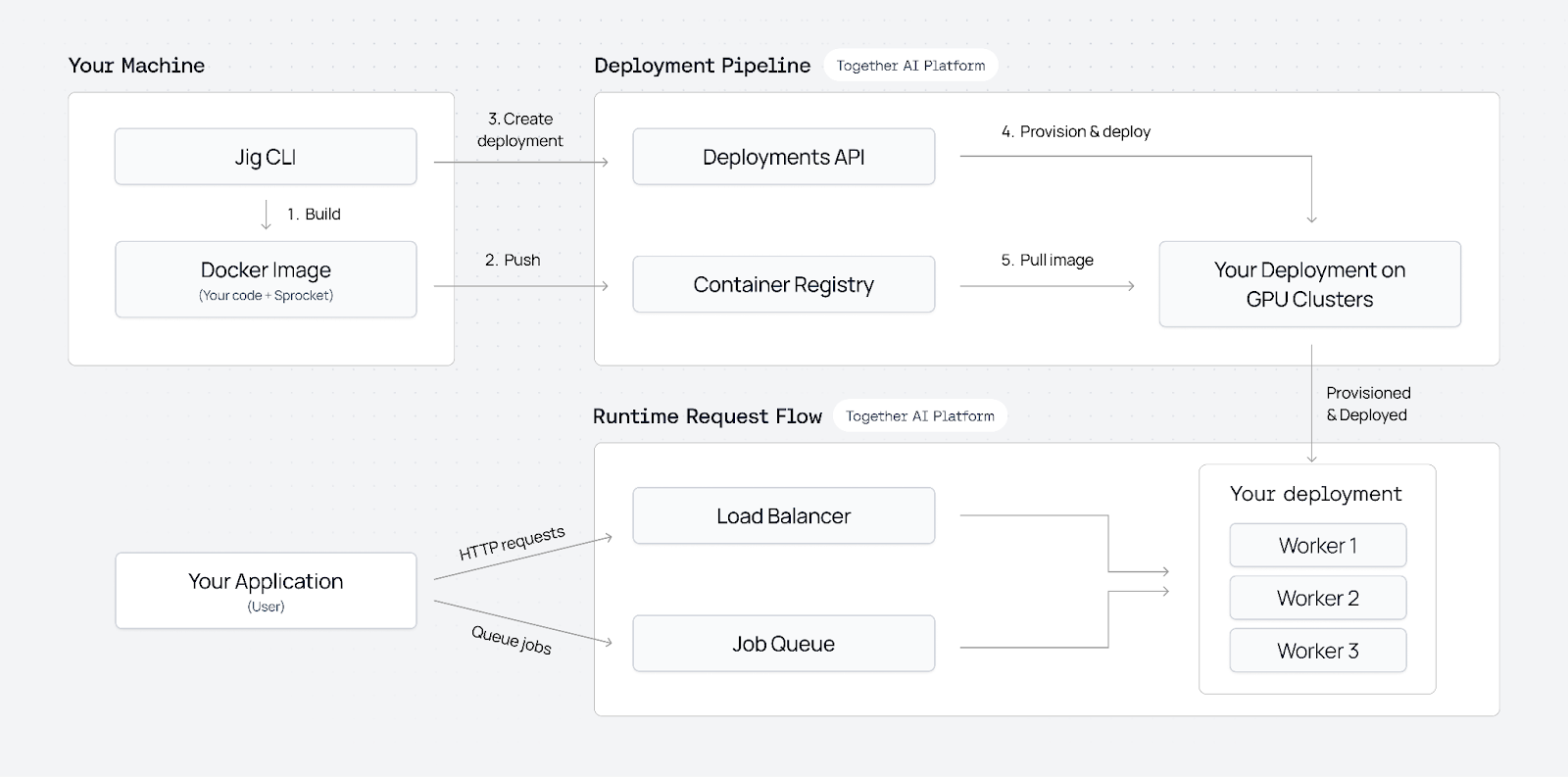
At a high level:
You package your model as a Docker container
The container includes your runtime, dependencies, and inference code. You decide how inference runs and what libraries you use.
We deploy and manage that container on GPU infrastructure
Together provisions GPUs, launches replicas, handles networking, health checks, and monitoring. You do not manage clusters or nodes directly. For large models that require multiple GPUs, we provide built-in support for distributed inference via torchrun.
Volume mounts for model weights
Rebuilding a 50GB container every time you update weights is slow and expensive. With volume mounts, you upload weights once and attach them at deploy time.
Inference runs as jobs
Requests are queued and executed by workers pulled from your deployment. This supports long-running jobs, batch workloads, and mixed traffic patterns.
Autoscaling driven by queue depth or metric of choice
Scale capacity up or down based on utilization, queue length, weighted queue priority, and job features like video length, or target wait time.
Traffic policies are explicit
You can define multiple queues and control priority by customer tier, use case, or SLA. Batch workloads do not interfere with real-time requests, and paid users are protected during spikes.
Observability is built in
Metrics, logs, and job state are available out of the box so you can monitor state.
Performance that boosts production workloads
For generative media workloads, small improvements in inference speed compound quickly into large cost and latency gains.
With Dedicated Container Inference, teams benefit from our research pipeline from automatic kernel optimizations to hands-on profiling and tuning for workload-specific performance improvements.
"Infrastructure costs can kill an AI company as they scale. Together's Dedicated Container Inference solved two critical problems for us: handling unpredictable viral traffic without over-provisioning, and taking our already-competitive model performance to the next level.
