
Introduction
The amount of inference being performed with LLMs is growing dramatically across many different use cases, many of which utilize the ever-increasing context lengths supported by these models. Thus, maximizing the inference throughput of these models—including at long context—is becoming an increasingly important problem. Higher throughput enables lower price per token for consumers and lower carbon footprint per token. From a capability perspective, higher throughput at long context unlocks numerous applications such as information extraction from large sets of documents, synthetic data generation for LLM training/fine-tuning, extended user-assistant chats, and agentic workflows (which typically require numerous LLM calls per user request). These applications often involve processing very long input sequences (e.g., long documents or chat histories), requiring models to process thousands of tokens to deliver intelligent outputs. High throughput at long context is particularly technically challenging due to its huge memory requirements for the KV cache. Conventional wisdom (e.g., Chen et al., 2023; Li et al., 2024; Liu et al., 2024) is that in the high-throughput regime (i.e., large batch sizes), speculative decoding—which leverages underutilized GPU compute during memory-bound decoding—does not make sense, because decoding will be compute-bound and the GPUs will thus be fully utilized. Surprisingly, we show analytically and empirically that for large batch sizes, if the input sequences are long enough, decoding once again becomes memory-bound due to the large size of the KV cache. Building on this key observation, we demonstrate that speculative decoding can improve throughput and latency by up to 2x on 8 A100s in this large-batch, long-context setting.
In this blogpost, we first do a deep dive into the forward pass time of a single transformer layer during autoregressive decoding. We show that at large batch sizes, if the context length is large enough, decoding becomes memory-bound, dominated by the time to load the KV cache. After presenting the above analysis, we describe how we can use speculative decoding to increase throughput in the long-context and large batch regime. In particular, we propose two algorithmic innovations:
- MagicDec: Taking advantage of the fact that the bottleneck during decoding at large batch + long context is loading the KV cache, MagicDec uses a fixed context window in the draft model to make the draft model many times faster than the target model (since the draft KV cache size is fixed). Furthermore, because in this regime loading the target model parameters is no longer the bottleneck, we can afford to use a very large and powerful draft model—we can even use the full target model as the draft model, as long as it uses a fixed context window. Based on these insights, MagicDec combines ideas from TriForce and StreamingLLM—as the draft model, it uses a StreamingLLM draft model (using sliding window attention + attention sink) with staged speculative decoding for further speedups during drafting. Intriguingly, in this regime, we get larger speedups the higher the batch size!
- Adaptive Sequoia trees: Leveraging our observation that there is a sequence length threshold above which decoding becomes memory bound—and that it becomes increasingly memory bound for even longer sequence lengths—we propose choosing the amount of speculation as a function of the sequence length (longer sequence length -> more speculated tokens). We leverage the Sequoia algorithm (see our paper, blog) to determine the tree structure for the speculated tokens that maximizes the expected number of generated tokens.
We now jump into our deep dive of a single transformer layer.
Deep dive: When is decoding for a single transformer layer dominated by loading the KV cache?
Here, we analyze when the decoding forward pass time of a single transformer layer is dominated by loading the KV cache. We show that as the context length and batch size increase, most of the time is spent on loading the KV cache.
For this analysis, we split the operations during the forward pass into two types: operations involving model parameters, and operations involving the KV cache. For each type of operation, we compute the number of FLOPS as well as the amount of memory that must be communicated. We note that while the operations involving model parameters become compute-bound as the batch size increases (as their arithmetic intensity equals the batch size $b$), operations involving the KV cache are always memory-bound (as their arithmetic intensity is constant, because each sequence in the batch has its own KV cache). Because the memory taken by the KV cache grows linearly with both the batch size and the average sequence length, whereas the model parameter FLOPS are constant with respect to the sequence length, the forward pass time becomes dominated by the loading of the KV cache as the average sequence length increases.
Here, we will assume that we use a regular MLP, intermediate size=4*d, d=model dim, b=batch size, and n=current prefix length. We assume we are using GQA, where "g" corresponds to the ratio of query heads to key/value heads.
| Model Params | KV cache | |
|---|---|---|
| Memory (bytes) | 2 * (10d2 + 2d2 / g) | 2 * 2bnd / g |
| Compute (FLOPs) | 2b * (10d2 + 2d2/g) | 2 * 2bnd |
| Arithmetic intensity | b | g |
Table 1: Memory and compute of a single transformer layer during decoding, split up in terms of operations with model parameters (MLP params, W_{Q,K,V,O}) and with the KV cache. `g` corresponds to the memory reduction factor from GQA (g = num_attention_heads / num_key_value_heads).
