
Summary
Multi-tenant GPU clusters let AI-native companies share compute capacity across teams without sacrificing isolation or control. The right architecture pools GPUs at the infrastructure layer while giving each team dedicated nodes, storage, and self-serve scheduling, eliminating idle capacity waste without the politics of truly shared infrastructure. This guide covers the core design principles, common failure modes, and how platforms like Together AI implement multi-tenancy in practice.
Why multi-tenant GPU cluster design is a core infrastructure problem for AI-native companies
AI-native companies scale faster than their infrastructure strategies can keep up with. Every new team spins up new model experiments, training runs, and demands on shared compute. The result is a familiar situation for AI platform engineers: organizational demand for GPUs compounds, but they remain scarce and expensive.
The instinct is often to isolate, giving each team their own clusters and resources. But this approach doesn’t scale economically. Dedicated clusters sit idle overnight, on weekends, and when training runs finish ahead of schedule. You end up paying for capacity no one is using, while other teams queue for resources they can’t access.
The better architecture is shared, but shared in a way that teams experience as if clusters are their own. That’s the core design challenge of multi-tenancy at AI-native scale: pooled economics, without pooled chaos.
What is a multi-tenant GPU cluster?
A multi-tenant GPU cluster is a shared compute environment where multiple teams operate on the same underlying hardware while maintaining isolation that makes sense, including data access boundaries, credentials, storage volumes, and billing visibility.
Unlike a traditional shared cluster, multi-tenant clusters have a guarantee of isolation. In a well-designed multi-tenant cluster, one team’s training job can’t impact another’s. Hard quotas, reservation windows, and scheduling guardrails prevent overusing resources from becoming a cross-team problem — critical when you have teams across models, inference, and research all competing for the same GPUs.
What are the core requirements for multi-tenancy?
For multi-tenancy to work, there are three requirements teams should be meet simultaneously:
- Pooled capacity: A single negotiated GPU pool shared across teams eliminates idle-capacity waste. The unit economics only work when GPU utilization is aggregated across workloads — training runs, fine-tuning jobs, and inference — rather than isolated per team.
- Tenant isolation: Each team needs dedicated nodes, storage, separate credentials, and direct-to-tenant billing visibility. Shared infrastructure works best when every tenant feels like they’re operating their own cluster, with clear boundaries that no neighboring workload can cross.
- Self-serve access: Teams need to book capacity directly, see live availability, and spin up environments in minutes, not days.
How should you build your infra layers?
The cleanest pattern for AI-native infrastructure is two layers: shared infrastructure at the foundation, per-tenant infrastructure at the top.
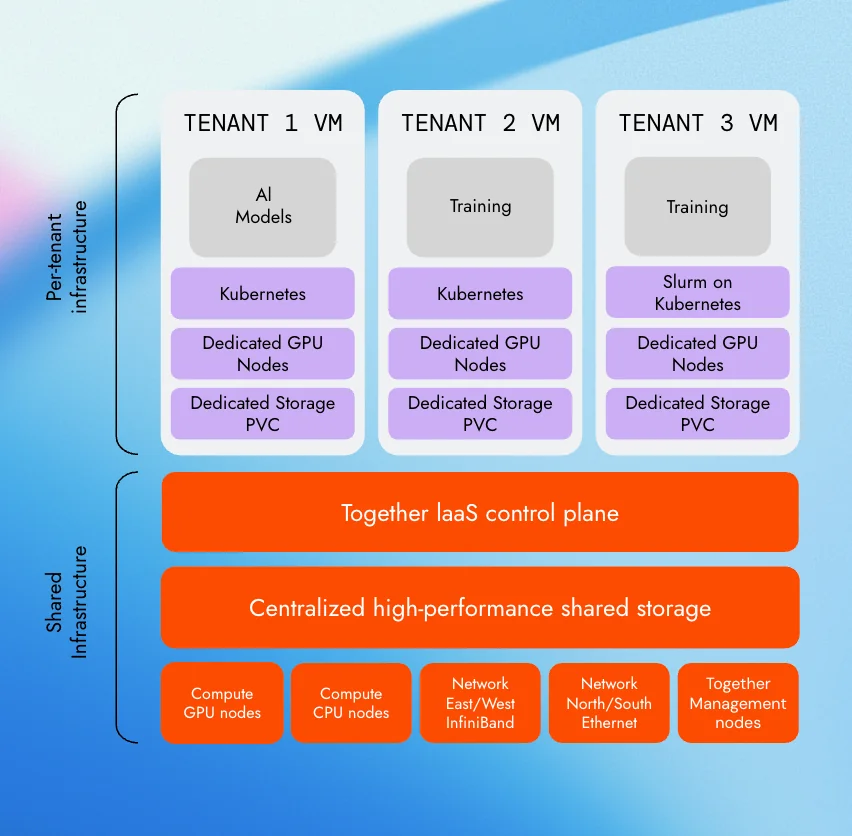
At the shared layer, a centralized control plane sits above high-performance shared storage and a common network fabric, typically InfiniBand for east/west intra-cluster traffic (essential for distributed training at scale., and Ethernet for north/south. GPU and CPU compute nodes are managed centrally, with Together AI’s IaaS control plane being a strong reference implementation of this pattern.
