

Deploy Deepseek in production
Request access to high-capacity reserved GPU instances, optimized for Deepseek deployments at scale.
- ✔️ Industry-leading performance enables best unit economics.
- ✔️ Scale from 1 to 1,000+ GPUs on our global infrastructure.
- ✔️ Frontier research baked in, from the creators of FlashAttention and ATLAS.
- ✔️ Deployments are SOC 2 Type 2 compliant and meet HIPAA requirements.
We'll get back to you shortly!
AI Native companies deploy their models with Together AI







End-to-end platform for AI native apps
Fine-tuning and deploy <model> on performance-optimized GPU clusters
Inference
Inference
Reliably deploy models with unmatched price-performance at scale. Benefit from inference-focused innovations like the ATLAS speculator system and Together Inference Engine.
Deploy on hardware of choice, such as NVIDIA GB200 NVL72 and GB300 NVL72.
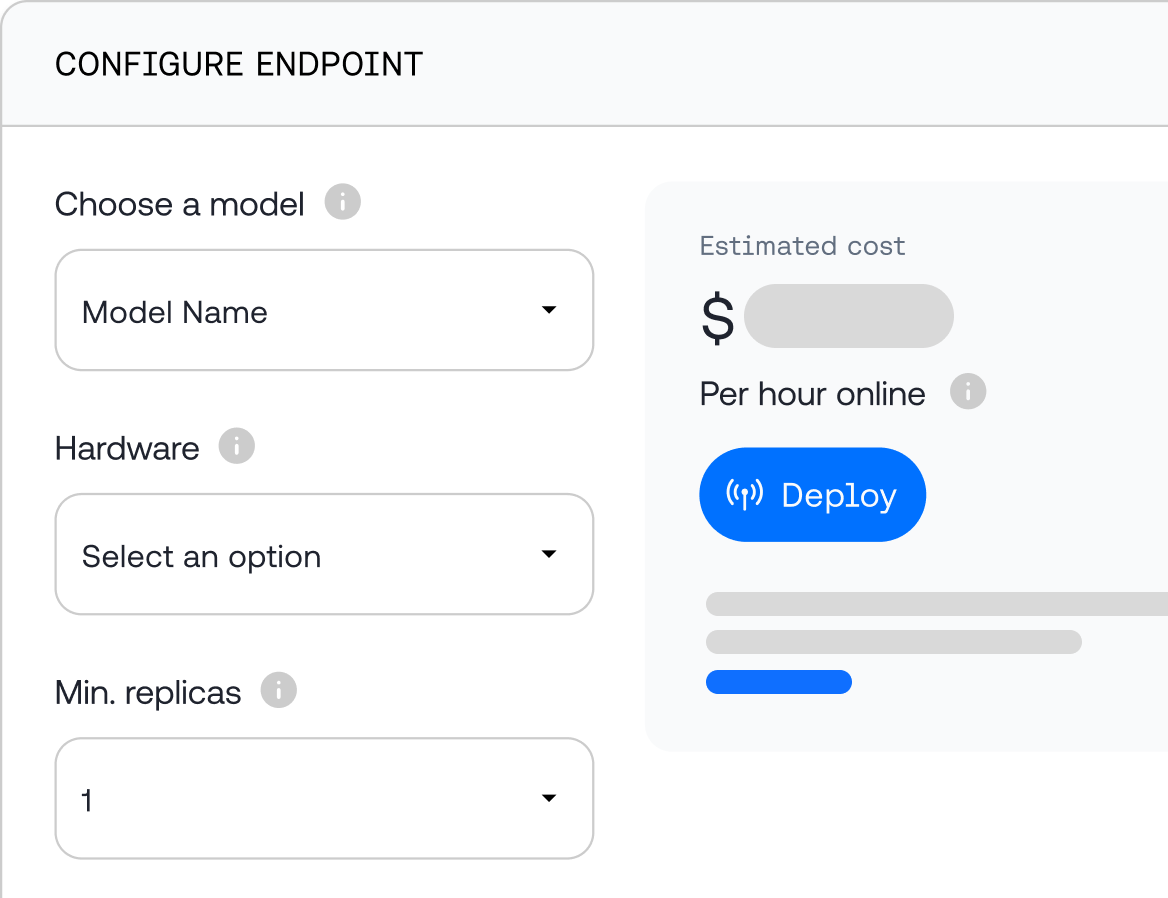
Fine-Tuning
Fine-Tuning
Fine-tune open-source models with your data to create task-specific, fast, and cost-effective models that are 100% yours.
Easily deploy into production through Together AI's highly performant inference stack.

Model Library
Model Library
Evaluate and build with open-source and specialized models for chat, images, videos, code, and more.
Migrate from closed models with OpenAI-compatible APIs.


.webp)