From this table, it is easy to see that for large enough sequence length n (and batch size b), the time to load the KV cache will far exceed the operations involving the model parameters, regardless of whether those operations are compute bound or memory-bound.
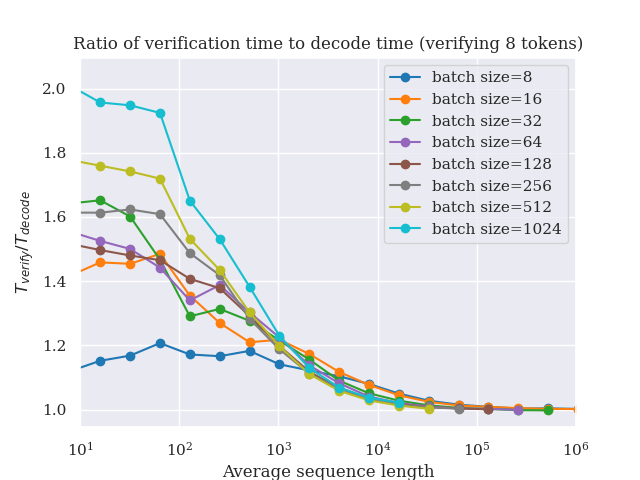
In Figure 1 we empirically validate that loading the KV cache dominates the forward pass time for a transformer layer, as the sequence length and batch size increase. In particular, we plot the fraction of decode time taken by the operations over the KV cache for a transformer layer with a model dimension of 1024. As you can see, as the sequence length increases, the empirical fraction approaches 1, and it approaches 1 more quickly for larger batch size. This result was quite exciting and surprising to us—counterintuitively, in the long-context regime, a larger batch size results in decoding being more memory bound, instead of the other way around. The communities focus on short/medium context may have resulted in this fact being overlooked until now.

Enter speculative decoding
Based on the above observations, we propose using speculative decoding to improve LLM throughput and latency during decoding in the large batch + long context regime. Intuitively, because the KV cache operations are memory-bound and dominate the compute time in this regime, there is idle compute that we can utilize with speculative decoding. More specifically, we can show that the verification time ($T_{verify}$) during speculative decoding (when verifying $L$ tokens) will be quite similar to the regular decode time ($T_{decode}$), because the operations involving the KV cache will remain memory bound as $L$ increases (and therefore will take the same amount of time). Although the time for the operations involving the model parameters can increase by a factor of $L$, the total time will not increase very much in the cases where the KV cache loading dominated the decode time. Therefore, as long as our time to speculate these $L$ tokens ($T_{draft}$) is relatively fast, and we have a high enough acceptance rate, we will attain speedups from using speculative decoding (see speedup equation below).
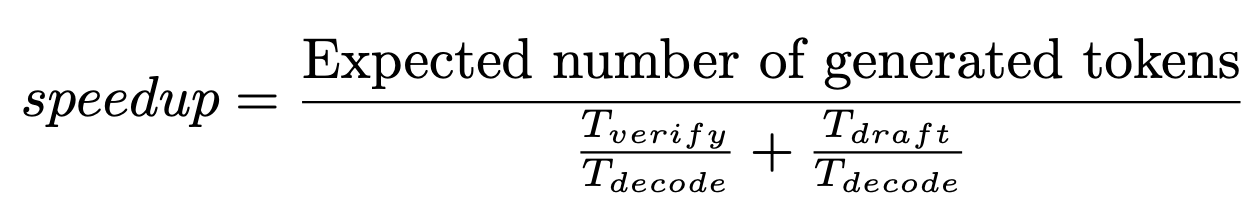
In Figure 2, we show that for large sequence lengths, $T_{verify}$/$T_{decode}$ approaches 1, which implies that speculative decoding can give meaningful speedups.
We will now detail our two algorithmic innovations—MagicDec and adaptive Sequoia trees—related to performing speculative decoding in this high-throughput regime.
MagicDec
A low draft-to-verify cost ratio is ideal for speculative decoding. In the low-latency regime in which speculative decoding is normally applied (i.e., low batch size), the bottleneck during decoding is the time to load the target model parameters—therefore, using a small draft model is generally the key to attaining a low draft to verify ratio. However, in the high throughput regime we are interested in here, the bottleneck is loading the target model KV cache. This shift in bottlenecks opens up the possibility of using better strategies for drafting. In particular, we can afford to use a larger and more powerful target model as long as its KV cache is kept small. Thus, we propose using self-speculation, where the target model is used as the draft model, but with limited context size. More specifically, we use StreamingLLM, which uses sliding window attention combined with an "attention sink" (allows attending over the first token) to limit the size of the KV cache. While the draft cost increases with larger batch sizes mainly due to increased computation time, the verification cost rises even more due to the greater KV loading time. This makes the draft-to-target cost ratio decrease with increasing batch size (see Figure 3), surprisingly making speculative decoding more effective for larger batch sizes. To further speed up the drafting process, we can use staged speculative decoding, similarly to TriForce.
