
TL;DR
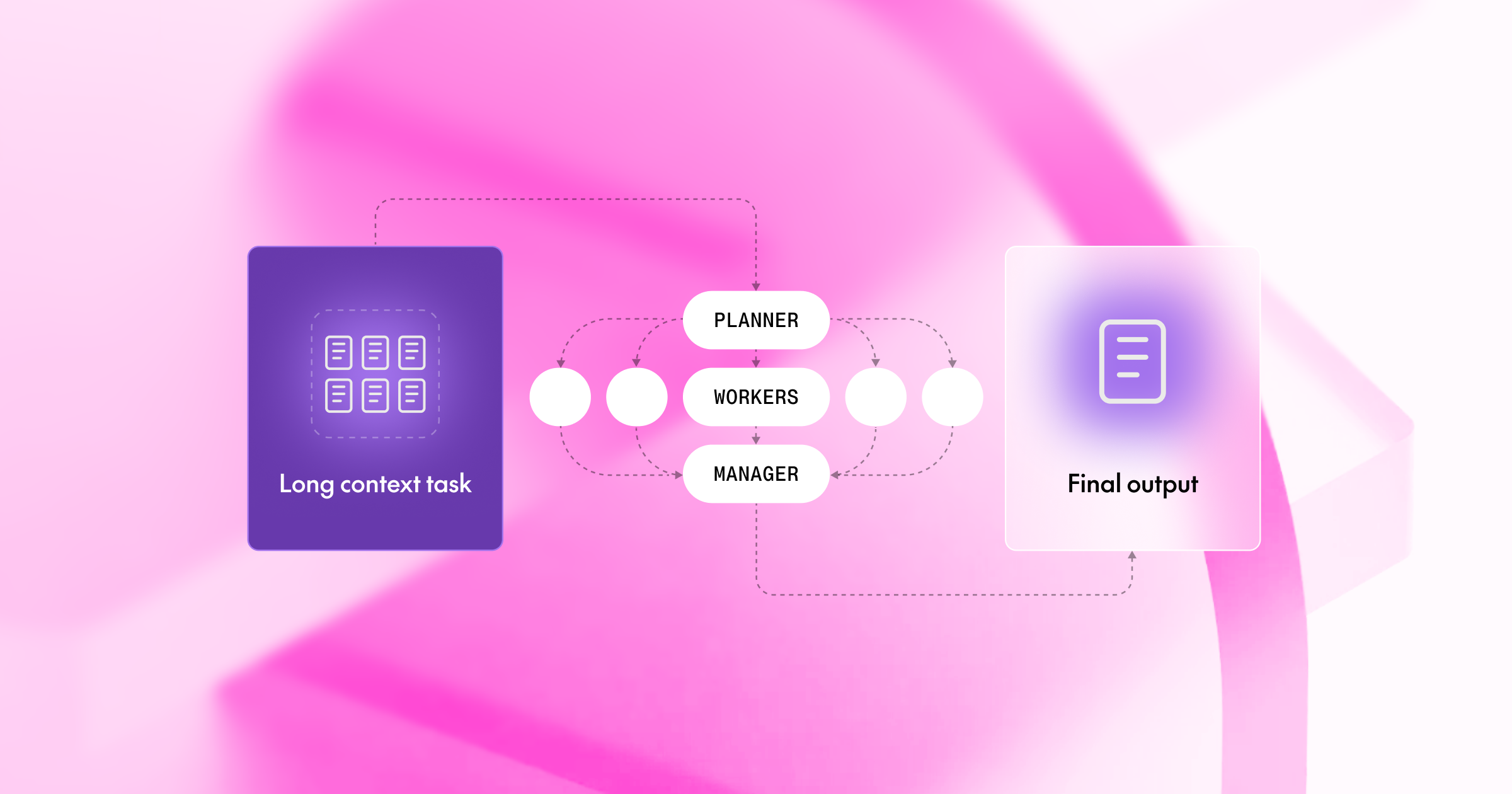
The Intuition: Don't ask one genius to read a library in an hour. Ask ten interns to read one book each.
Our research, "When Does Divide and Conquer Work for Long Context LLM?" (ICLR 2026), introduces a framework to study this. We found that smaller models using a strategic "Divide & Conquer" design can match or beat GPT-4o single-shot on long context tasks.
[paper, ICLR 2026] [code]
Modern LLMs increasingly support massive context windows like 128K, 200K, even 1M+ tokens. This theoretically unlocks powerful use cases like analyzing entire codebases or summarizing full books in a single prompt.
