

The breakthrough came on a holiday weekend. Memorial Day 2022. While most of Silicon Valley was at barbecues, Dan Fu, Tri Dao, and their colleagues were about to prove the AI establishment wrong.
The conventional wisdom was settled: transformer attention was already optimized. GPU experts had squeezed every drop of performance from the hardware. There wasn't much left to gain.
Then Dan, Tri, and their colleagues published FlashAttention.
Andrej Karpathy, then Senior Director of AI at Tesla, tweeted about it that afternoon. Within hours it was ricocheting through AI research channels. "Honestly, we weren't expecting anybody to see it when we released it," Dan recalls. "We were prepping some blogs and code release for Tuesday morning. But then we saw Karpathy tweet about it Monday at 7 p.m. — so then we knew it was something people were paying attention to."

Previous work on sparsity and low-rank methods showed theoretical speedup but only 10% real performance gains. The FlashAttention team took a different approach: understanding actual GPU memory movement and compute patterns. By applying classic database systems principles (unglamorous stuff about data locality and memory hierarchies) to attention, they achieved 2–3x speedups.
For the researchers behind it, the implications were clear. Enormous untapped potential remained in GPU optimization. That single paper became the foundation for what's now one of the most impactful kernel research teams in AI, and a critical building block of the AI Native Cloud.
The problem no one was talking about
Here's what most people don't understand about AI: having the best models and the best hardware isn't enough. The bottleneck is the gap between them: the software layer that translates mathematical operations into silicon instructions. That's where kernels come in.
The gap between what researchers design and what actually runs fast on hardware is vast. Many foundational architectures (ResNets, LSTMs, RNNs) were designed before the scaling paradigm took hold. As researchers began scaling models to hundreds of billions of parameters, hardware evolved with them. GPUs became increasingly specialized matrix multiplication machines, tuned for the Transformer architectures dominating modern AI.
Kernels are the translation layer between mathematical abstraction and silicon reality: the software that tells GPUs exactly how to move data and perform computations efficiently. Get them right, and you unlock the full power of the hardware. Get them wrong, and that hardware sits idle.
For AI-native applications (products built with AI at their core), this gap is existential. You can't build a responsive AI-native app on infrastructure running below optimal capacity. You can't scale an AI-native business when inference costs are 2x higher than they should be. The AI Native Cloud requires AI-native infrastructure, optimized from the silicon up.
One week to match a year's work
In March 2025, our kernels team had grown to about 15 people: a mix of ML researchers seeking systems challenges and GPU veterans moving into AI. We'd just gotten access to NVIDIA's new Blackwell GPUs, the latest generation of hardware with fundamentally different capabilities from their predecessors.
The challenge was specific: NVIDIA's teams had spent a year developing optimized kernels for Blackwell, with dozens of engineers and intimate knowledge of the hardware. We had a week.
We needed something that would let us move fast. That something was ThunderKittens, a library we'd been developing in collaboration with researchers at Stanford.
"We had experience adapting kernels to new hardware, and we knew it would take time," Dan says. "For example, FlashAttention-3 came out a year after general Hopper availability. We wanted to build tools to make it easier to quickly build kernels for the new hardware generation, and ThunderKittens was the answer."
ThunderKittens is built around NVIDIA's tensor cores, the hardware units on the GPU specialized for matrix multiplication. By building abstractions around tensor cores, ThunderKittens reduces what was once 1,000+ lines of CUDA code to 100–200 lines.
The team worked around the clock, adapting ThunderKittens to Blackwell's new features: Fifth-generation tensor cores that run 2–2.5x faster than the previous generation, a new layer of tensor memory providing an extra 256KB of ultra-fast on-chip storage, and CTA pairs that allow thread blocks to coordinate more deeply.
