
We release CoderForge-Preview - the largest open test-verified coding agent dataset. By leveraging it to fine-tune Qwen-3 32B, we boost SWE-Bench Verified performance 23.0% above the base model reaching 59.4%, ranking #1 among open-data models in the ≤32B parameter range.
As coding agents become increasingly capable, the research community faces a critical bottleneck: the lack of large-scale, high-quality open training data. While proprietary models continue to advance, open-weight alternatives have been held back by limited access to the long-context, test-verified trajectories needed for effective agent training.
We're releasing CoderForge-Preview, the largest open dataset of coding agent trajectories to date - 258k test-verified trajectories (155k pass | 103k fail) spanning 51K tasks across 1,655 repositories, and share our results of using it to train 32B and 4B models on it. By releasing CoderForge openly, we aim to accelerate progress across the entire open-source AI community and enable researchers everywhere to build, study, and improve upon our work. Fine-tuning Qwen-3 32B achieves 59.4% pass@1 on SWE-Bench Verified [8], ranking #1 among open-data models in the ≤32B parameter range.
We release the full trajectory dataset, as well as the evaluation trajectories for 32B.
.png)
CoderForge-Preview Data
We generate agent trajectories from three different task sources using Qwen3-Coder-480B and apply rejection sampling to filter out solutions that fail to pass the tests. This process yields 258K long-context trajectories (up to 128K tokens) across 51K tasks, from which we retain 155K high-quality, test-verified trajectories for SFT training.
Task sources
We draw tasks from three sources: R2E-Gym [5], SWE-Smith [6], and SWE-Rebench [7]:
| Source | Tasks | Unique Repos |
|---|---|---|
| R2E-Gym | 4,216 | 9 |
| SWE-Smith | 37,221 | 124 |
| SWE-Rebench | 9,764 | 1,577 |
| Total | 51,201 | 1,655 |
Setup
For the agent scaffold, we integrate OpenHands v0.52.1 scaffold [4] into the R2E-Gym [5] data generation framework. It includes four main tools: bash execution (execute_bash), file editing (str_replace_editor), log thinking (think), and task completion (finish). OpenHands is pre-installed in each Docker evaluation environment, enabling LLM agents to interact with isolated code repositories through a standardized action/observation interface. Each task is executed within an isolated Docker container, where the agent iteratively issues bash commands and file edits for up to 100 steps to generate a final patch.
We use Qwen3-Coder-480B as the main model for data generation. We use a temperature of 0.7, a top_p of 0.8, and 32,768 max new tokens. To increase the number of successful trajectories, we generate multiple per problem - 8 for R2E-Gym and SWE-Rebench, and 4 for SWE-Smith. We filter to keep only trajectories whose final patches pass all repository tests. To avoid evaluation leakage, we exclude any tasks that share the same (repository, base_commit) pair or problem statement with SWE-Bench Verified samples.
Comparison to other datasets
| Datasets | Teacher | Context Length | Size (Total) | Size (Filtered) |
|---|---|---|---|---|
| R2E-Gym/R2EGym-SFT-Trajectories | Claude Sonnet 3.5 | 20000 | 3,231 | 3,231 |
| SWE-bench/SWE-smith-trajectories | Claude Sonnet 3.7 | 32768 | 49,897 | 21,513 |
| allenai/SERA [10] | GLM-4.6 | 32768 | 25,224 | 25,224 |
| nex-agi/agent-sft (agentic_code) [11] | DeepSeek-V3.1-Nex-N1 | 128000 | 24,796 | 24,796 |
| nebius/SWE-rebench-openhands-trajectories [12] | Qwen3-Coder-480B | 128000 | 67,074 | 32,161 |
| CoderForge-Preview Data | Qwen3-Coder-480B | 128000 | 258,134 | 155,144 |
CoderForge-Preview Data stands out as the largest and best-performing coding-agent trajectory dataset among comparable releases. With 258,134 total and 155,144 successful trajectories at a 128K context length, it substantially exceeds prior datasets both in scale and long-context coverage.