However, the promise of "just throw everything into one prompt" frequently fails in practice. As context length grows, performance degrades in unexpected ways. “Divide and Conquer” turns out to be an attractive solution to long context tasks, as shown in the figure below.
In our paper, we found that weaker models using a carefully designed "Divide & Conquer" framework can match or beat GPT-4o single-shot on long context tasks.
The core problem: The "fog" of length
How can we fully leverage the power of such a “Divide and Conquer” approach for long context tasks? We break the challenge down into three distinct sources of noise:
- Model Noise (The "Brain Fog"): Models don't just forget linearly; they get overwhelmed. Our research shows that model confusion grows superlinearly with input length. It is mathematically better to split the task because you reset that confusion counter with every new chunk in a shorter length
- Task Noise (The "Silo Effect"): Sometimes, a chunk doesn't make sense on its own (e.g., a pronoun referring to a previous chapter). This "Cross-Chunk Dependence" creates noise when the text is split.
- Aggregator Noise (The "Bad Summary"): Even if the workers do their jobs, the final manager model might fail to stitch the partial answers together correctly.
Naive "MapReduce" approaches often fail because of Aggregator Noise i.e. the final answer is messy or inconsistent because the manager lacks context. Our framework predicts that if you reduce this noise through clearer instructions, you can unlock the power of weaker models.
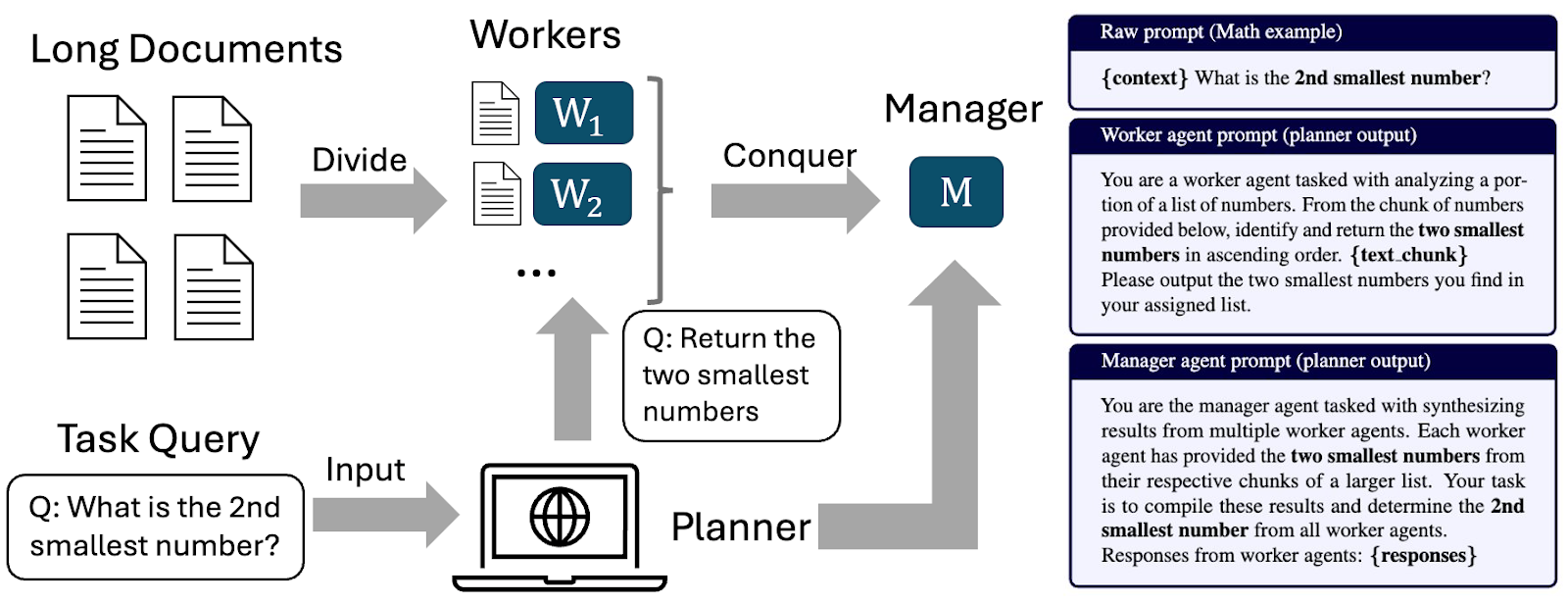
The "2nd Smallest Number" Example: Consider a task where workers must help find the 2nd smallest number in a massive list. If you naively ask workers to "Find the 2nd smallest number" in their specific chunk, the final manager will fail because the global 2nd smallest number might be the smallest number in a specific chunk.
