

Summary
Speculative decoding goes stale in production — draft models can drift and offline retraining can't always keep pace.
Aurora fixes this. It's an open-source, RL-based framework that learns directly from live inference traces and continuously updates the speculator without interrupting serving.
Key results:
→ Real-time adaptation across shifting traffic domains
→ 1.25x additional speedup over a well-trained static speculator
The headline finding: online training from scratch can outperform a carefully pretrained static baseline.
Running large language models in production is a constant tradeoff between performance and cost. Speculative decoding is the standard lever: in principle, it speeds up inference. In practice, it often under-delivers—draft models go stale, acceptance rates drift, and offline retraining is too slow and too expensive to keep pace with live traffic. What if your system could learn continuously, on the fly, from the very requests it's serving?
Last year, we introduced ATLAS — our first step toward an adaptive speculator. That work laid the foundation, but the goal was always a fully autonomous system that closes the loop between serving and training.
Today, we're releasing Aurora, an open-source, RL-based framework that learns from live inference traces and updates the speculator asynchronously—turning speculative decoding from a static, one-time setup into a dynamic, self-improving flywheel. This unified design unlocks capabilities that are difficult to achieve in standard pipelines, including: (1) direct mitigation of distribution mismatch, achieving a 1.25x improvement over a strong offline baseline; (2) reduced infrastructure cost by eliminating large-scale activation-collection pipelines; (3) an algorithm-agnostic framework compatible with future speculator designs; and (4) support for diverse, heterogeneous user demands.
Across experiments, Aurora achieves an additional 1.25x speedup over a well-trained but static speculator on widely used models (e.g., Qwen3 and Llama3).
The code to reproduce the paper’s results is open-sourced, and we welcome contributions from the community.
End-to-end throughput under varying batch sizes
MiniMax M2.5 (FP8, lookahead 5):
Qwen3-Coder-Next-FP8 (lookahead 5):
1. Why the standard train-then-serve pipeline breaks down
Offline speculative training is convenient organizationally, but it introduces several practical issues in production that limit its effectiveness. The traditional pipeline is a one-way street — leading to stale models and a disconnect from real-world performance.
Traditional speculative decoding follows a linear, static flow that degrades over time. Aurora introduces a circular, continuously adaptive approach.
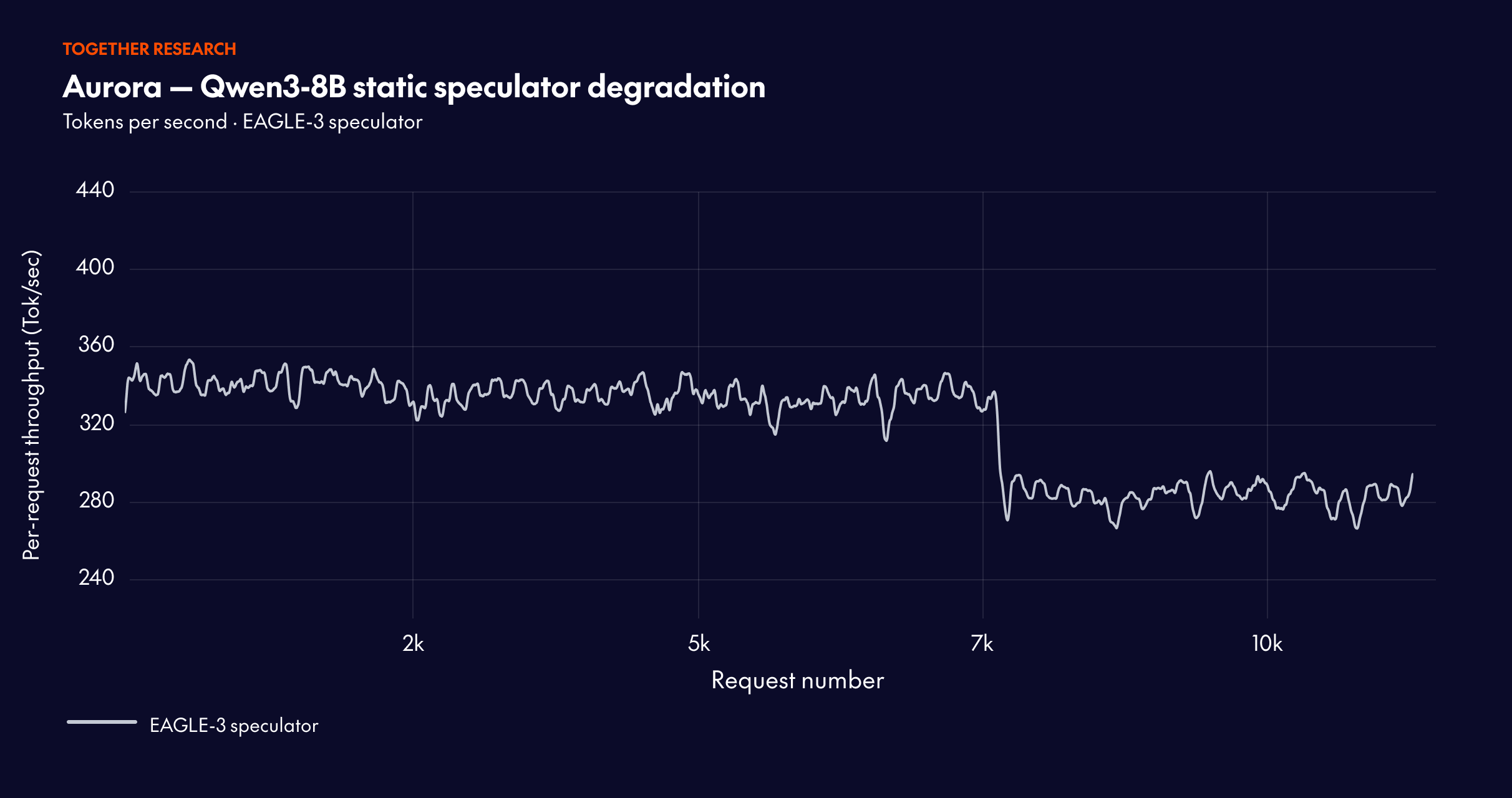
The verifier moves, but the drafter lags. Production target models change — for quality, safety, cost, or hardware migration. The speculator often updates much more slowly, so it becomes stale and speculative performance degrades over time.