.png)
In Table 2, we demonstrate results attaining speedups of up to 2x for LLaMA-2-7B-32K and 1.84x for LLaMA-3.1-8B on 8 A100 GPUs.
| Target | Draft | Prefill | Batch-size | Optimal spec len | Speedup |
|---|---|---|---|---|---|
| Llama2-7b-32k | TinyLlama-1.1B | 8000 | 32 | 3 | 1.29 |
| TinyLlama-1.1B | 8000 | 64 | 3 | 1.57 | |
| TinyLlama-1.1B | 8000 | 128 | 4 | 1.66 | |
| TinyLlama-1.1B | 32000 | 32 | 4 | 1.91 | |
| Llama2-7b-32k | Self-spec | 8000 | 32 | 3 | 1.18 |
| Self-spec | 8000 | 64 | 3 | 1.48 | |
| Self-spec | 8000 | 128 | 4 | 1.63 | |
| Self-spec | 32000 | 32 | 4 | 2.00 | |
| Llama3.1-8b | Self-spec | 32000 | 32 | 3 | 1.22 |
| Self-spec | 32000 | 64 | 3 | 1.38 | |
| Self-spec | 32000 | 128 | 4 | 1.47 | |
| Self-spec | 100000 | 32 | 5 | 1.84 |
Table 2: End-to-end Speculative Decoding Speedups for Various Target-Draft pairs on 8xA100s.
For more details about this work, and additional results, please refer to our paper.
Adaptive Sequoia trees
When we do speculative decoding with a tree of size L, we multiply the total number of flops by L+1 (because the new token generated by the target model, as well as the L speculated tokens, need to be processed by the target model), but keep the amount of memory that needs to be transported constant. Therefore, the flops/memory ratio R is simply multiplied by (L+1). Based on this observation, one simple approach would be to use the equation for R to find the largest value of L for which verification remains memory-bound, for each context-length. However, this approach is a bit coarse, as it ignores the cost of drafting the tree, as well as the marginal gain of increasing the size of the tree.
Therefore, we propose to refine the above approach by explicitly searching for the tree size which maximizes a speedup equation, for each context length. Similar to section 3.3.1 of the Sequoia paper, we can express speedup as follows (let b=batch size, n=sequence length, L=tree size, D=tree depth, G(L,D) = expected number of generated tokens, and T_model=forward pass time):
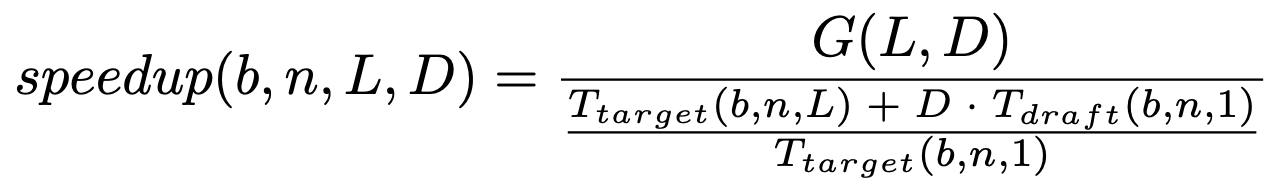
For $G(L, D)$, we can find the maximal expected number of generated tokens for a Sequoia tree of size $L$ and depth $D$. For $T_{model}(b, n, L)$, we can just measure forward pass times for the target/draft models for many combinations of $b$, $n$, $L$, and perhaps fit these results with a parametric function.
Please be on the lookout for our forthcoming paper, which combines adaptive Sequoia trees with a highly-optimized pipeline parallel FP8 system, designed to maximize throughput.
Conclusion and Future Work
This work reassesses the trade-off between throughput and latency in long-context scenarios. We demonstrate that speculative decoding can enhance throughput, reduce latency, and maintain accuracy. Our theoretical and empirical analysis reveals that as the sequence length and batch size increase, bottlenecks shift from being compute-bound to memory-bound. This shift enables effective use of speculative decoding for longer sequences, even with large batch sizes, achieving up to 2x speedup for LLaMA-2-7B-32K and 1.84x for LLaMA-3.1-8B on 8 A100 GPUs. These results highlight the importance of integrating speculative decoding into throughput optimization systems as long-context workloads become more prevalent.