200+ generative AI models
Build with open-source and specialized multimodal models for chat, images, code, and more. Migrate from closed models with OpenAI-compatible APIs.



End-to-end platform for the full generative AI lifecycle
Leverage pre-trained models, fine-tune them for your needs, or build custom models from scratch. Whatever your generative AI needs, Together AI offers a seamless continuum of AI compute solutions to support your entire journey.
Inference
The fastest way to build with pretrained AI models:
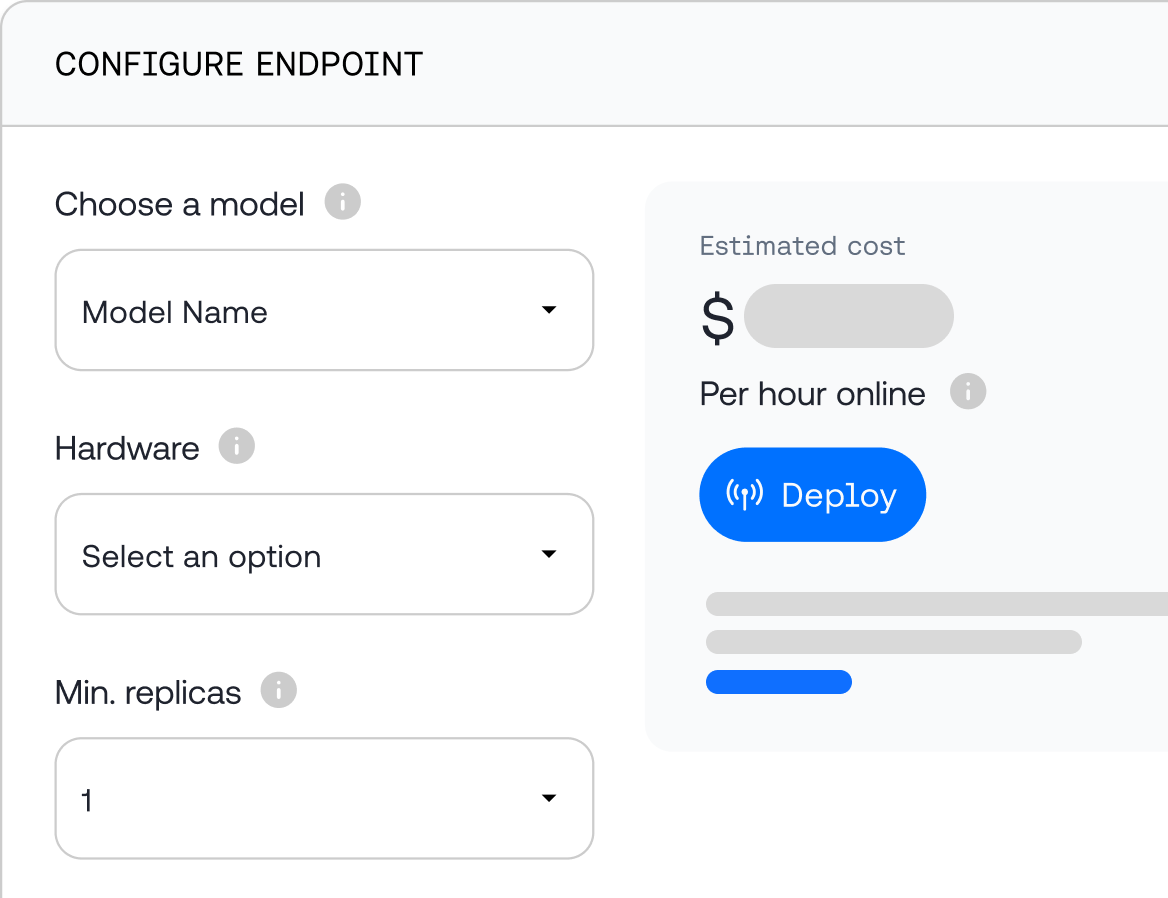
✔ Serverless or dedicated endpoints
✔ Deploy in enterprise VPC
✔ SOC 2 and HIPAA compliant
Fine-Tuning
Tailored customization for your tasks
✔ Complete model ownership
✔ Fully tune or adapt models
✔ Easy-to-use APIs
- Full Fine-Tuning
- LoRA Fine-Tuning
GPU Clusters
Full control for massive AI workloads
✔ Accelerate large model training
✔ GB200, B200, and H100 GPUs
✔ Pricing from $1.75 / hour








