
Summary
We introduce consistency diffusion language models (CDLM), which accelerates diffusion language model inference by combining consistency-based multi-token finalization with block-wise KV caching, achieving up to 14.5x latency speedups on math and coding tasks.
Diffusion Language Models (DLMs) are emerging as a promising alternative to autoregressive (AR) LMs. Instead of generating one token at a time, DLMs iteratively refine a partially masked sequence over multiple sampling steps, gradually transforming a fully masked sequence into clean text. This refinement process creates a compelling opportunity: it enables parallel generation, allowing the model to finalize multiple tokens per iteration and potentially achieve higher throughput than AR decoding. At the same time, it can exploit bidirectional context to unlock new capabilities such as text infilling and refinement.
.gif)
However, in practice, standard DLMs suffer from two major inefficiencies. [1]
- KV caching incompatibility under full bidirectional attention.
Standard DLMs commonly use bidirectional (non-causal) attention, which requires recomputing attention over the full context at every denoising step, making inference expensive and preventing standard KV caching. - High refinement step counts to maintain quality.
High-quality generation typically requires many denoising/refinement steps, often comparable to the generation length. Naively reducing the number of steps tends to degrade quality sharply.
CDLM targets both bottlenecks through a post-training recipe that makes fewer-step inference reliable while enabling exact block-wise KV caching.
Preliminary: Inference in diffusion language models
DLM generation is an iterative refinement over N discrete sampling steps. It transforms a fully masked sequence at time t=1 into a clean sequence at t=0. At each step, the model predicts a clean sequence distribution x0 given the current noisy sequence xt and prompt c:
$p_{\theta}(\mathbf{X}_0 \mid \mathbf{X}_t, c)$
A common deterministic instantiation is low-confidence remasking: the model greedily unmasks tokens (often within blocks), finalizing the highest-confidence masked positions while keeping others masked. This leads to the decoding trajectory:
$\mathcal{T}_{\mathbf{x}} = \left(\mathbf{x}_{t_0}, \mathbf{x}_{t_1}, \ldots, \mathbf{x}_{t_N}\right), \quad t_k = 1 - \frac{k}{N}$
which records how the partially refined sequence evolves step-by-step. This trajectory becomes the core object for CDLM’s training.
CDLM training
1) Trajectory collection
We collect trajectories offline by running inference with a DLM on domain-specific prompts. For each prompt x, we record the token-level decoding trajectory T_x, a compact hidden-state buffer H_x containing last-layer hidden states at token finalization moments, and the ground-truth text ŷ. Concretely, we adopt block-wise decoding with a generation length L_g = 256, block size B = 32, and a total of N = L_g steps (i.e., finalizing exactly one token per step within the current block). This conservative setting yields higher-quality trajectories for distillation.
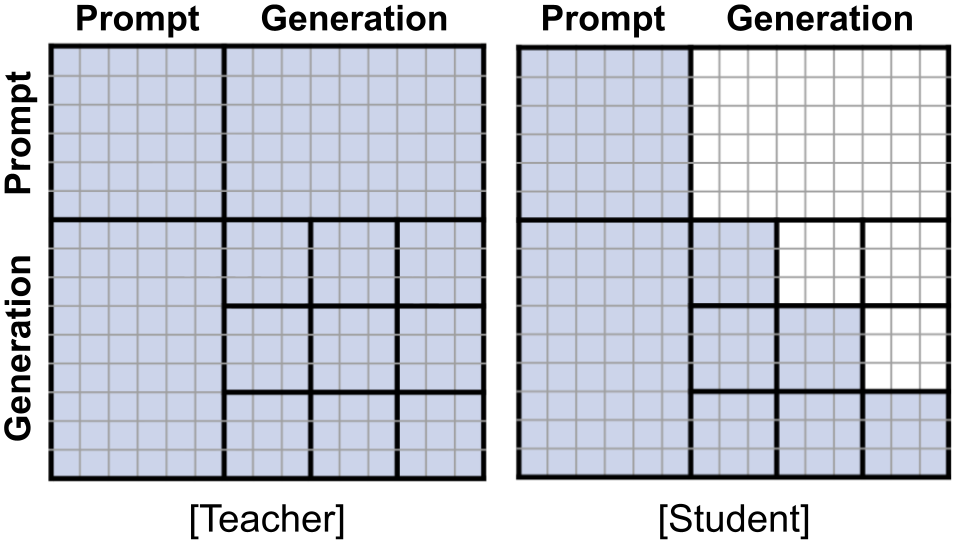
2) Block-causal student and attention mask
During trajectory extraction, we use a full bidirectional attention mask. In contrast, when training CDLM, we employ a block-wise causal mask that attends to the prompt, previously completed blocks, and the current decoding block. This design enables the model switch from full bidirectional to block-diffusion models (like [2]), enabling exact block-wise KV caching for finalized blocks.
