
Summary
Cartesia builds real-time voice AI systems for enterprise use cases, where latency, streaming stability, and operational reliability directly affect user experience. Running streaming voice models at scale requires an unforgiving infrastructure baseline: ultra-low latency, continuous connection stability, and zero tolerance for dropped audio.
To support these requirements — and serve millions of audio minutes daily — Cartesia uses Together AI. Together provides the GPU compute, networking, storage, and cluster operations, while Cartesia maintains deep cluster-level access to run a custom inference engine optimized for its State Space Model (SSM) architecture. This setup supports Cartesia’s real-time serving requirements, including a reported 90ms model latency for voice generation, and regulated enterprise deployments on PCI-compliant infrastructure.
About Cartesia
Cartesia builds enterprise voice AI products across text-to-speech, speech recognition, and edge deployments. Their focus is real-time, streaming voice, where audio is generated continuously during a live interaction. In that setting, even a few hundred milliseconds of added delay can show up as hesitation, clipping, or dropped audio, so the bar is set by what the stream can sustain.
Cartesia’s team describes voice generation as placing different representational demands on models than text, noting that it requires capturing the “fuzzier” complexity of sentiment, tone, and pacing. They use SSM architectures to meet those constraints and run them through a purpose-built inference engine tuned to their serving path. That choice ties together model design, serving implementation, and the hardware environment, making infrastructure behavior a core part of the performance envelope.
The challenge
Cartesia’s growth in real-time voice AI created four specific infrastructure requirements that many hosted platforms were not fit for.
- Voice workloads have tight latency budgets: Voice applications require fast response times across long-lived, sustained WebSocket connections. Even brief delays or buffering spikes interrupt conversational flow and degrade the product. Cartesia needed infrastructure that could support consistently low latency in streaming voice interactions.
- SSM architectures required custom serving control: Cartesia’s models utilize State Space Model (SSM) architectures, which handle memory and sequence state differently than standard Transformer-based systems, enabling Cartesia to run performant models while maintaining state-of-the-art quality.
However, because most hosted serving paths are heavily optimized for massive Transformer workloads, Cartesia needed to build and run a custom inference engine tailored specifically to its architecture. This required deeper control over the serving environment than a standard hosted endpoint abstraction provides. - Audio training creates unique I/O bottlenecks: Unlike text models that process large sequential files, training audio models requires data loaders to issue millions of small, random reads across short audio clips, alongside heavy multi-gigabyte checkpoint writes. Cartesia needed a cluster topology and parallel file system that could handle this concurrent I/O pressure to avoid GPU underutilization during multi-node runs.
- Enterprise use cases add compliance requirements: As Cartesia expanded into enterprise deployments, customer environments began requiring PCI-compliant infrastructure to handle sensitive voice interactions in financial and payment-related applications. Cartesia needed a deployment path that combined dedicated performance with enterprise-grade compliance controls.
The solution
Cartesia uses Together AI’s GPU clusters for both production voice serving and model training. Together provides the underlying GPU infrastructure, networking, storage, and managed Kubernetes environments.
For production serving, Cartesia runs a custom inference engine on dedicated Together infrastructure. Because SSM-based models require architecture-specific optimizations, Cartesia needs cluster-level access—including SSH and direct file system access—to deploy and tune their serving stack. Together gives Cartesia that kind of deep access and control that would take months to negotiate and configure with a legacy cloud provider. Alongside this access, Together handles the surrounding infrastructure foundation, provisioning the model weight storage and ingress controllers that Cartesia uses to manage concurrent streaming voice traffic.
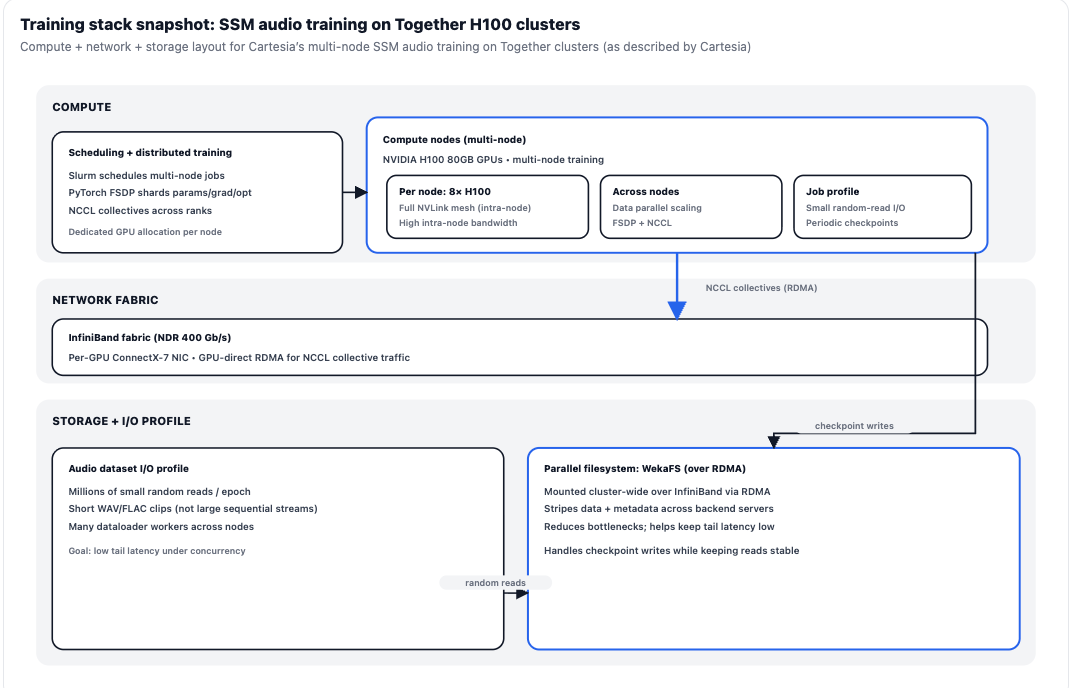
Cartesia also uses Together’s H100 80GB clusters for model training, with multi-node workloads scheduled via Slurm. During cluster bring-up and scaling, Together worked closely with Cartesia on infrastructure setup. By optimizing the WekaFS parallel file system and tuning the InfiniBand networking fabric, Together helped stabilize the environment for Cartesia’s data-heavy training runs.
Audio training presents a distinct I/O profile: rather than streaming large sequential files, Cartesia’s data loaders issue millions of small, random reads per epoch across short WAV and FLAC clips. Because Together and Cartesia mounted WekaFS cluster-wide via RDMA, Cartesia notes the storage layer supports heavy concurrent random-read pressure from hundreds of data-loader workers while also handling periodic multi-gigabyte checkpoint writes with minimal impact on read throughput.
At the network and compute layer, the infrastructure is configured to support GPU-direct RDMA for NCCL collectives. Within each node, GPUs connect over a high-bandwidth NVLink mesh. Across nodes, inter-node training runs over InfiniBand with GPU-direct RDMA. This allows Cartesia to efficiently use PyTorch FSDP (Fully Sharded Data Parallel) to shard optimizer states and gradients across all ranks, maintaining manageable per-GPU memory pressure during massive training runs.
For customer deployments with strict data security requirements, Cartesia utilizes Together's PCI-compliant environments. These environments are configured with data isolation, encryption at rest and in transit, and audit logging to handle sensitive enterprise workloads.
Results
Together’s infrastructure supports Cartesia’s voice AI serving and training requirements across low-latency production workloads and multi-node model development.
Low-latency real-time voice serving
Cartesia reports 90ms model latency for voice generation across the Sonic model family, achieving the fast, consistent response times required for streaming conversational AI.
Custom serving on dedicated infrastructure
Deep cluster-level access enables the team to deploy and tune their custom SSM inference engine, bypassing the limitations of general-purpose hosted serving paths.
High-throughput audio model training
Cartesia uses NVLink for intra-node bandwidth, GPU-direct RDMA over InfiniBand for inter-node collectives, and WekaFS over RDMA to support the random-read I/O profile typical of audio training. This setup supports multi-node H100 training under Slurm with PyTorch FSDP.
Enterprise deployment path for regulated use cases
Together’s PCI-compliant environments support Cartesia deployments for customers with strict compliance requirements, including regulated voice applications in sectors like financial services and payment processing.
Available on the Together Model Library
Developers can build with Cartesia's performant voice models directly on Together AI, including Sonic-3, for reliable inference.
"Because our voice models use state space architectures, we need to run a purpose-built inference engine. Together AI gives us the compute and cluster-level access we need—down to the filesystem and SSH permissions—so we can optimize our serving stack exactly how we want. They manage the heavy lifting of the hardware orchestration and ingress, and we get the low-level control required to hit our streaming latency targets." — Kunal Shah, Head of Platform, Cartesia