Trajectory success by task source
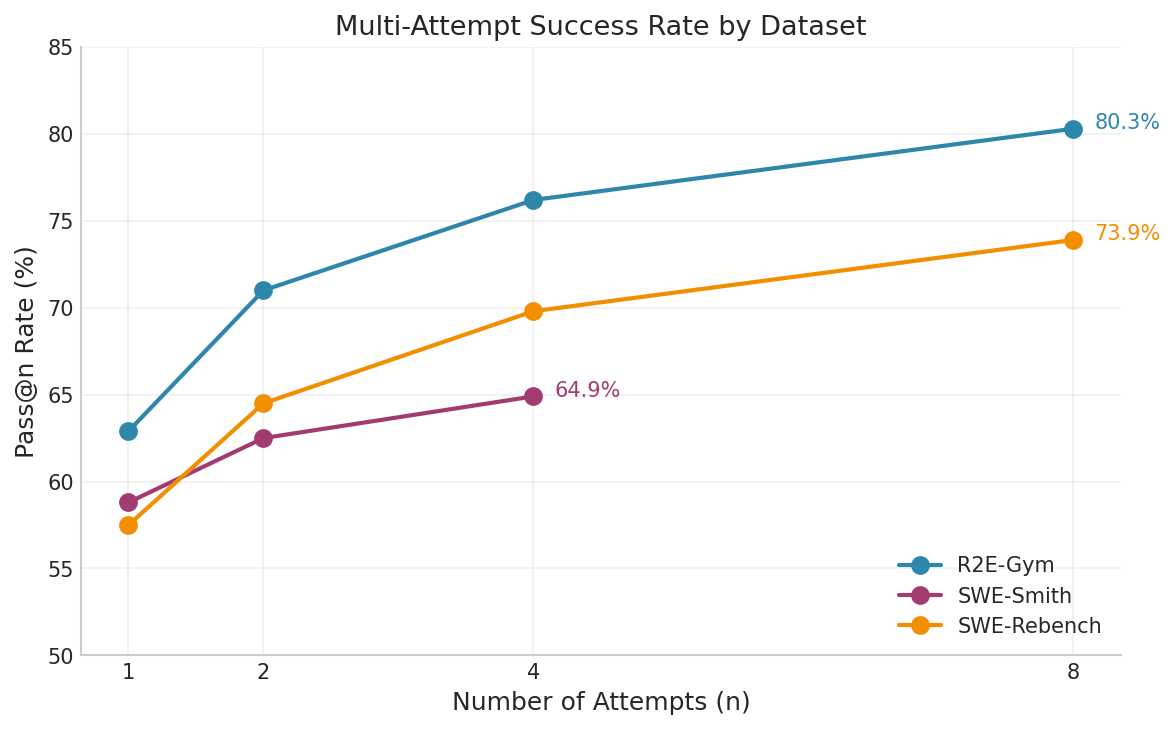
For each trajectory, we run the relevant tests provided with its task to check whether the model has solved it. For R2E-Gym tasks the solve-rate was consistently the highest, rising from 62.9% at Pass@1 to 80.3% at Pass@8. SWE-Rebench also benefits substantially from multi-attempt sampling, improving from 57.5% to 73.9% by Pass@8. SWE-Smith shows more modest gains, increasing from 58.8% at Pass@1 to 64.9% at Pass@4. Overall, the trend highlights the effectiveness of multi-sample generation in increasing the yield of successful trajectories, with diminishing but consistent returns as the number of attempts grows.
Final Task Source Distribution
We filter our generated trajectories based on whether they solved the task successfully, resulting in the task distribution shown below. For our SFT experiments, we only trained on the successful trajectories.
