
Summary
We worked in collaboration with Stanford University, the University of Wisconsin–Madison, and Bauplan to test whether LLMs can optimize database query execution plans. The results show that LLM-guided plan rewrites can improve execution performance without modifying the database engine itself.
Recent advances in AI have been driven by improvements in the underlying systems infrastructure. But this relationship does not have to be asymmetric: AI and LLMs can also be used to optimize the functional components of large-scale systems themselves. Our recent paper shows how AI can be used for database query optimization.
Traditional query optimization relies on cost-based estimators that calculate execution paths using statistical models and predefined heuristics. When executing a query like "find all sci-fi shows with space travel," the optimizer must decide on an execution strategy: Should it first filter for sci-fi shows and then check which have space travel, or vice versa? If the data is spread across multiple tables (e.g., a shows table and a genres table), which table should be scanned first and how should they be joined? The optimizer answers these questions by estimating how many rows will match each condition, then choosing the actual plan (the order of the operations) with the lowest estimated cost.
However, these estimates often assume attribute independence. Consider a streaming service dataset where you want to find shows that are both "sci-fi" AND "have space travel." If 15% of shows are sci-fi and 8% feature space travel, assuming independence would estimate that 1.2% of shows match both criteria (15% × 8%). However, space travel shows are overwhelmingly sci-fi, so the actual overlap is closer to 7%—nearly 6 times higher than predicted.
In fact, these systems generally function well but struggle when heuristics fail to account for semantic correlations within the schema or data. As noted in an example by Lohman (2014), cardinality estimation is the dominant source of optimizer inefficiency because row-count misestimates propagate through the cost model and can lead to systematically poor choices of join order, access paths, and physical operators. This order-of-magnitude error leads to suboptimal physical plans that require substantial engineering effort to correct manually.