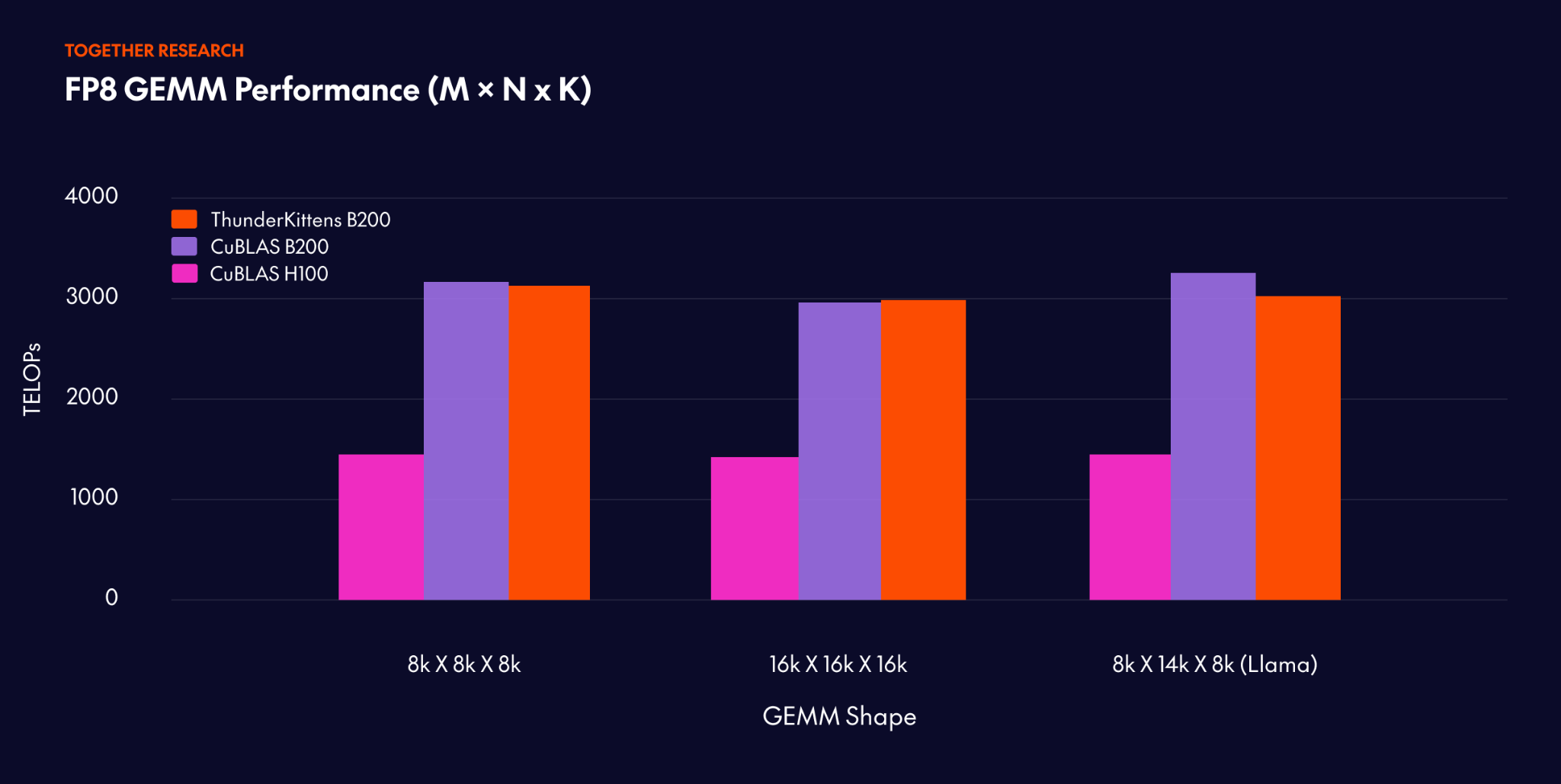
Within one week of hardware access, we had some of the fastest FP4 and FP8 GEMM kernels available for Blackwell, with up to 2x speedups over cuBLAS on H100s.
The academic engine
ThunderKittens didn't come from nowhere. It's part of a broader pattern in how this team is built.
Dan Fu runs a lab at UCSD focused on higher-risk fundamental research, including his personal passion project on FFT algorithms (a niche area most industry researchers would never touch). Together AI co-founder and Chief Scientist Tri Dao is at Princeton. Simran Arora is at Caltech.
The model is symbiotic: de-risk ideas in academia, productionize them at Together AI. PhD students join the company. Together AI interns work on longer-term research in academic labs. Ideas flow both ways.