On top of this shared foundation, each team gets a fully isolated virtual environment: dedicated GPU nodes, dedicated storage PVCs, and their choice of orchestration layer — Kubernetes, Slurm, or other configurations depending on workload type. Teams running foundation model training, fine-tuning, or inference workloads each operate in their own clusters, with zero visibility into adjacent tenants.
Together AI’s multi-tenant clusters are a concrete implementation of this pattern, demonstrating what bare-metal performance with cloud-like flexibility looks like for AI-native teams in practices, billed directly per tenant based on actual usage.
How do you prevent one team from consuming all GPU capacity?
This is where quota-based allocation becomes essential in any AI-native environment. Administrators set guardrails per team, capping by GPU count, total spend, or reservation window length — enforced at the scheduler level, not just as a soft policy.
The scheduler should also handle advance booking with conflict prevention built in. Teams reserve clusters for a specific window (say, a month-long pre-training run or two-week fine-tuning spring), and the system prevents double booking. Live capacity availability surfaces in the UI so teams can see exactly what’s available before committing. Capacity-aware scheduling means predictable planning: no surprises or cross-team interference mid-run.
For teams that need burst beyond their quota, the right design supports overflow to on-demand public rates automatically. Together AI handles this without requiring admin approval, so production velocity isn’t throttled by infrastructure bureaucracy.
What configuration flexibility should a multi-tenant platform provide AI teams?
A common failure mode in shared infrastructure is opinionated defaults. Platforms that force a specific orchestration layer, driver version, or storage configuration create hidden tradeoffs — AI-native teams end up adapting their workflows to the platform rather than the other way around, which is exactly backwards.
The right pattern is an á la carte configuration at booking time: orchestration layer, CUDA driver version, shared memory size, and storage volume, all specified by the team based on their workloads requirements. No defaults or forced tradeoffs. A team running Llama fine-tuning on Slurm shouldn’t be forced into the same configuration as a team serving inference endpoints on Kubernetes.
Once provisioned, clusters should come with automated creation and tear-down, out-of-the-box observability via Grafana, and immediate SSH access.
How should GPU health and node repair work in multi-tenant environments?
Hardware failures in a shared cluster can have a ripple effect. They don’t just impact one training job, but can cascade across teams sharing the same physical layer. A robust health check and repair lifecycle is a must.
Best practice is automatic acceptance testing on every node before it’s handed off to a tenant’s cluster. Tests should include DCGM diagnostics, GPU burn tests, single- and multi-node NCCL tests, and NVBandwidth measurements across CPU-GPU latency and bandwidth dimensions.
Teams should also be able to trigger on-demand health checks directly from the UI at any point during a cluster’s lifecycle, not just at provisioning time. When issues are detected, the response should be tiered: software problems trigger a quick reprovision, hardware failures result in cluster migration. Throughout the repair lifecycle, tenants should have full visibility — no guessing whether a slow training run is a model issue or node issue.
Is multi-tenant GPU infrastructure right for your team?
Multi-tenant clusters deliver the most value when you have multiple AI teams with heterogeneous workloads — foundation model training, fine-tuning, inference, and research — all running concurrently. For AI-native organizations, the math strongly favors pooling.
The critical question isn’t whether to share infrastructure, but instead how well your AI platform enforces isolation. And when the process works seamlessly, you get data center unit economics without the performance compromises of public cloud, and the self-service velocity AI-native teams expect.
Start building on multi-tenant GPU infrastructure today
Together’s multi-tenant clusters are purpose-built for AI-native organizations that need shared GPU infrastructure without shared headaches. Pool your capacity, isolate your teams, and move at the speed your models demand.
Get started with Together AI →
FAQs
Can teams in a multi-tenant cluster see each other’s models, data, or training runs?
No, not in a correctly architected environment. Each tenant operates with dedicated GPU nodes, dedicated storage volumes, and separate credentials.
What happens when a team needs more capacity than their quota allows?
Well-designed platforms support automatic bursting to on-demand rates when teams exceed their pool allocation, no manual admin approval required. AI-native velocity shouldn’t be throttled by infrastructure bureaucracy at the edges of planned capacity.
What orchestration frameworks should a multi-tenant platform support for AI workloads?
At minimum: Kubernetes for inference and serving, and Slurm on Kubernetes for distributed training. AI-native teams often need both running simultaneously, so the platform needs to support mixed configurations