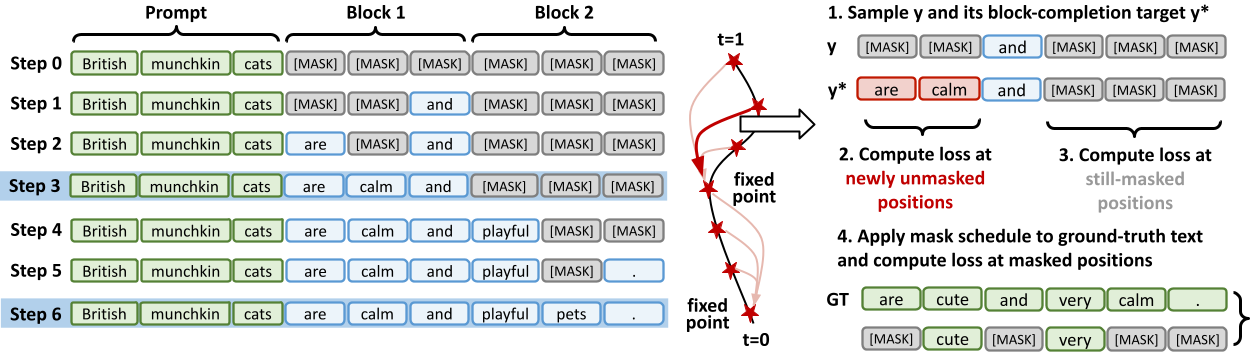
3) Training objectives
CDLM jointly minimizes three objectives:
(i) Distillation loss (newly unmasked positions)
For positions that become newly unmasked between an intermediate state y and its block completion y*, we match the student’s predictive distribution to the teacher’s reconstructed distribution obtained from stored hidden states.
Intuition: this objective serves as the primary anchor that teaches the student to finalize multiple tokens within a block under block-causal constraints.
(ii) Consistency loss (still-masked positions)
We enforce within-block temporal consistency by aligning the student’s predictions at state y with its own predictions at the more informed state y* for still-masked positions, using a stop-gradient target.
Intuition: this objective encourages stable multi-step transitions along the decoding trajectory.
(iii) Auxiliary DLM masked-denoising loss
We include a standard masked denoising objective applied to randomly masked ground-truth text.
Intuition: this objective preserves the model’s general masked-token prediction capability and helps retain reasoning behavior, particularly on mathematical tasks.
4) Inference
At inference time, CDLM decodes in a block-wise autoregressive manner, reusing the KV cache for the prompt and all previously finalized blocks. Within each block, we apply confidence-thresholded parallel finalization. [3] We also adopt early stopping once an end-of-text token appears in the current block.
We intentionally avoid additional heuristics that introduce extra hyperparameters (e.g., inter-block parallelism with task-dependent settings), and instead focus on a robust default decoding pipeline based on exact KV caching and reliable step reduction.