| Task Source | Trajectories Generated | Trajectories Generated (reward = 1.0) |
|---|---|---|
| R2E-Gym | 32,964 | 20,904 |
| SWE-Smith | 148,001 | 89,501 |
| SWE-Rebench | 77,169 | 44,739 |
| Total | 258,134 | 155,144 |
Trajectory Characteristics
Data Generation Cost
| Source | # Completions API | Prompt Tokens | Output Tokens | Avg Output Tokens | Cache Hit Rate |
|---|---|---|---|---|---|
| R2E-Gym | 2.18M | 59B | 404M | 185.4 | 96.64% |
| SWE-Smith | 8.47M | 238B | 1,544M | 182.4 | 90.15% |
| SWE-Rebench | 4.99M | 155B | 965M | 193.3 | 88.64% |
| Total | 15.64M | 452B | 2.91B | 186.3 | 90.48% |
Data generation at scale was enabled through efficient long-context inference and aggressive prompt caching. Across R2E-Gym, SWE-Smith, and SWE-Rebench, we issued 15.64M API completions, processing 452B prompt tokens and generating 2.91B output tokens, with an overall cache hit rate of ~90%. Using a pricing model of $0.50 per million prompt tokens, $0.25 per million cached tokens, and $2.00 per million output tokens, the total cost of generating this large-scale, long-context trajectory dataset was $130k.
Trajectory Analysis
| Source | Median Length | Avg Length | P99 Length | Total Training Tokens |
|---|---|---|---|---|
| R2E-Gym | 39,599 | 42,149 | 83,549 | 0.97B |
| SWE-Smith | 36,008 | 39,313 | 88,101 | 3.65B |
| SWE-Rebench | 41,996 | 45,236 | 99,391 | 2.08B |
| Total | 38,052 | 41,398 | 91,150 | 6.70B |
The table shows the length distribution of generated agent trajectories across data sources. Median trajectory lengths range from 36K–42K tokens, with average lengths around 41K tokens and P99 lengths approaching 100K tokens, highlighting the long-context nature of the data. The combined dataset comprises 6.70B total training tokens.
| Source | Avg Steps (Success) | Avg Steps (Failed) |
|---|---|---|
| R2E-Gym | 55.7 | 65.6 |
| SWE-Smith | 48.3 | 61.0 |
| SWE-Rebench | 56.2 | 72.0 |
We compare the average number of agent steps for successful versus failed trajectories across data sources. In all cases, failed trajectories require substantially more steps, 18–28% more on average than successful ones. By training exclusively on successful trajectories, we aim to push the model toward efficient task resolution and concise decision-making, rather than learning from extended unproductive sequences.
License filtering
To ensure the dataset can be used responsibly, we conducted a comprehensive license audit of every repository at the exact commit referenced by each task. We retrieved the LICENSE file from each repository at the specific commit SHA and identified it using scancode-toolkit, the industry-standard license detection engine used by the Linux Foundation and the SPDX project.
We retain only trajectories from repositories under permissive open-source licenses:
| License | SPDX Identifier |
|---|---|
| MIT License | MIT |
| BSD 3-Clause | BSD-3-Clause |
| Apache License 2.0 | Apache-2.0 |
| BSD License | BSD |
| BSD 2-Clause | BSD-2-Clause |
| Historical Permission Notice and Disclaimer | HPND |
| ISC License | ISC |
| PostgreSQL License | PostgreSQL |
| Python Software Foundation License | PSF-2.0 |
| Creative Commons Zero 1.0 | CC0-1.0 |
| MIT No Attribution | MIT-0 |
| MIT-CMU License | MIT-CMU |
| BSD 4-Clause | BSD-4-Clause |
| Dual: MIT and Apache-2.0 | MIT AND Apache-2.0 |
| Dual: Apache-2.0 and BSD-3-Clause | Apache-2.0 AND BSD-3-Clause |
| Dual: BSD-3-Clause and MIT | BSD-3-Clause AND MIT |
CoderForge-Preview training experiments
Training Setup
We choose the dense model Qwen3-32B [1] as the base model for fine-tuning.
To support efficient training with 128K-length sequences, we adopt sequence parallelism via Ulysses [2], partitioning the sequence dimension and using optimized all-to-all communication to compute attention. Furthermore, as the trajectory lengths are varied across the dataset, we use multi-packing to pack multiple shorter trajectories into the same training sequence while preventing cross-example attention contamination via boundary-aware masking [3].