Is query optimization a solved problem?
The persistence of these estimation errors shows that physical planning is not a solved problem, particularly for complex OLAP workloads where functional dependencies are common.
To address this, we introduce DBPlanBench, a harness that exposes the query execution process of the Apache DataFusion engine. This system exposes the internal physical operator graph, including join strategies and partitioning schemes, to an LLM. The primary technical challenge here is the information density inherent in raw physical plans, which contain verbose file paths, partition metadata, and type encodings that fill up the context window quickly.
Without careful serialization, the entire plan can exceed 2M characters, making it impossible for LLMs to reason over the inputs effectively and efficiently. Our harness implements a serialization layer that traverses the engine's physical operator graph and maps heterogeneous objects into a unified, token-efficient JSON schema.

This representation deduplicates file-level statistics and removes execution-irrelevant fields, resulting in a payload approximately 10x smaller than the native serialization.
DBPlanBench thereby converts the optimization task from a statistical computation into a semantic reasoning problem, in which the LLM analyzes the plan's topology to identify logical flaws in join ordering.
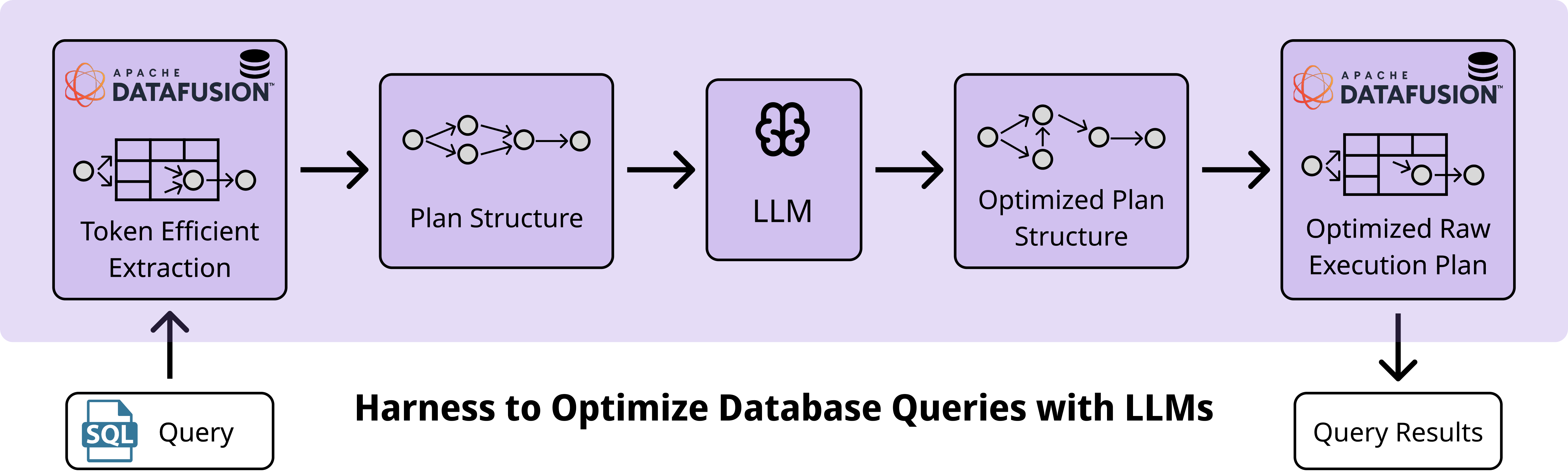
To implement these fixes safely, we instruct the LLM to avoid regenerating an entire physical plan from scratch; instead, it applies targeted edits to DataFusion’s existing physical plan, reducing the risk of syntax errors or invalid plan topology. Concretely, the LLM generates JSON Patches (RFC 6902) that describe localized edits, such as swapping join sides or reordering nodes. These patches are orders of magnitude smaller than the full plan and are applied directly to the serialized graph, ensuring the structural integrity of the execution DAG.