Offline distillation pipelines are expensive. Activation collection and replay pipelines for drafter training can be extremely costly to store and operate at scale. At production scale, the storage footprint can reach petabyte-level magnitude, with high cost in memory, bandwidth, and operational complexity. Aurora reduces this burden by learning directly from live serving traces.
Acceptance rate is not the same as real speedup. Offline training can optimize acceptance in a lab setting, but production speedup depends on the actual serving stack: kernels, numeric precision (FP8/FP4), batching, scheduling, and hardware behavior. The best draft model offline may not be the best model online. In practice, most teams train multiple drafters but end up selecting only one — Aurora enables a direct speedup comparison because it operates online.
These gaps suggest that speculative decoding should not be treated merely as a modeling problem ("train a better drafter"), but as a joint learning-and-serving problem.
2. The core idea: A serve-to-train flywheel powered by RL
Aurora turns speculative decoding into a serve-to-train flywheel. Rather than treating the speculator as a static artifact, it learns continuously from every request it serves.

The system is built around two decoupled components. The Inference Server runs a speculative decoding engine (based on SGLang or vLLM) with a target model and a draft model. For each request, the draft model proposes a sequence of tokens, which are then verified in parallel by the target model. The results of both accepted and rejected tokens — along with hidden states for EAGLE-style training — are streamed to a distributed data buffer. The Training Server runs asynchronously: it fetches batches of training data from the buffer, performs gradient updates on a copy of the draft model, and periodically hot-swaps improved weights back to the inference server without service interruption.
This design is built around two production realities. First, serving efficiency is the real objective — latency, throughput, and cost/token under SLOs. Second, synchronization must be lazy and non-disruptive — frequent weight pushes can cause cache invalidation and latency jitter. To make this design work reliably, we re-formulate the online speculative training as an asynchronous Reinforcement Learning (RL) problem.
This is not just a theoretical convenience — it directly aligns the training signal with real deployment utility, not just offline imitation quality. Speculative decoding maps naturally to reinforcement learning:
In this framing, maximizing the return maps directly to maximizing acceptance length — which maps directly to decoding speedup. A subtle but powerful part of Aurora is that it does not only learn from accepted tokens. Acceptance loss (imitation) uses cross-entropy on accepted tokens, encouraging the draft to reproduce verifier-approved continuations. Rejection loss (Discard Sampling) teaches the draft what not to propose, using rejected branches as counterfactual supervision.
To efficiently process the complex branching structure of speculative decoding results, we employ a specialized Tree Attention mechanism. By constructing a custom attention mask that respects the causal structure of the speculative tree, we can process all accepted and rejected branches in a single batched forward and backward pass.