We use token-level loss formulation that aggregates gradients across all tokens in the entire batch across FSDP & Sequence Parallelism GPUs. This means the contribution of each token to the overall loss is normalized with respect to the total token count in the batch, so that long and short sequences are weighted consistently.
Given $L_i$: mean cross-entropy loss for micro-batch $i$ on rank $r$, $n_i^{(r)}$: number of valid tokens in micro-batch $i$ on rank $r$, $N=\sum_{r}\sum_{i} n_i^{(r)}$: total valid tokens across all ranks and micro-batches, The normalized loss is computed as:
$$\mathcal{L} \;=\; \frac{\sum_{r}\sum_{i} L_i\, n_i^{(r)}}{\sum_{r}\sum_{i} n_i^{(r)}}$$
We train the Qwen3-32B model on 8 nodes (64 H100 GPUs) with FSDP2 (shard size = 8), Ulysses sequence parallelism (size = 8) on BF16, gradient checkpointing, and FlashAttention-2. To maximize training throughput, we use sequential packing to fully utilize the 128K context window, ensuring minimal padding waste across sequences of varying lengths. The detailed length analysis is shown as below:
| Metric | Value | Interpretation |
|---|---|---|
| Mean Length | 104,891 tokens | ~82% of 128K utilized |
| Median Length | 105,274 tokens | Symmetric distribution |
| Std Dev | 5,906 tokens | Low variance (~5.6% CV) |
| Min / Max | 77,501 / 123,975 | Good range coverage |
Chat template
We adopt Qwen Coder's chat template, which has XML-formatted tool calling that is better suited for LLMs. We also release the tokenized trajectories with loss masks in the trajectories-tokenized_qwencoder subset of the dataset on Huggingface.
Evaluation
Main Results
We evaluate our models on SWE-bench Verified, a curated subset of 500 real GitHub issues that tests end-to-end software engineering capabilities. Our best model achieves 59.4% pass@1 and 78.56% pass@16 at epoch 3.13, demonstrating strong single-attempt accuracy and excellent coverage with multiple samples. Our training data, CoderForge-Preview Data, combines trajectories from multiple sources to maximize diversity and coverage.
| Model | SWE-Bench-Verified (pass@1) | SWE-Bench-Verified (pass@16) |
|---|---|---|
| CoderForge-Preview-32B | 59.4% | 78.56% |
| CoderForge-Preview-4B | 43.0% | - |
Repetition Penalty
In early training, we noticed a lot of instances of the str_replace_editor tool failing due to the model repeating the string it wants to replace. We investigate whether a mild repetition penalty helps suppress degenerate loops without hurting precise code edits and put the results below:
.png)
Conclusion: For production deployment, we recommend using no repetition penalty with later-epoch checkpoints. However, for early-stopped models, a mild penalty can provide a useful regularization effect.
Scaled down Experiments
To test whether the dataset provides learning signal at smaller scale, we fine-tune Qwen3‑4B. The SWE-bench Verified results demonstrate clear learning progress across 5 epochs: the 4B model score improves to 43.0% (Epoch 5).
The repetition-penalty ablation shows a similar trend to the 32B setting: it helps early (epochs 1–3) but is not beneficial at the best-performing later checkpoint.
The peak performance gap between 4B (43.0%) and 32B (59.4%) confirms that model capacity matters for complex agentic tasks, yet the consistent improvement trajectory validates that our training data provides genuine signal at both scales.
.png)
Eval Traces Release
We release our evaluation traces of CoderForge-Preview-32B.
Our setup is as follows:
- Scaffold: OpenHands v0.52.1
- Sampling Parameters:
- temperature: 0.7
- top_p: 0.8
- max_tokens: 32768
- max_iterations: 100
.png)
Performance varies by repository. Excluding repositories with very small sample sizes (e.g., n<5), scikit‑learn has the highest resolved rate (84.4%), followed by matplotlib (64.7%) and xarray (63.6%). For Django (n=231; 46% of the benchmark), the model resolves 61.9% of instances. Some low rates (e.g., seaborn) are based on very small n and should be interpreted cautiously
Evaluation prompt template
For both data generation and evaluation, we adopt the OpenHands SWE-Bench template:
<uploaded_files>
/workspace/{{ workspace_dir_name }}
</uploaded_files>
I've uploaded a python code repository in the directory {{ workspace_dir_name }}. Consider the following issue description:
<issue_description>
{{ instance.problem_statement }}
</issue_description>
Can you help me implement the necessary changes to the repository so that the requirements specified in the <issue_description> are met?
I've already taken care of all changes to any of the test files described in the <issue_description>. This means you DON'T have to modify the testing logic or any of the tests in any way!
Also the development Python environment is already set up for you (i.e., all dependencies already installed), so you don't need to install other packages.
Your task is to make the minimal changes to non-test files in the /workspace/{{ workspace_dir_name }} directory to ensure the <issue_description> is satisfied.
Follow these phases to resolve the issue:
Phase 1. READING: read the problem and reword it in clearer terms
1.1 If there are code or config snippets. Express in words any best practices or conventions in them.
1.2 Hightlight message errors, method names, variables, file names, stack traces, and technical details.
1.3 Explain the problem in clear terms.
1.4 Enumerate the steps to reproduce the problem.
1.5 Hightlight any best practices to take into account when testing and fixing the issue
Phase 2. RUNNING: install and run the tests on the repository
2.1 Follow the readme
2.2 Install the environment and anything needed
2.2 Iterate and figure out how to run the tests
Phase 3. EXPLORATION: find the files that are related to the problem and possible solutions
3.1 Use `grep` to search for relevant methods, classes, keywords and error messages.
3.2 Identify all files related to the problem statement.
3.3 Propose the methods and files to fix the issue and explain why.
3.4 From the possible file locations, select the most likely location to fix the issue.
Phase 4. TEST CREATION: before implementing any fix, create a script to reproduce and verify the issue.
4.1 Look at existing test files in the repository to understand the test format/structure.
4.2 Create a minimal reproduction script that reproduces the located issue.
4.3 Run the reproduction script to confirm you are reproducing the issue.
4.4 Adjust the reproduction script as necessary.
Phase 5. FIX ANALYSIS: state clearly the problem and how to fix it
5.1 State clearly what the problem is.
5.2 State clearly where the problem is located.
5.3 State clearly how the test reproduces the issue.
5.4 State clearly the best practices to take into account in the fix.
5.5 State clearly how to fix the problem.
Phase 6. FIX IMPLEMENTATION: Edit the source code to implement your chosen solution.
6.1 Make minimal, focused changes to fix the issue.
Phase 7. VERIFICATION: Test your implementation thoroughly.
7.1 Run your reproduction script to verify the fix works.
7.2 Add edge cases to your test script to ensure comprehensive coverage.
7.3 Run existing tests related to the modified code to ensure you haven't broken anything.
8. FINAL REVIEW: Carefully re-read the problem description and compare your changes with the base commit {{ instance.base_commit }}.
8.1 Ensure you've fully addressed all requirements.
8.2 Run any tests in the repository related to:
8.2.1 The issue you are fixing
8.2.2 The files you modified
8.2.3 The functions you changed
8.3 If any tests fail, revise your implementation until all tests pass
Be thorough in your exploration, testing, and reasoning. It's fine if your thinking process is lengthy - quality and completeness are more important than brevity.
Limitations
Data:
- Adaptability to different scaffolds: we generate all data with a single scaffold and set of tools without permutations, so models trained with SFT on this data might perform worse when used with different scaffolds, tools, and prompt templates.
- Task Scope: given our data sources mostly focus on fixing bugs, models trained with SFT on this data may be less capable at tasks outside of that scope, such as feature implementation.
- User Interaction: most real coding agent use involves user intervention and collaboration with the agent in the form of user messages sent throughout the trajectory, not just at the beginning. Currently, this type of interaction is missing in open coding agent datasets, including ours. Thus, models trained with SFT on this data alone might not perform well in an interactive setting.
Training:
- Limited Model Scale Exploration: due to resource constraints, we only trained two sizes. Exploring larger models is likely to lead to further improvement.
- Minimal Hyperparameter Tuning: due to resource constraints, we used a fixed training configuration (learning rate 1e-5, cosine schedule, 128K context) without extensive hyperparameter search. Systematic tuning of learning rate, batch size, warmup steps, and loss weighting could potentially improve convergence and final performance.
Evaluation:
- For this release, we evaluated mainly using the standard SWE-Bench-Verified, which has sparked a lot of discussion recently on the quality of the signal. For our next iteration, we will be evaluating on more coding and terminal agent benchmarks.
Conclusion
In this work, we focus on large-scale agentic data generation, assembling 51K distinct tasks from the Open Source and generating long-horizon, multi-step supervised fine-tuning (SFT) trajectories. Our results demonstrate that a simple data generation pipeline combined with pure SFT training can yield substantial improvements in agentic coding performance.
Moving forward, we plan to further scale data generation, use different scaffolds, tools, permutations, and train larger models to better understand the upper bounds of scaling. In addition, we intend to follow the DeepSWE [9] training paradigm by applying agenetic reinforcement learning on top of our fine-tuned model to drive further performance gains.
BibTeX citation
@misc{CoderForge2026,
title = {CoderForge-Preview: SOTA Open Dataset for Training Efficient Agents},
author = {Ariyak, Alpay and Zhang, Junda and Wang, Junxiong and Zhu, Shang and Bianchi, Federico and Srivastava, Sanjana and Panda, Ashwinee and Bharti, Siddhant and Xu, Chenfeng and Heo, John and Wu, Xiaoxia Shirley and Zou, James and Liang, Percy and Song, Leon and Zhang, Ce and Athiwaratkun, Ben and Zhou, Zhongzhu and Wu, Qingyang},
year = {2026},
month = feb,
publisher = {Together AI Blog},
url = {https://www.together.ai/blog/coderforge-preview},
note = {Project core leads: Alpay Ariyak; Zhongzhu Zhou; Qingyang Wu}
}
References
[1] Qwen Team. "Qwen3-32B." Hugging Face Model Card (2025). https://huggingface.co/Qwen/Qwen3-32B
[2] Jacobs, Sam Ade, et al. "DeepSpeed Ulysses: System optimizations for enabling training of extreme long sequence transformer models." arXiv preprint arXiv:2309.14509 (2023).
[3] imoneoi. "Multipack Sampler: Padding-free distributed training of LLMs." GitHub repository (2024). https://github.com/imoneoi/multipack_sampler
[4] Wang, Xingyao, et al. "OpenHands: An open platform for AI software developers as generalist agents." arXiv preprint arXiv:2407.16741 (2024).
[5] Jain, Naman, et al. "R2E-Gym: Procedural environments and hybrid verifiers for scaling open-weights SWE agents." arXiv preprint arXiv:2504.07164 (2025).
[6] Yang, John, et al. "SWE-smith: Scaling data for software engineering agents." arXiv preprint arXiv:2504.21798 (2025).
[7] Badertdinov, Ibragim, et al. "SWE-rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents." arXiv preprint arXiv:2505.20411 (2025).
[8] Jimenez, Carlos E., et al. "SWE-bench: Can language models resolve real-world GitHub issues?" ICLR 2024, arXiv preprint arXiv:2310.06770 (2024).
[9] Luo, Michael, et al. "DeepSWE: Training a state-of-the-art coding agent from scratch by scaling RL." TogetherAI/Agentica Blog (2025).
[10] Shen, Ethan, et al. "SERA: Soft-Verified Efficient Repository Agents." arXiv preprint arXiv:2601.20789 (2026). https://arxiv.org/abs/2601.20789
[11] Nex-AGI Team. "Nex-N1: Agentic Models Trained via a Unified Ecosystem for Large-Scale Environment Construction." arXiv preprint arXiv:2512.04987 (2025). https://github.com/nex-agi/Nex-N1
[12] Trofimova, Maria, et al. "OpenHands Trajectories with Qwen3-Coder-480B-A35B-Instruct." Nebius Blog (2025). https://nebius.com/blog/posts/openhands-trajectories-with-qwen3-coder-480b