- Naive Prompt: "Find the 2nd smallest number." (Fails)
- Planned Prompt: "Identify and return the two smallest numbers."
By simply adjusting the prompt to account for this aggregation noise, we ensure the Manager has the right data to calculate the global answer.
Validating the theory with experiments
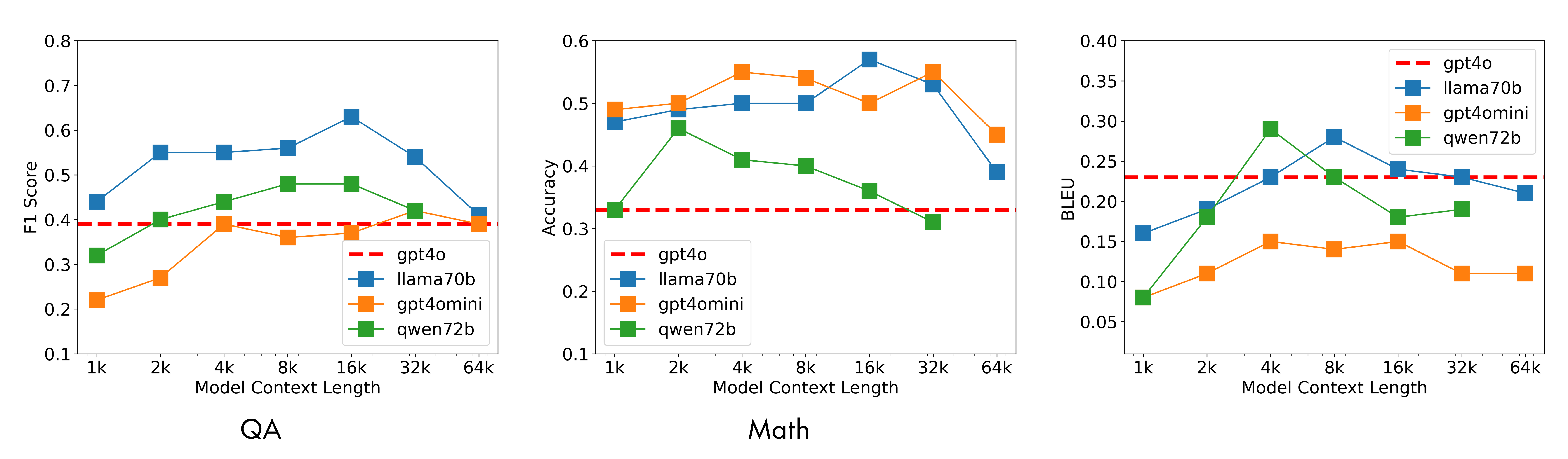
We tested this framework implementation across diverse tasks (retrieval, QA, summarization, etc.). As shown below, a weaker model using this framework (e.g., Llama-3-70B or Qwen-72B) outperforms GPT-4o reading the whole text in one shot. While the single-shot model (red dashed line) degrades as context length increases, the D&C models maintain high performance.
The engineering wins
From the engineering perspective, this framework offers three massive practical benefits:
- Cheaper: You move the heavy lifting to smaller, cheaper models (Workers), rather than paying for flagship tokens.
- Faster: Workers run in parallel. You avoid the high latency of processing a massive 128k token context in a single serial pass.
- Easy to tune: We found that testing just 5 random samples is sufficient to find the optimal chunk size due to the predictability of the noise curve. You don't need to run an exhaustive search over your whole dataset. The other flexibility our framework offers to decouple the worker and manager by assigning different LLM backends.
The catch: When to use single-shot instead of divide and conquer
This method is not a silver bullet. It works best for tasks like QA, Retrieval, and Summarization where cross-chunk dependency is moderate. The benefits end when Task Noise dominates. If your task requires tracking a subtle clue from Page 1 that connects to Page 100 (like the "Dialogue Character Inference" task in our paper), the "Divide" step breaks the necessary context. In these high-synergy cases, the 'genius' model reading the whole library is still the only way to go. Please find more details in our paper.