Main Results: CDLM–Dream
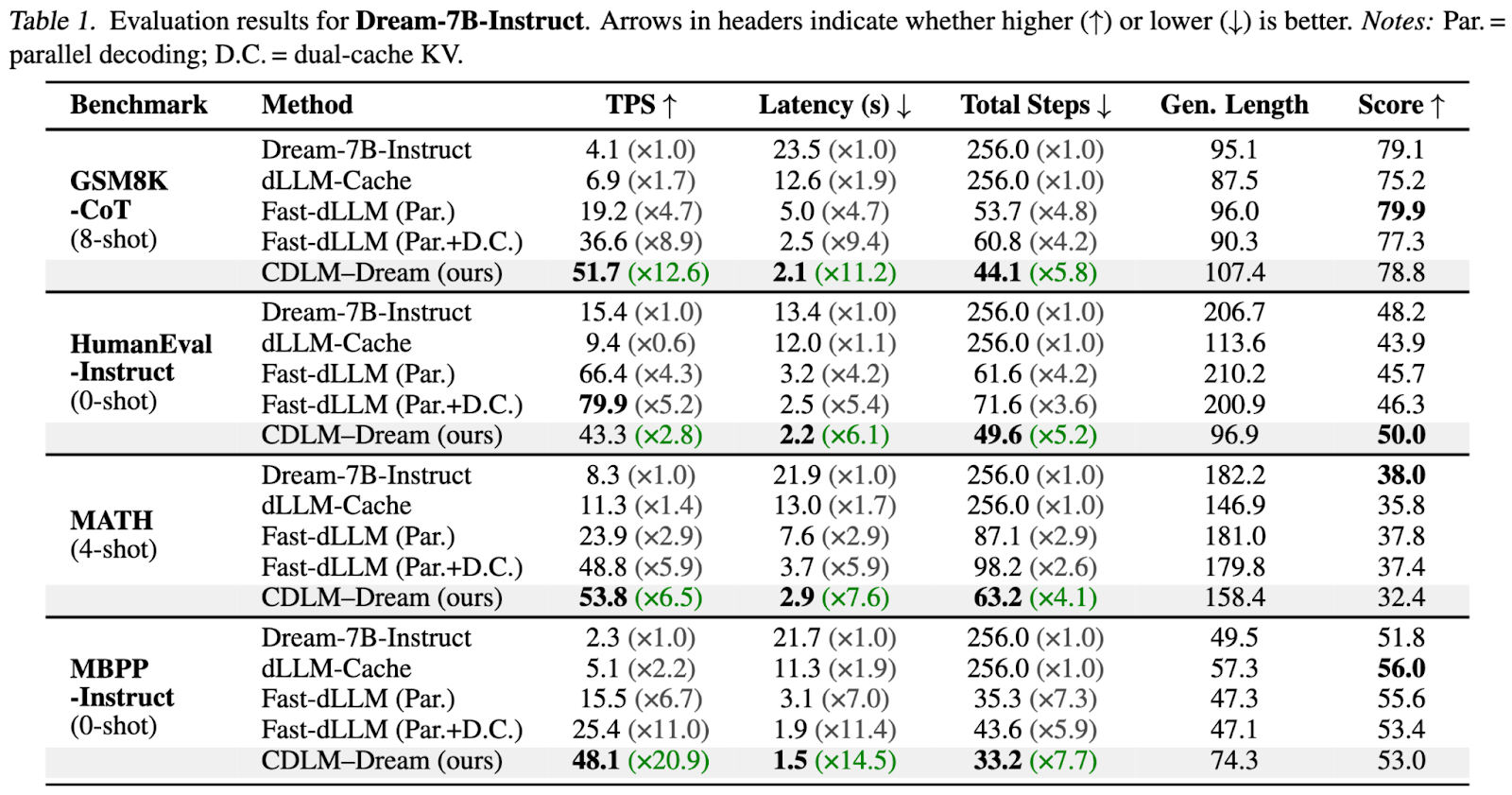
What we see:
- CDLM–Dream achieves the largest step reductions across benchmarks, cutting refinement steps by roughly 4.1x–7.7x with minor accuracy changes on most tasks.
- These step reductions translate into large latency improvements: up to 11.2x on GSM8K-CoT and 14.5x on MBPP-Instruct.
- CDLM often attains the highest Tokens Per Second throughput, with one notable nuance: tasks can show different decoding dynamics because CDLM is strictly block-causal and may produce shorter outputs while preserving pass@1 quality.