A case study
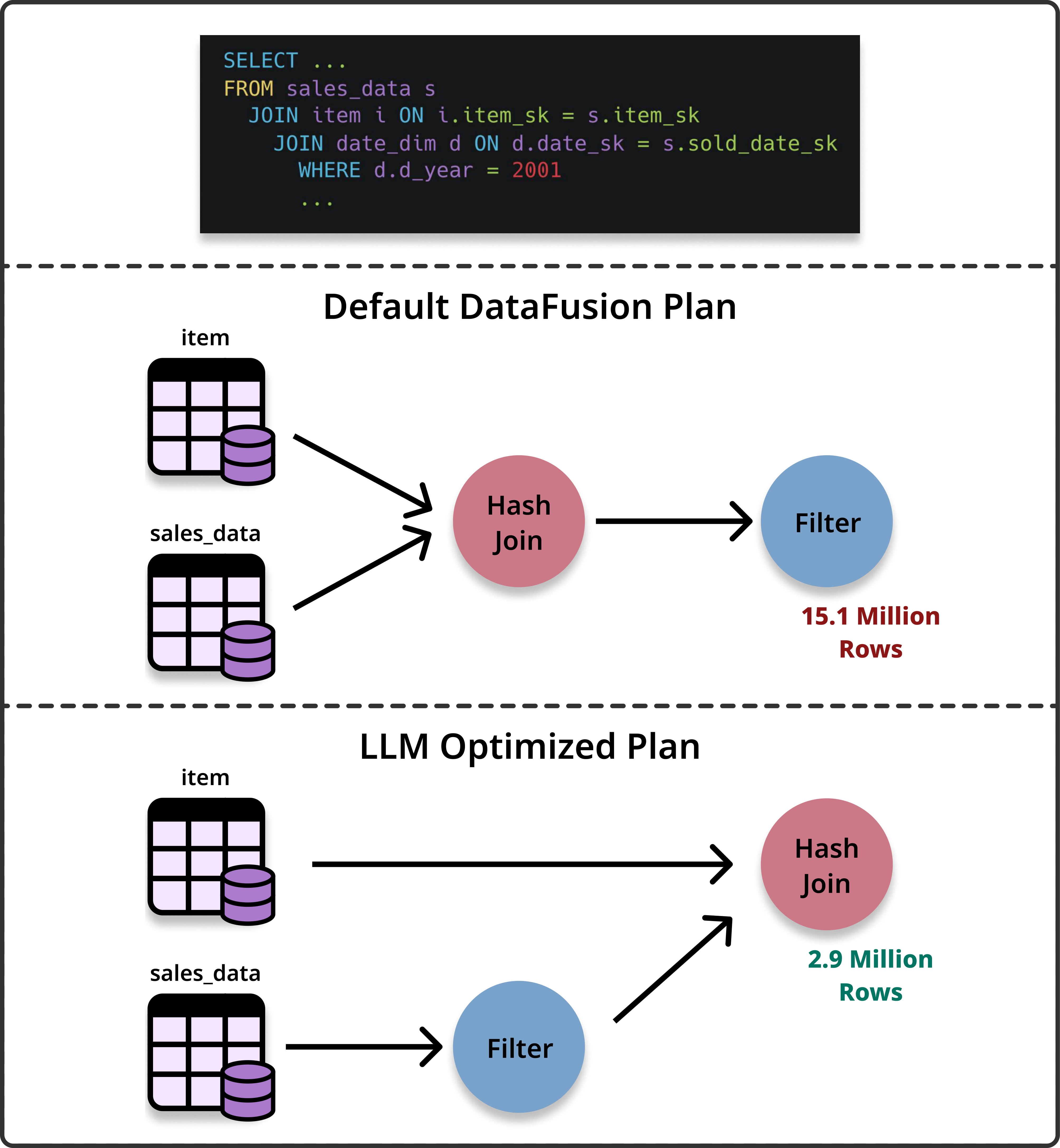
The consequences of statistical estimation failures are measurable in both query latency and system resource consumption. In a specific query generated from a derived version of TPC-DS involving cross-channel sales, the default DataFusion optimizer prioritized joining a smaller item table (36K rows) before a larger date dimension table (73K rows), assuming the smaller join was cheaper. This heuristic failed to account for the high selectivity of the filter d_year=2001 on the date dimension. The LLM-optimized plan inverted this order, applying the date filter early to prune the sales fact table from 15.1 million rows to 2.9 million rows before subsequent joins.
This structural optimization resulted in a 4.78x speedup for the query. More significantly, the resource footprint decreased drastically. The optimized plan reduced the aggregate hash-table build time from 10.16 seconds to 0.41 seconds and slashed total build memory usage from 3.3 GB to 411 MB. The experiments showed that, on generated query workloads for TPC-H and TPC-DS, the median speedups hovered around 1.1x to 1.2x, and the method also delivered much larger gains on some complex multi-join queries, for example, speedups of up to 4.78×, with several others in the 1.5-1.7x range.
Evolutionary plan patching
We evolve query plans through iterative refinement. The system generates candidate improvements (via JSON patches) using GPT-5, validates each change, and keeps patches that reduce latency. Once these patches are applied, the system tries again to generate new candidates starting from the new plans. By building on successful optimizations across multiple steps, this evolutionary approach achieves better speedups than simply sampling many plans independently.
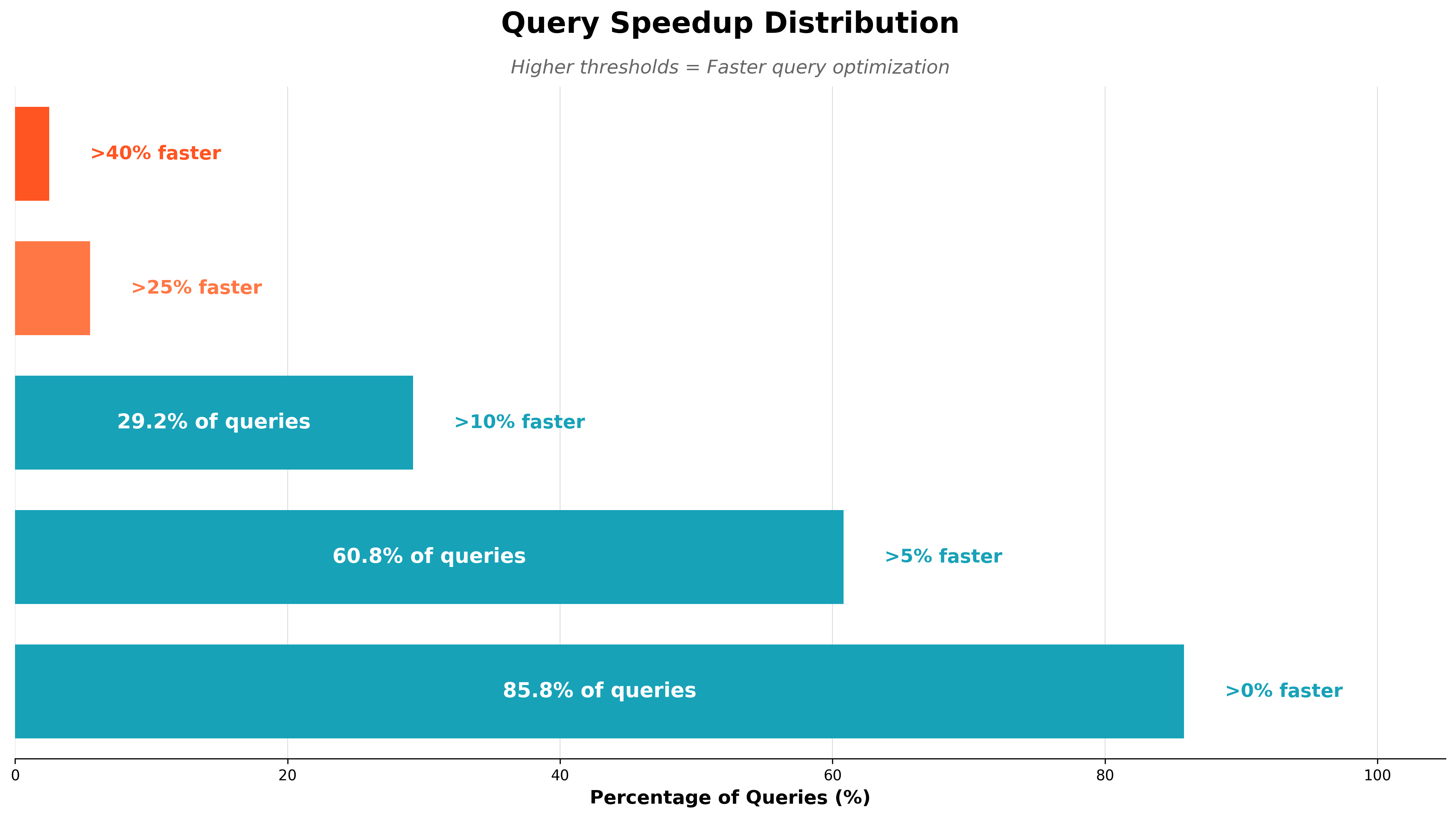
Not all queries can be effectively optimized, as the plans might already be optimal, but we find that in our sampled datasets, 60.8% of those queries could be optimized by more than 5%. The following figure shows the improvements on one of our derived datasets:
Transferring speedups across scale factors
The benchmarks we use expose a scale factor parameter that scales table cardinalities while keeping the underlying schema fixed. In practice, this lets us build a smaller prototype database (e.g., Scale Factor 3, or SF3) and a larger production-like database (e.g., SF10) that share the same structure but differ only in size.
Because exploring many candidate plans on full-scale data is expensive (each step requires executing the query plus paying and waiting for LLM-generated patches), we first discover good optimized plans on SF3 using evolutionary search. For each query, we then transfer the best SF3 plan to SF10 using a deterministic, rule-based script. This script matches scan operators across scales via normalized schema / projection / predicate signatures and rewrites the SF3 optimized plan into a runnable SF10 plan, preserving structural edits such as join reorderings and join-side swaps while enforcing safety checks (e.g., no dangling references, valid DAG topology).
Empirically, every optimized plan we selected at SF3 could be successfully transferred to SF10, and the resulting speedups closely tracked the original ones. This validates a practical “optimize small, deploy large” workflow: run the expensive search once on a compact replica of the workload, then lift the resulting plans to larger production databases with minimal additional engineering effort.
Conclusion
DBPlanBench establishes that LLMs can effectively function as semantic cardinality estimators to correct physical plan errors that statistical heuristics miss. By combining compact plan serialization with evolutionary patch search, the system achieves significant reductions in execution time and memory pressure without requiring changes to the core database engine. The harness and code are released as open-source for further research.
References
Lohman, G. Is query optimization a “solved” problem? ACM SIGMOD Blog, April 2014. URL: https://wp.sigmod.org/?p=1075. Accessed: 2026-01-26.