Run
models
Train
Models
Speed, cost, and accuracy. Pick all three.
SPEED RELATIVE TO VLLM
LLAMA-3 8B AT FULL PRECISION
COST RELATIVE TO GPT-4o
Why Together Inference
Powered by the Together Inference Engine, combining research-driven innovation with deployment flexibility.
accelerated by cutting edge research
Transformer-optimized kernels: our researchers' custom FP8 inference kernels, 75%+ faster than base PyTorch
Quality-preserving quantization: accelerating inference while maintaining accuracy with advances such as QTIP
Speculative decoding: faster throughput, powered by novel algorithms and draft models trained on RedPajama dataset
Flexibility to choose a model that fits your needs
Turbo: Best performance without losing accuracy
Reference: Full precision, available for 100% accuracy
Lite: Optimized for fast performance at the lowest cost
Available via Dedicated instances and serverless API
Dedicated instances: fast, consistent performance, without rate limits, on your own single-tenant NVIDIA GPUs
Serverless API: quickly switch from closed LLMs to models like Llama, using our OpenAI compatible APIs
Forge the AI frontier. Train on expert-built GPU clusters.
Built by AI researchers for AI innovators, Together GPU Clusters are powered by NVIDIA GB200, H200, and H100 GPUs, along with the Together Kernel Collection — delivering up to 24% faster training operations.
Top-Tier NVIDIA GPUs
NVIDIA's latest GPUs, like GB200, H200, and H100, for peak AI performance, supporting both training and inference.
Accelerated Software Stack
The Together Kernel Collection includes custom CUDA kernels, reducing training times and costs with superior throughput.
High-Speed Interconnects
InfiniBand and NVLink ensure fast communication between GPUs, eliminating bottlenecks and enabling rapid processing of large datasets.
Highly Scalable & Reliable
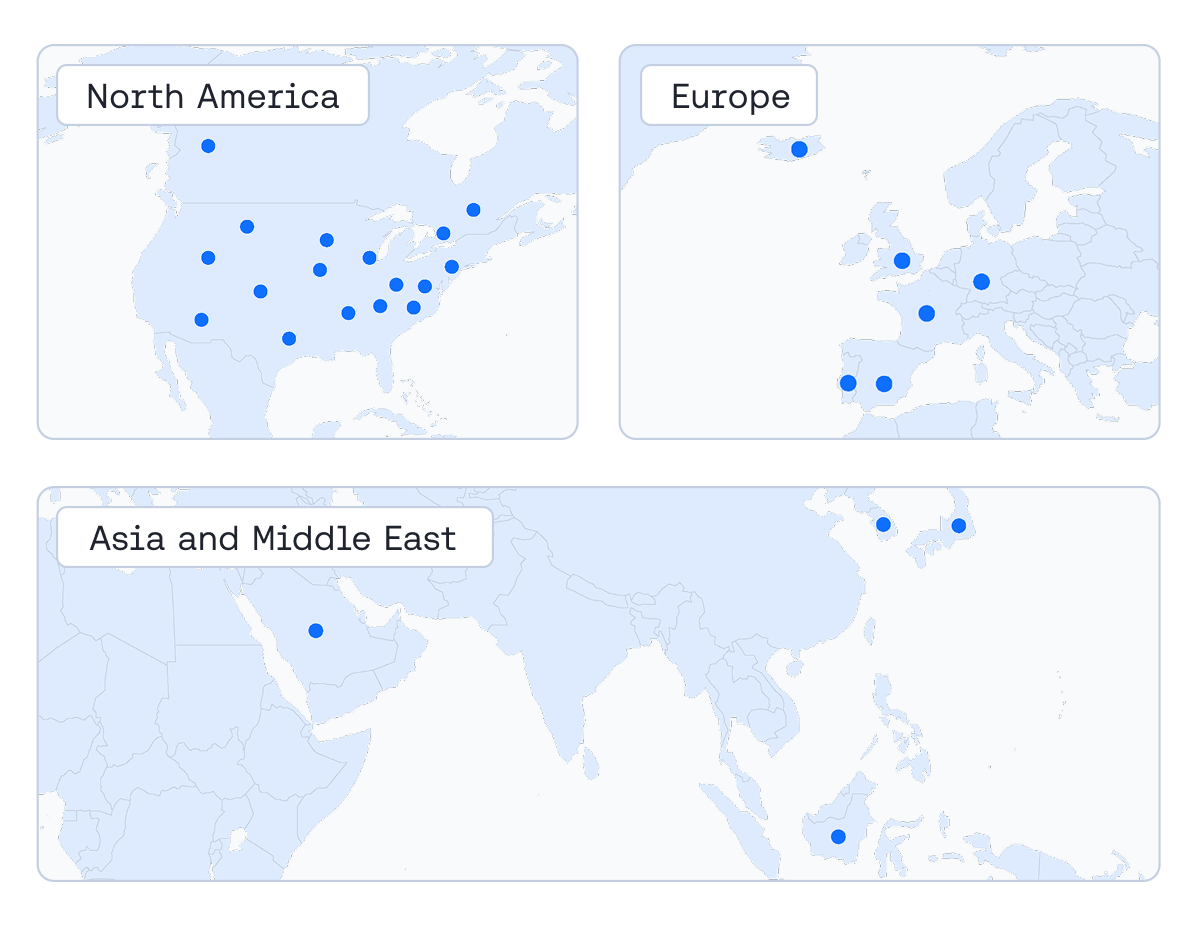
Deploy 16 to 1000+ GPUs across global locations, with 99.9% uptime SLA.
Expert AI Advisory Services
Together AI’s expert team offers consulting for custom model development and scalable training best practices.
Robust Management Tools
Slurm and Kubernetes orchestrate dynamic AI workloads, optimizing training and inference seamlessly.
Training-ready clusters – Blackwell and Hopper
THE AI ACCELERATION CLOUD
BUILT ON LEADING AI RESEARCH.

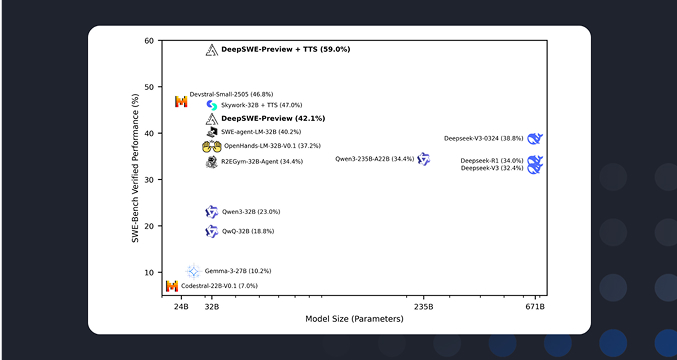
Innovations
Our research team is behind breakthrough AI models, datasets, and optimizations.
Customer Stories
See how we support leading teams around the world. Our customers are creating innovative generative AI applications, faster.






































.webp)