Effective step reduction: Why training matters
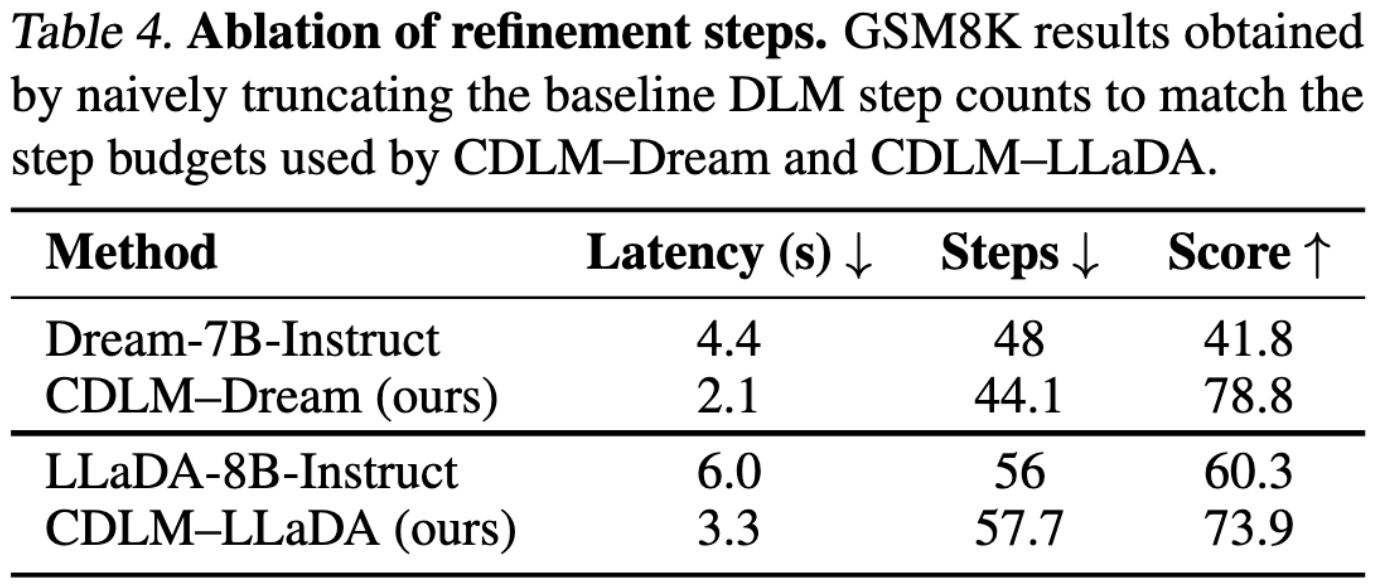
Naively truncating the number of steps causes marked accuracy degradation, while CDLM maintains quality at similar step budgets (and achieves roughly half the latency thanks to caching). This highlights the core point: stable multi-token refinement is not free; it requires training that enforces trajectory-consistent behavior.
System-level analysis: Why block-wise DLM sits in the sweet spot
To understand hardware utilization, we analyze arithmetic intensity (AI), FLOPs per byte moved, as batch size increases, comparing: AR decoding, vanilla (full-attention) DLMs, block-wise DLMs (CDLM) with B∈{4,16,32}.

Key interpretation:
- AR decoding is strongly memory-bound at small batch sizes (AI near 1 at bs=1), scaling as batch increases due to weight-load amortization.
- Vanilla DLMs are compute-bound even at bs=1 because full bidirectional attention processes the whole sequence each step, leading to saturation.
- Block-wise DLMs (CDLM) occupy an intermediate regime: higher AI than AR due to intra-block parallelism (processing B tokens under similar memory traffic), but lower than vanilla DLMs, often a balanced operating point for small-batch settings.

Overall, the analysis explains why CDLM-like block-wise diffusion can deliver strong efficiency at small batch sizes: it uses parallelism to amortize memory access while remaining in a regime that still benefits from practical scaling.
Discussion & conclusion
Expressiveness vs. efficiency
Full bidirectional attention in DLMs requires recomputing O(L^2) attention at every denoising step, making inference highly compute-intensive. CDLM enables exact KV caching while preserving bidirectional context within each block, retaining local refinement capabilities (e.g., infilling inside the current block).
Scaling with stronger DLM backbones
CDLM is a post-training recipe that can be applied to any block-diffusion model, and its benefits should grow as stronger DLMs emerge. A promising direction is to collect trajectories from larger, stronger DLM teachers and train mid-scale students with CDLM.
Conclusion
We presented CDLM, a training-based acceleration scheme that brings consistency modeling to DLMs. By enforcing within-block temporal consistency and fine-tuning a block-wise causal student, CDLM reduces refinement steps and enables exact KV caching. Across math and coding tasks, CDLM yields faster inference, fewer steps, lower latency, and higher throughput while maintaining competitive accuracy.
[1] Beyond Next-Token Prediction: A Performance Characterization of Diffusion versus Autoregressive Language Models
[2] Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
[3] Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding