
Today, we are excited to announce on-demand Dedicated Endpoints—now available with up to 43% lower pricing, delivering the best price-performance in dedicated GPU inference.
Scaling AI applications require reliable, high-performance, and cost-efficient GPU compute, however, finding an offering that balances flexibility and affordability remains a challenge for many startups. Leading AI companies—like BlackBox AI and DuckDuckGo—have successfully brought their AI apps to production with Together Serverless Inference. Serverless deployments offer unmatched flexibility and ease of use, making them an ideal starting point for companies running AI apps in production
As companies scale their generative AI applications in production, they often need guaranteed performance, more control and customizability over their deployment, and support for custom models. That’s where Together Dedicated Endpoints come in. Bridging the gap between the flexibility of serverless deployments and the reserved capacity Together GPU Clusters, Dedicated Endpoints deliver optimal price-performance for scaling AI inference in production:
- The same high performance as serverless—but with single-tenancy, ensuring your traffic is never impacted by other users.
- The most price-competitive dedicated GPU inference available today—up to 50% cheaper than competing providers.
- Substantial cost savings at scale compared to serverless.
- Full control and customizability over the deployment hardware and configuration.
- Support for custom fine-tuned models.
- No minimum commitments, fully self-serve.
With this update, you can spin up on-demand Dedicated Endpoints for dozens of top open-source models—like DeepSeek-R1 and Llama 3.3 70B—or upload your custom fine-tuned model from Hugging Face, deploy it instantly, and start running inference. No upload or storage costs—just pay for the deployment itself.
Performance & control to scale in production
With Dedicated Endpoints, you get full control over a single-tenant GPU instance to deploy any model, without sharing compute resources. Using our web UI, API, or CLI, you can customize your deployment on some of the most powerful NVIDIA GPUs, including HGX H200 and HGX H100, ensuring optimal performance for your workload.
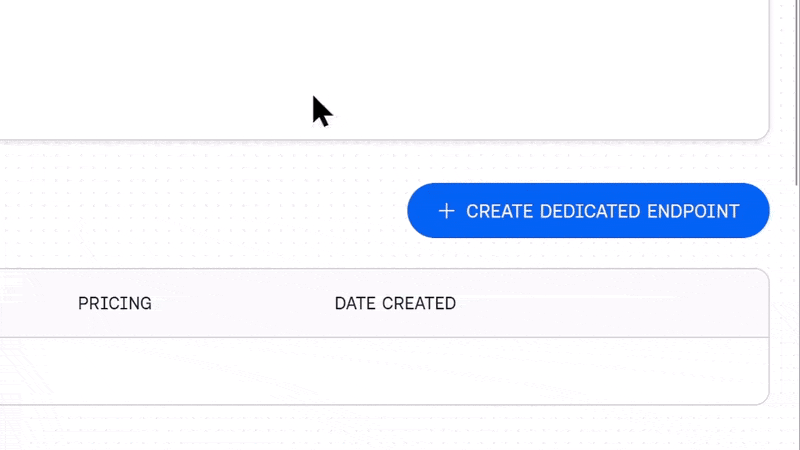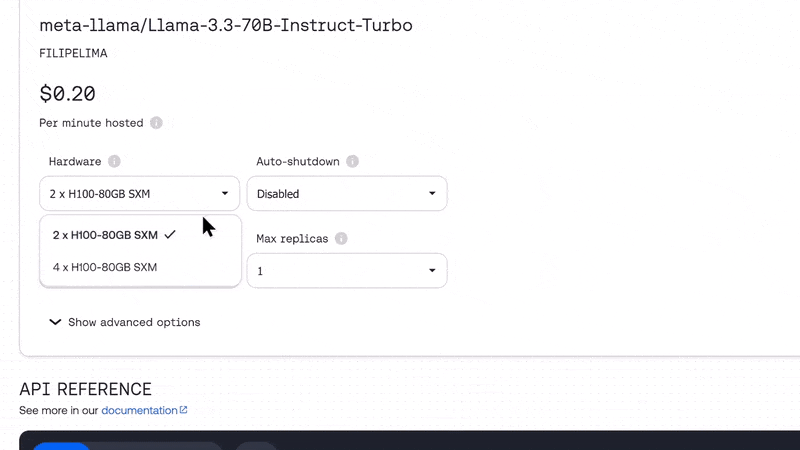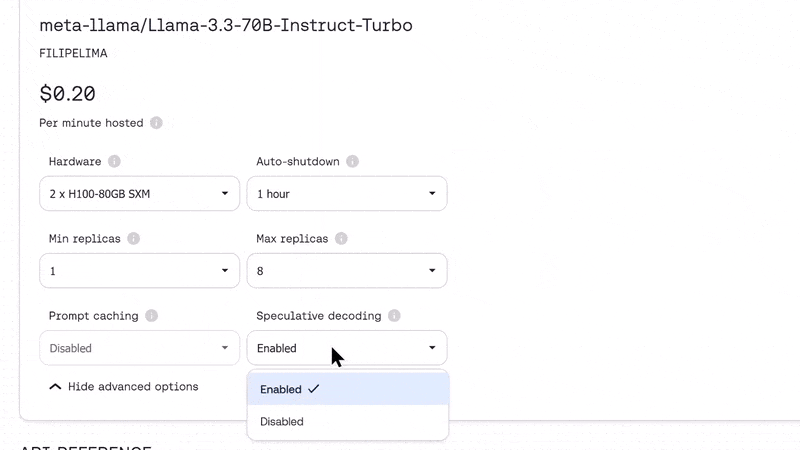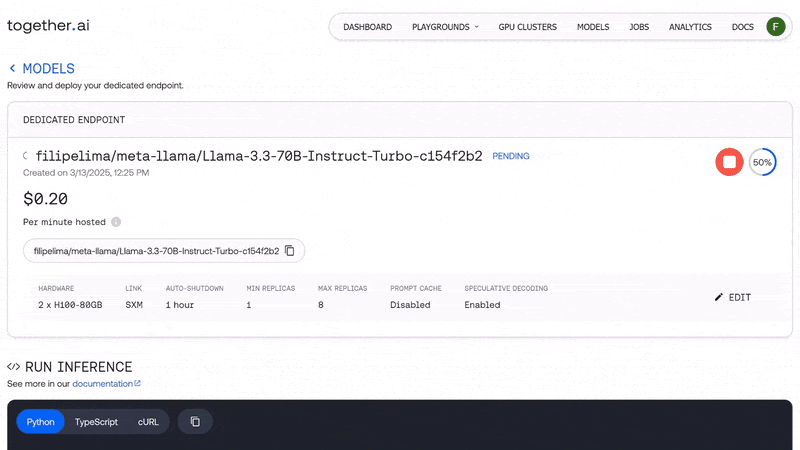
Dedicated Endpoints take the high-performance of serverless to a new level, by guaranteeing consistency with no resource contention. On top of that, they allow you to enable/disable optimizations such as speculative decoding, which enhance text generation efficiency by improving throughput and optimizing the handling of ambiguous input, leading to faster, more responsive outputs.
“Together AI’s Dedicated Endpoints give us precise control over latency, throughput, and concurrency—allowing us to serve more than 10 million monthly active users with BLACKBOX AI autonomous coding agents. The flexibility of autoscaling, combined with exceptional engineering support, has been crucial in accelerating our growth.” – Robert Rizk, Co-Founder and CEO of BLACKBOX AI
Unmatched cost savings at scale
Because we have built a full end-to-end AI platform—including our own high-performance GPU infrastructure—we’re able to offer the most competitive pricing for dedicated deployments alongside one of the broadest selections of GPU architectures available today.
Now, we are reducing our Together Dedicated Endpoints prices up to 43%, making this deployment the most cost-effective dedicated GPU inference solution. These updates result in pricing up to 50% lower than other inference providers, delivering unmatched value for scalable, high-performance AI deployments.
Lower total cost than serverless at scale
Thanks to these price reductions and our optimized inference engine, Together AI Dedicated Endpoints often reduce overall costs compared to serverless once you reach a certain scale.
The table below compares pricing between a serverless deployment and a Dedicated Endpoint deployment with two H100 GPUs for some of our most popular serverless models.
These figures show that workloads with average volumes starting at 130,000 tokens/minute are likely to become more economical in a Dedicated Endpoint deployment (with two H100 GPUs) as compared to serverless.
With Dedicated Endpoints, you get the best of both worlds—high performance, flexible scaling, full customizability, and no upfront commitments—all at industry-leading pricing. Read our docs to configure your first dedicated endpoint in seconds and contact us for reserved GPU capacity.
Handle usage spikes seamlessly with scaling
Unlike serverless, where compute resources are shared, Dedicated Endpoints provide isolated, single-tenancy compute, ensuring that your resources remain dedicated exclusively to your workloads. Additionally, it gives you full control over configuring vertical and horizontal scaling options to handle any level of demand.
Scale vertically with more GPUs
If you need more compute power, you can scale your deployment vertically by increasing the GPU count. For example, you can adjust the configuration to deploy with 2, 4 or 8 GPUs per replica.
Scale horizontally with replicas
To ensure your endpoint has the capacity to handle peak workloads, you can set automatic scaling boundaries by defining a minimum and maximum replica count. When traffic spikes beyond your base capacity, additional replicas spin up on demand—ensuring consistent performance with zero manual intervention. You only pay for the extra replicas while they’re running, keeping costs optimized.
These scaling capabilities make Dedicated Endpoints the ideal choice for mission-critical AI applications that require:
- Reliable QPS with no risk of overload.
- Predictable availability, even under unpredictable traffic.
- Seamless handling of surges without performance dips.
Thanks to these scaling options, Together Dedicated Endpoints enable your AI models to scale seamlessly with demand without breaking performance or budget.
Pick the deployment that fits your needs
With this update, Together AI now offers the most comprehensive set of deployment options for inference, ensuring you get the right balance of flexibility, performance, and cost-efficiency.
If you’re unsure which deployment model best suits your needs, here’s a quick comparison:
Need help deciding? Read our docs to explore deployment options or contact us to discuss your specific requirements.
{{custom-cta-1}}
Deploy custom fine-tuned models in Dedicated Endpoints
With these improvements, our Dedicated Endpoints give developers a fast, flexible way to test, benchmark, and deploy models.
Today, we’re taking this a step further by introducing support for uploading fine-tuned versions of popular open-source models and running them on Dedicated Endpoints.
Our new API—available to all developers on Together AI paid tiers—makes deploying custom fine-tuned models easy:
- Upload supported models from Hugging Face with a simple API call (see the list of supported model architectures in our Docs).
- Deploy instantly on a Dedicated Endpoint for high-performance inference.
- Only pay for deployment—no upload fees, no storage costs.
Run the models you need, how you need them, with the best price-performance ratio for dedicated GPU inference.
Configure your custom endpoint today with the fastest GPUs to get maximum performance, control, and cost savings at scale.