This philosophy shapes hiring. We're not looking for people who just want to ship code or rack up citations. We want people who lose sleep over memory access patterns. Who find beauty in data flow diagrams. Who get genuinely excited about taking cutting-edge research into production. Research inherently involves repeated failure. You have to be driven by genuine interest above all else. Even non-trendy areas like FFT are worth pursuing if they're genuinely interesting.
The team has become a springboard for the next generation of systems researchers, people who can bridge the gap between theory and production. We've "graduated" Professor Yucheng Lu, now an assistant professor and leader of the HeavyBall Research group at NYU Shanghai.
Together Megakernel: From 281ms to 77ms
One example of applying this academic engine to production use cases involved one of the leading real-time voice agent companies. They came to Together with a hard constraint: time-to-first-64-tokens above roughly 100ms breaks the conversational experience. On their previous setup, deployed on NVIDIA B200 GPUs, they were hitting 281ms. Fast for most workloads. Not fast enough for theirs.
Together's kernels team worked with them to select a model architecture, then hand-optimized a Megakernel implementation that runs an entire model in a single kernel, targeting the HBM bandwidth ceiling of the NVIDIA H100.
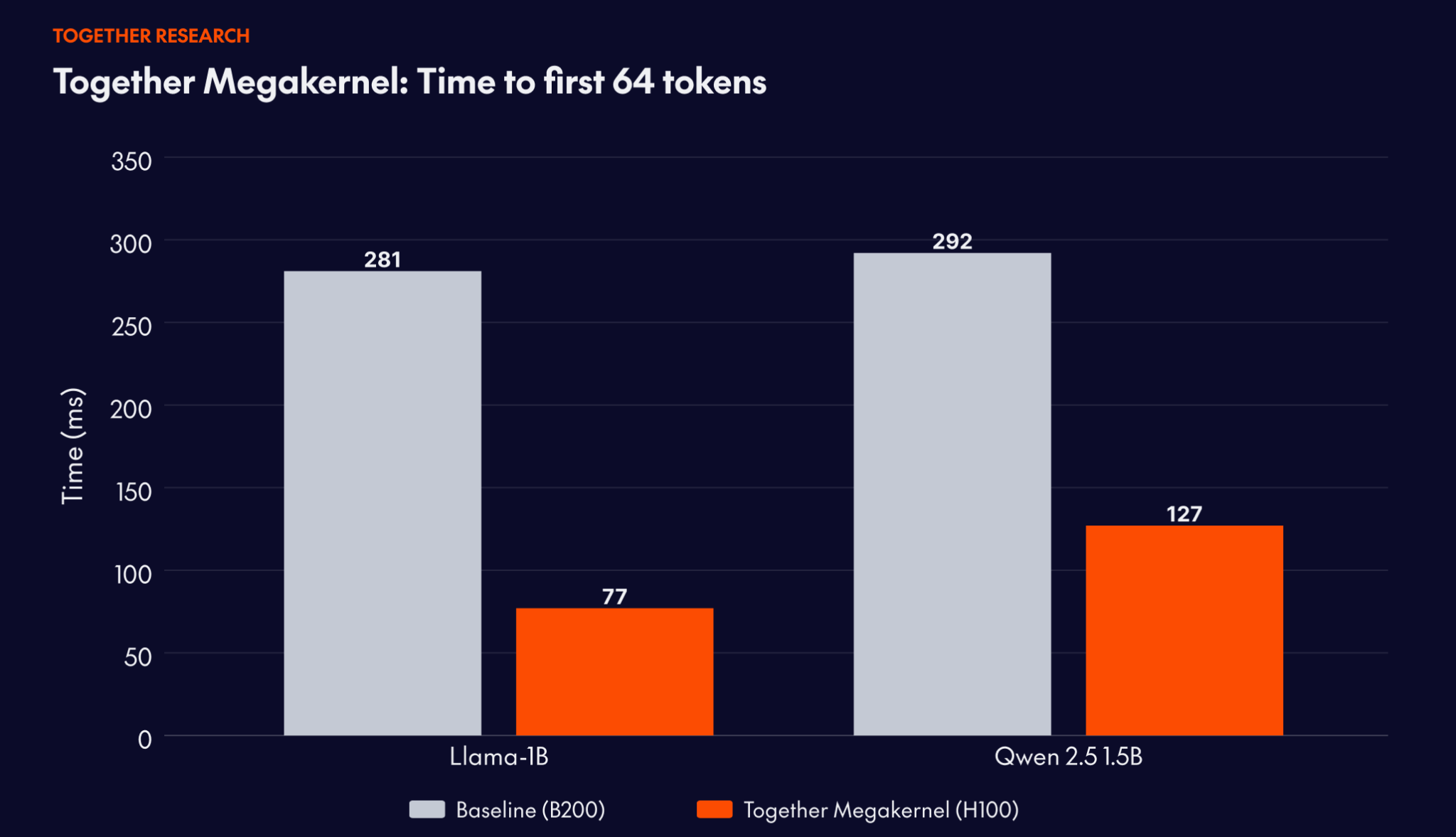
The result: 77ms on Llama-3.2-1B, a 3.6x performance improvement and 7.2x better unit economics compared to their prior deployment. On Qwen 2.5 1.5B: 127ms, down from 292ms on the B200 baseline.