3. Adaptation to distribution shift
To test Aurora's robustness, we simulated live serving traffic using a stream of 40,000 prompts spanning five domains: mathematical reasoning, text-to-SQL, code generation, finance, and general conversation. This composition reflects realistic deployment scenarios where serving traffic exhibits heterogeneous and shifting task distributions. We evaluated two traffic patterns: (i) ordered streams, where requests are grouped by domain to induce abrupt distribution shift, and (ii) mixed streams, where prompts are randomly shuffled to approximate stationary traffic.
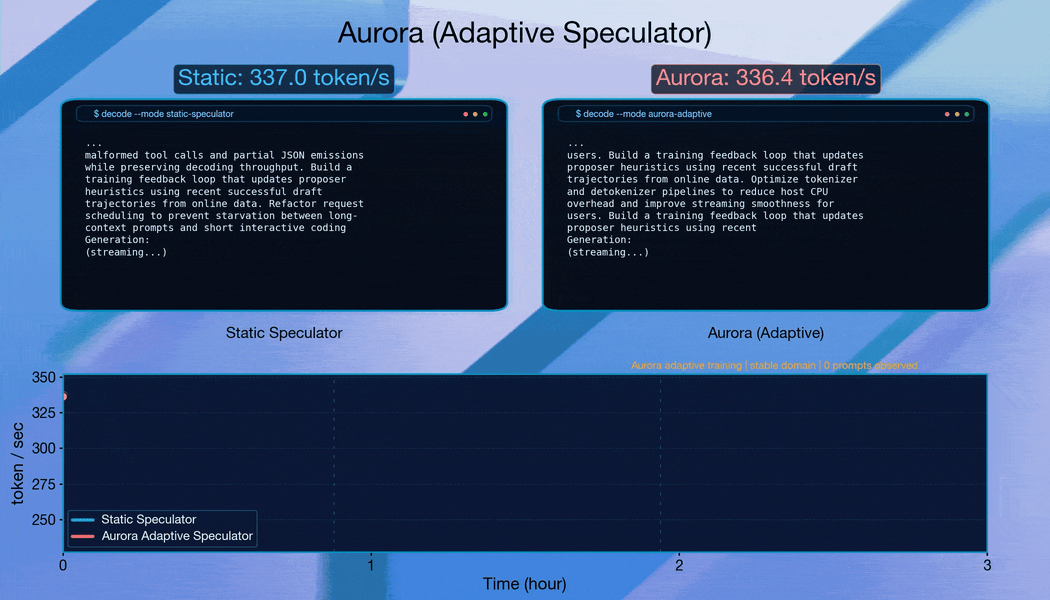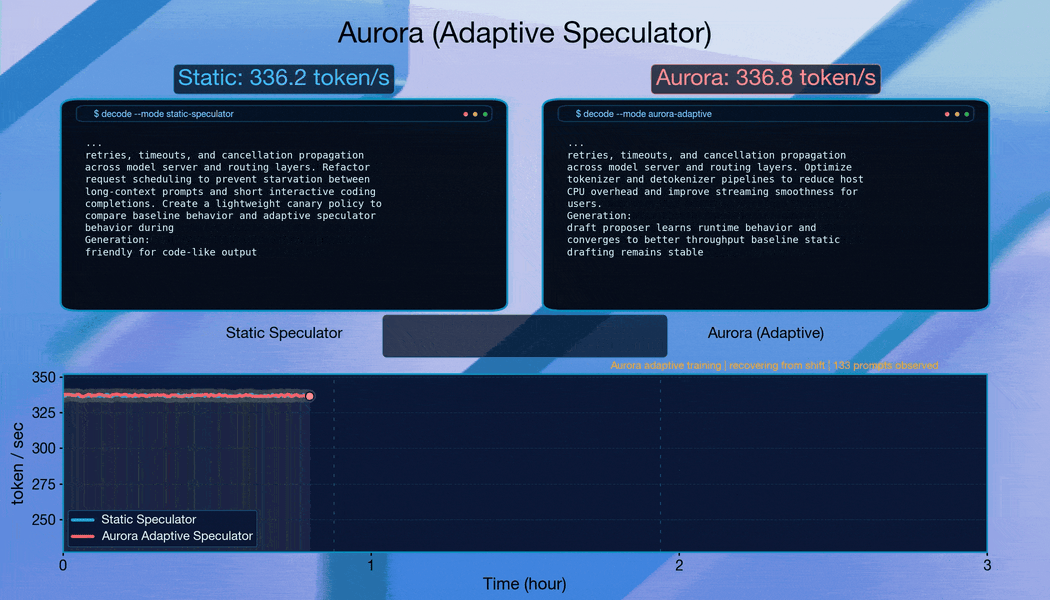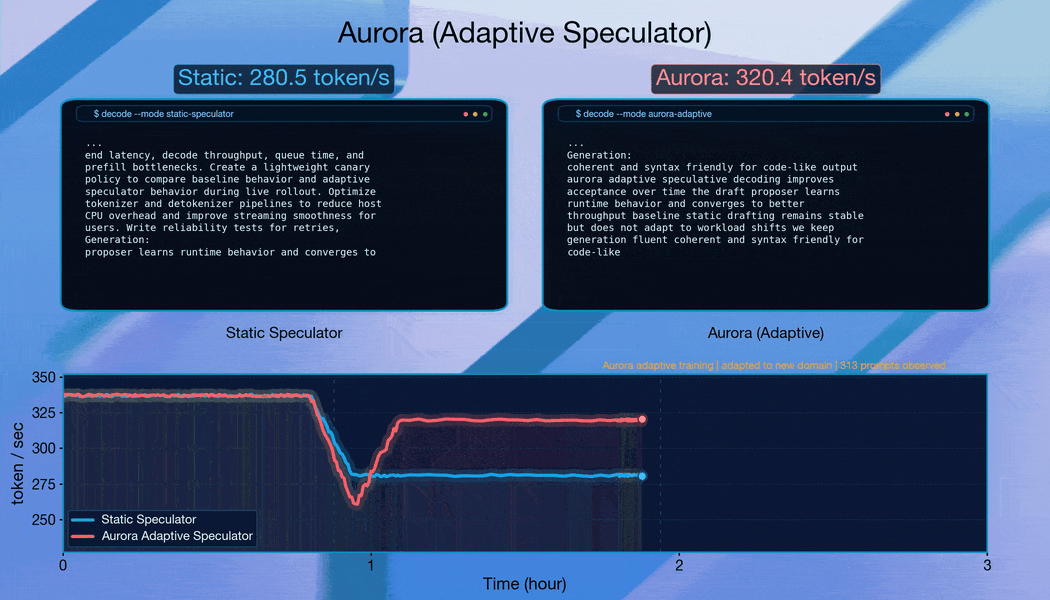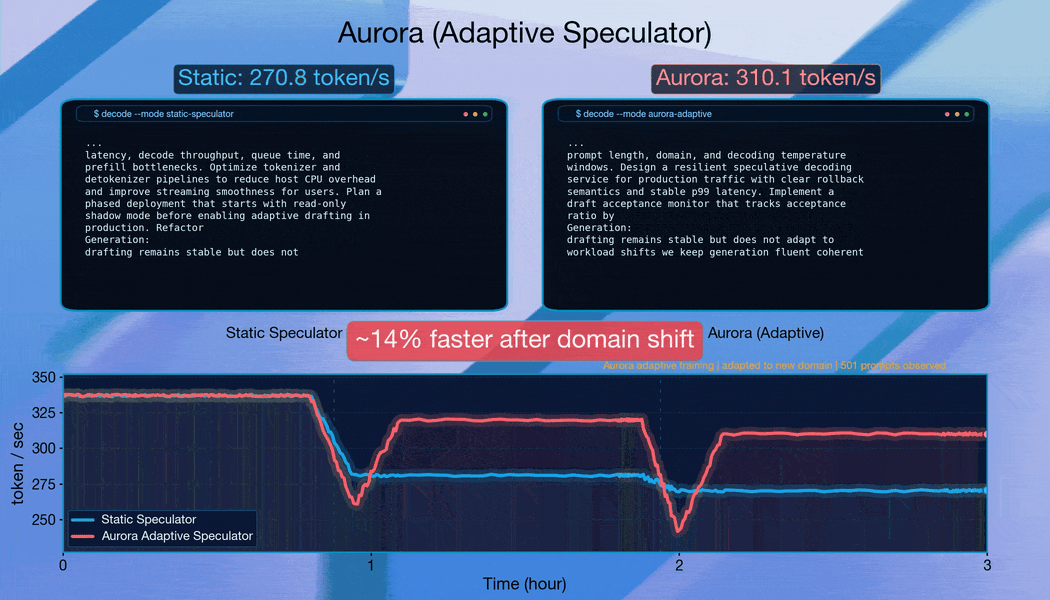
When requests are grouped by domain to induce abrupt distribution changes, Aurora adapts continuously. The system recovers acceptance length within approximately 10,000 requests after each shift, demonstrating robust online adaptation.