Their research team achieved significant lossless speedups that directly improved our unit economics—without sacrificing quality. They didn't just provide GPUs; they partnered with us to make our inference more efficient at scale. That level of technical partnership, combined with production-grade infrastructure, let us focus on building products instead of managing clusters."
— Ledell Wu, Co-Founder & Chief Research Scientist, Creatify
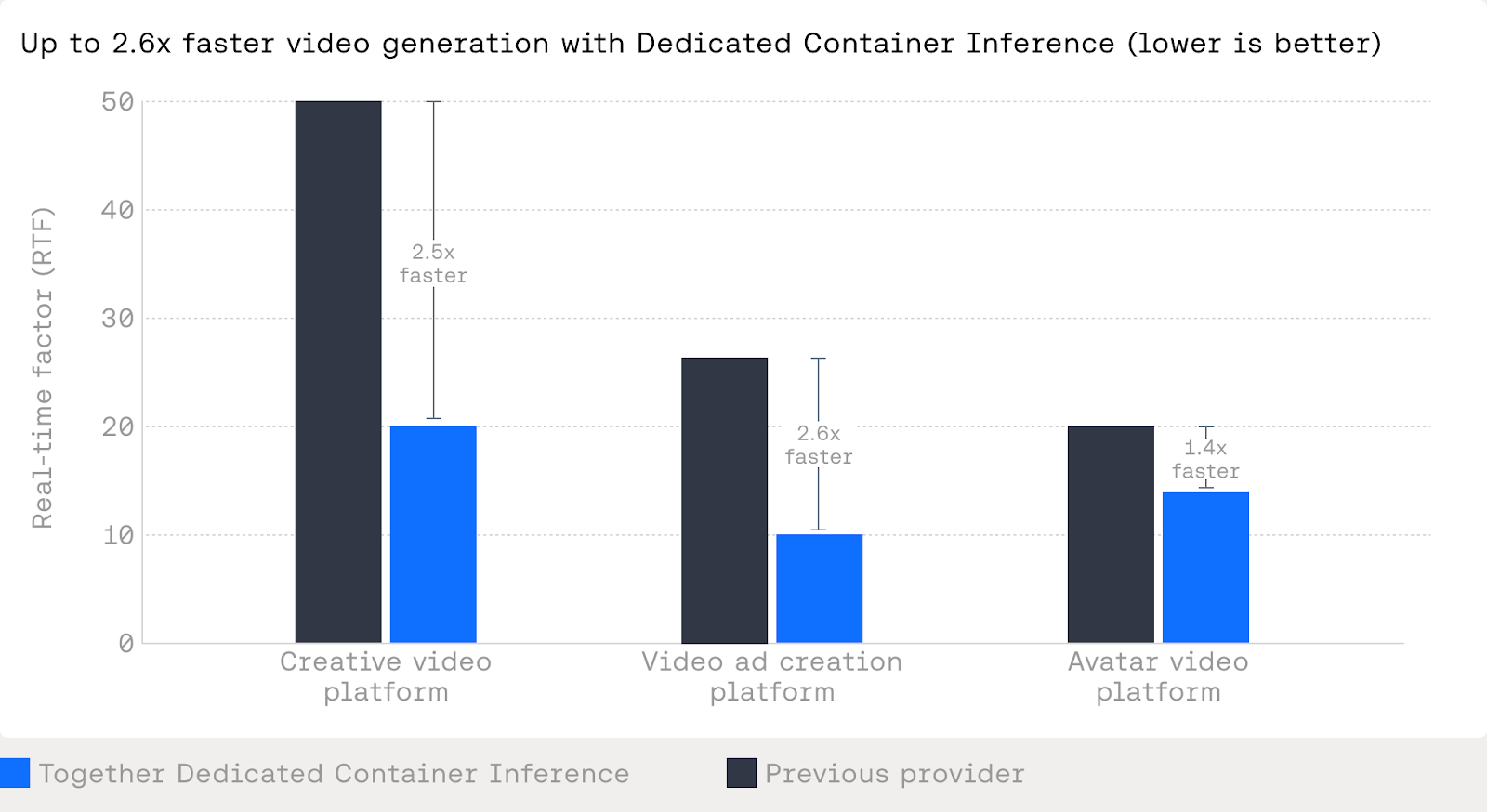
Across production deployments, we have seen:
- Large reductions in real-time factor for video generation models, moving from tens of seconds per second of output down to low double digits
- Meaningful speedups on avatar and video synthesis models through better batching, scheduling, and multi-GPU execution
- End-to-end improvements that turn previously uneconomical models into viable production services
These gains come from a combination of platform capabilities and hands-on optimization work. The result is lower latency, lower cost per output second, and more predictable scaling behavior under load.
“Together AI’s researchers partnered with us to optimize our model’s inference performance. It was hands-on work that made our model meaningfully faster.
Their infrastructure absorbs viral traffic without breaking a sweat. During major surges, Dedicated Container Inference scales seamlessly while maintaining performance.
And because we trained on Together’s Accelerated Compute, deploying to production was frictionless. One platform, zero artifact transfers, no deployment headaches.”
— Terrence Wang, Founding ML Engineer, Hedra
Getting started
If you are deploying a custom model and need production-grade orchestration, Dedicated Container Inference is designed for that use case. You keep full control over your container and inference logic. We manage deployment, scaling, queuing, and monitoring.