Together Megakernel is the production implementation of open-source research initially developed with collaborators at Stanford. Backed by the same research lineage as FlashAttention, it's hardware-software co-design that closes the gap between what's theoretically possible and what deployed systems actually deliver.
World-class research meets production reality
Here's what makes Together AI different: our kernels team isn't just a research organization publishing papers. We're customer-facing, working directly with strategic partners to improve their deployments.
Take Cursor. When you're building an AI-native product where every millisecond of latency matters, where developers are waiting for code completions in real-time, generic infrastructure doesn't cut it. You need custom optimization for your specific workload, your specific models, your specific SLA requirements.
That's what you get when you partner with Together AI: direct access to a top-tier kernel research team. We profile your workload. We identify bottlenecks. We write custom kernels to eliminate them. We're not a hyperscaler where you're a small fish in a big pond, filing support tickets and hoping someone eventually looks at your issue.
For customers with the tightest SLAs (the ones who need real-time responses, the ones running at massive scale where every percentage point of efficiency translates to millions in cost savings) we build custom solutions. Custom kernels for system bottlenecks. Custom optimizations for specific model architectures. The full weight of our research team focused on making your deployment as fast as physically possible.
This is what the AI Native Cloud looks like in practice: world-class research teams working hand-in-hand with AI-native builders, closing the gap between what's theoretically possible and what's actually running in production.
Collaborative, curious, relentless
Our team culture is built around intellectual curiosity and collaboration, not competition — about 15 people with what Dan Fu calls a "gung ho" mentality.
"We're nice people," Dan says. "No rockstar egos. Just people who are excited about this time and who love solving hard problems together."

The team has two main archetypes: ML people wanting systems challenges, and GPU/graphics people moving into ML. Both need to learn the other half. "You're understanding all the pieces so you know how they work together," Dan explains.
We're looking for people who want to get deep into technical details, to leave no stone unturned — not just how to make something work, but why it works, how it could work better, what fundamental principles govern its behavior.
The work is sometimes unglamorous. There's no announcement when a kernel optimization lands. Just faster training times, lower costs, higher throughput: The metrics that determine whether production systems run or don't.
But these margins matter more than almost anything else.
It’s the difference between a model that trains in three weeks versus three months; between an API that responds in 100 milliseconds versus 1 second; between spending \$10 million on compute versus \$5 million for the same results. For the next generation of AI-native applications and companies, these margins determine whether your product feels instant or sluggish. Whether your unit economics work or don't. Whether you can scale to millions of users or plateau at thousands.
Data quality matters. Model architecture matters. Training techniques matter. But if you can't make the hardware work efficiently, none of that other stuff scales.
And for a certain type of engineer, the kind who finds beauty in memory access patterns and computational efficiency, who wants to work on the invisible scaffolding that makes everything else possible, this is the most exciting place to be.
Join us
We're hiring for our kernel research team. If you're passionate about performance optimization and eager to work at the intersection of hardware and AI, apply today.