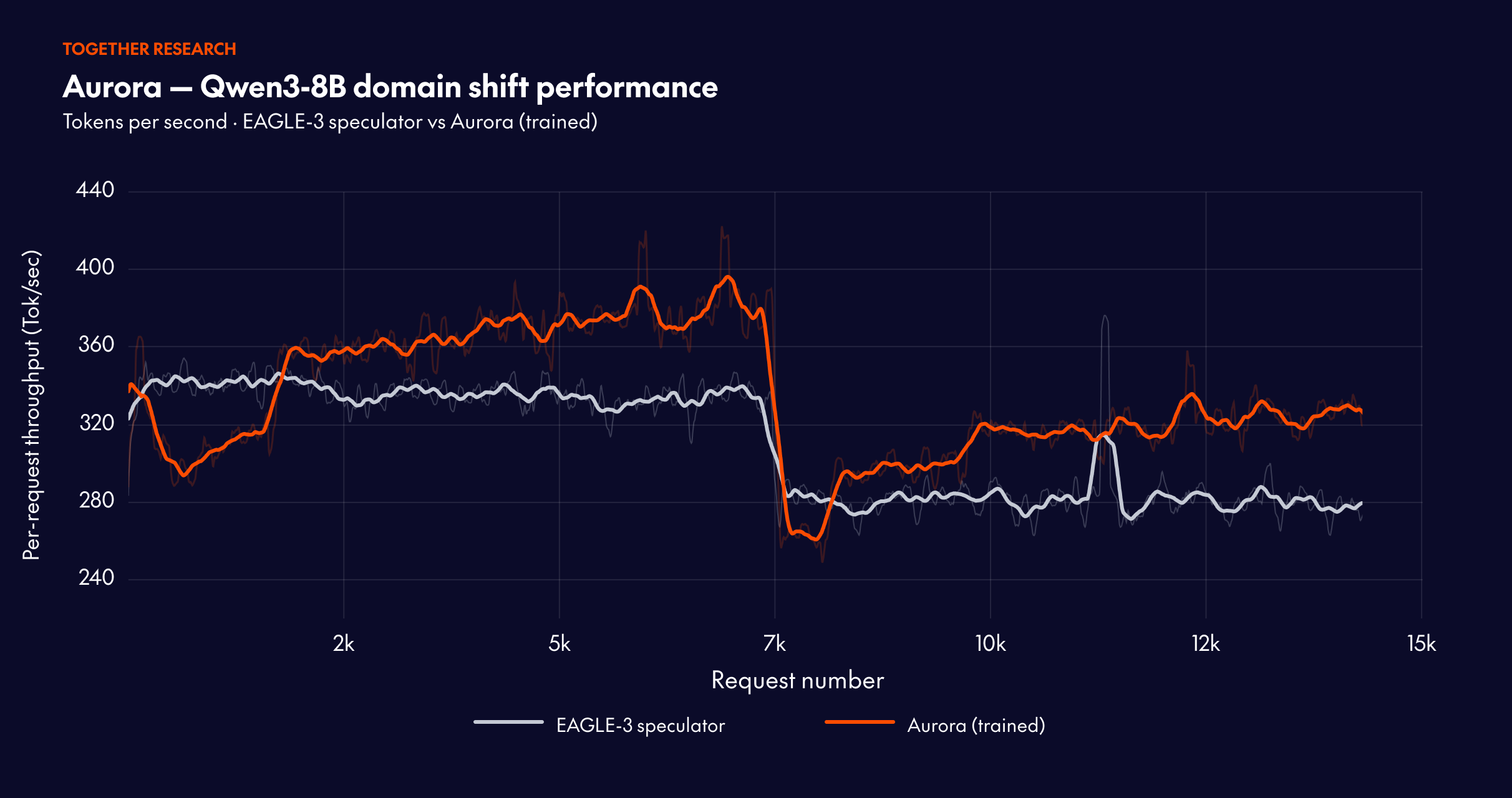
Starting from a well-trained speculator, Aurora achieves an additional 1.25x speedup over the static baseline through continuous adaptation. This demonstrates that Aurora’s benefits compound on top of existing offline training investments.
The mixed traffic results are particularly striking: online training from scratch can exceed the performance of a carefully pretrained speculator. The acceptance length reaches 3.08 (surpassing both the static baseline at 2.63 and the pretrained-then-finetuned baseline at 2.99), with throughput stabilizing at 302.3 tokens/s. This fundamentally challenges the conventional wisdom that speculative decoding requires extensive offline pretraining.
4. Conclusion
Aurora is not just another speculative decoding algorithm. It is a systems shift. It changes speculative decoding from a static, offline task to a dynamic, online learning process.
This shift unlocks real-time utility feedback, adaptation under domain drift, lower infrastructure cost compared to large offline distillation pipelines, and a system layer that is compatible with future speculator algorithms. That’s why the right abstraction for speculative decoding is no longer just better draft training in isolation — it’s a unified training-serving loop.